学会了玩街霸Ⅱ的AI,你怕不怕?

大数据文摘作品
编译:元元、Chloe、朱颜夫、亭八
上周,我们带领着团队去参加了三星开发者大会(Samsung Developer Conference, SDC)。众所周知,一个展位会很容易让人变得无聊透顶,人们想要了解一个产品,可以在互联网搜索到各种相关的信息,而传统的免费T恤+产品传单早已过时。在设计SDC展位的时候,我们开始思考如何制作一个有趣的展位,毕竟我们的团队也要在上面呆两天。于是我们做了一件事情:让Gyroscope的AI在超级任天堂(Super Nintendo Entertainment System ,SNES)上征战“街头霸王2:究极格斗”,通过各个角色间的互搏,让Gyroscope学会格斗技巧。
Gyroscope 的AI通常不会用来玩电子游戏,我们也没有超级任天堂的软件开发包(Software development kit,SDK)。所以在SDC大会前,我们想法设法从“街头霸王2:究极格斗”中提取游戏信息,建立Gyroscope的超级任天堂SDK,然后让 Gyroscope的 AI与游戏内置的计算机对手进行数千场游戏比拼,同时我们不断调整AI的参数,让它适应这个特殊的应用程序。为了让现场的气氛活跃起来,我们还为每个角色举行了“四强”单淘汰制比赛,同时让与会者选择他们认为会赢的角色,选对的人可以参加SNES Classic的抽奖活动。
训练AI
首先,我们必须弄清楚我们实际上要解决什么问题。我们把玩街头霸王2的问题抽象为强化学习问题(Gyroscope的AI解决方案支持的问题类型之一)。在强化学习问题中,AI评估各种方案,选择要采取的行动,为此获得回报。这个AI程序的目标是根据过去观察到的行为,采取最佳的行动,来最大化可获得的奖赏。所以在我们开始应用AI之前,我们需要定义“街头霸王2”的观察内容,即人工智能“看到的”是什么,以及行动和奖赏。
观察内容
我们可以将这些想象成AI在环境中“看到”的东西。当人类观察游戏的时候,首先看到的是每个角色,以及角色的跳跃、移动、踢等,同时还能看到角色的血条和计时器。我们需要将这些信息提取出来,转化成AI可以理解的格式,这种格式被称为“观察空间”。在强化学习中,观察空间有两种常见的思路,传统的方法是测量我们人类认为与问题相关的具体信号。现代的方法是为AI提供每次行动后的全部环境图像,让AI决定图像中的重要元素。我们通常认为现代的方法更好,因为它有更好的普适性,不需要对特征的重要性做过多的假设,但是这种方法往往需要更长的训练时间,考虑到时间的限制,我们选择了传统的方法,并手动定义观察空间。
具体而言,我们将观察空间定义为:
• 每个玩家的X和Y坐标
• 每个玩家的血条
• 每个玩家是否在跳跃
• 每个玩家是否蹲伏
• 为每个玩家的动作编号
• 玩家之间X和Y坐标差的绝对值
• 游戏时钟

游戏观察空间示例
另外,这个观察空间是超大的,不重复的观察点达到了万亿甚至更多!
行动
AI观察环境后必须采取行动,最简单的使角色行动的方法是采用超级任天堂手柄上的按钮:上、下、左、右、A、B、X、Y、L、R。然后,单个行动就是一组按钮组合,如果我们考虑所有可能的按钮组合,就会产生1024(2^10)个可能的行动。但这个可能的行动太多了!即便AI最终能学会,也需要训练很长一段时间才能知道哪些行为有效,哪些不行。不过,任何“街头霸王2”的玩家都知道并不是所有的按钮都可以随时按下,而且,许多动作要通过按键顺序达到更好的效果。
基本动作
“街头霸王2:究极格斗”充分利用了CAPCOM摇杆和超级任天堂手柄。下面的示意图包括8种基本控制的位置以及他们在游戏中的用法。

方向控制(来自街头霸王2:究极格斗游戏说明书)
从12点方法顺时针:跳跃,向前翻转,向前,进攻蹲伏,蹲伏,防御蹲伏,防御,向后跳跃。
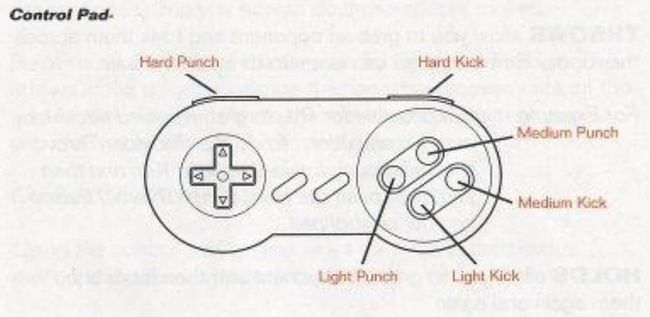
手柄按钮控制(来自街头霸王2:究极格斗游戏说明书)
从左上顺时针:重击,重踢,中等击打,中等踢,轻踢,轻击
考虑行动空间的另一个方向是一组动作,比如高踢、扔、勾拳等, 我们可以让AI选择一个动作,然后把这个动作转换成一组按钮。但确定一个角色的动作需要一段时间,因为我们需要大量的查阅Google,以及自己亲自玩,而且对每个角色都要重复这个过程。所以为了缩短训练时间,我们将动作空间简化为一个按下方向控制和按下一个按钮控制(例如“上+A”或“L”)的组合,同时是否按下都是可选的,这一构建方法使得行动空间缩减成了35个可能的行动。另外还要告诉各位的是,更高级的动作和组合仍然可能随着训练时间的增加而出现,但是这部分留给了AI自行探索。
回报
最后,我们还要去思考:一旦采取行动,AI就会收到回报。当人类玩游戏的时候,会通过血条和伤害的大小,对游戏目前的状况大体上有一个认识。所以AI需要通过一个数字的形式来理解游戏状况,让它们使这个数字最大化从而获得最佳奖励,我们选择了每一帧的血条差距作为回报。所以,在每次观察时,AI都会得到相当于玩家之间血条差距的奖励。例如,如果AI通过踢对手造成对方受到10点伤害,之后的血条差距将会是10点,AI得到同样数量的回报。但如果AI在下次观察后不采取行动,在“无”的情况下仍然得到10点,因为它保持了血条差距。相反的,如果AI被踢并且没有防御下来,则血条差距将会减小。所以这个差值可能也是负的,这表明AI此时的状态不佳。
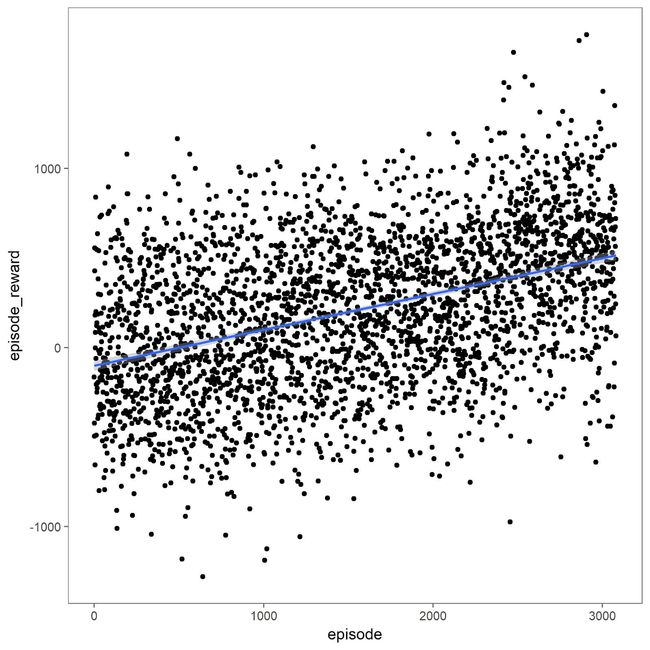
一场街头争霸比赛中Dhalsim(一个游戏角色)得到的回报
创造人工智能的人工智能
以上是我们讨论的最终在比赛中采用问题的构建方法。同时我们也调整了AI系统的参数,因为Gyroscope的自主AI是一个算法的算法,它可以找到每个问题适用的算法。有了这么多关于“街头霸王”问题的信息之后,我们抄了一个近道,选择深度Q网络 (Deep Q-network, DQN)作为强化学习方法,也对DQN进行了一些修改。值得一提的是基于图像观察空间缺失的修改:DQN使用模型来预测哪些行动最佳,而不是用穷举法测试每个可能的行动。毕竟考虑到观察空间的大小,探索每个可能的行动几乎是不可能的。
模拟器连接
在我们训练人工智能之前,我们必须把它连接到街头霸王上。Gyroscope可以通过iOS和Unity的SDK连接。但我们目前还没有超级任天堂的SDK,因此我们需要找到可以帮助我们测试超级任天堂游戏的工具,以便我们可以使用我们的AI技术来玩这些游戏。幸运的是,我们从电脑辅助竞速(Tool-assisted speedrun)社区找到了合适的连接经典游戏机的工具(竞速一族为了尽可能快地赢得各种游戏,他们通常一帧一帧的查找游戏漏洞)。

怎么夸都不够
我们不仅需要模拟器,还需要支持模拟器核心的工具。我们发现了BizHawk,它可以支持多种模拟器核心,包括超级任天堂的核心。
BizHawk可以提供的重要功能:
• 一个Lua语言脚本界面,让我们逐帧控制游戏;
• 一套控制台内存检查工具,以便检查游戏内存(全部或特定地址);
• 运行中可以不受速度限制,也不需要显示,从而最大化游戏的帧率;
• BizHawk源代码。
特别对于“街头霸王”而言,Lua界面允许我们发送手柄按键信号,读取按下按钮信号,读取存储位置以及控制核心模拟器。内存检测器让我们获取对手的血条情况,对手的动作以及其他观察数据。请注意,我们只使用人类玩家知道的信息;我们没有让AI了解人类不知道的任何信息。
老实说,我们怎么夸BizHawk都不够。不仅产品是一流的,源代码也非常整洁,可读,可扩展。我们很高兴与这个代码库合作——后面你就可以看到了,源代码变非常重要。
初次尝试:用Lua写Gyroscope SDK
BizHawk应用程序嵌入了Lua脚本引擎,并对该引擎开放了一些模拟器功能。所以初次尝试我们自然而然地想到用Lua写Gyroscope SDK。我们写了一个Lua库,用于访问所有的内存位置,这些位置随后会被转换为观察结果,还用于向模拟器发送键盘按键。
但是,如何把Lua中的数据放入Gyroscope呢?要知道,Lua接口不支持任何networkI/O!而我们的服务又在云端运行,这是一个大问题。对此我们唯一能用的只有fileI/O和SQLite I/O。
我们写了一些python代码,从Lua写的文件中读取游戏观察结果并将其发送到Gyroscope,但是很难与Lua同步,而且将动作(按按钮)返回到Lua也很奇怪。再者,这一过程特别慢,即便把文件放入RAM磁盘也依然很慢。我们尝试用SQLite来做同样的事,也遇到了同样的问题——速度太慢。
鉴于此,我们决定将SDK代码从Lua转移到本地的BizHawk工具;这些工具是用C#写的,BizHawk全部都是用C#写的。我们保留了之前写的python代码,因为它提供了一个简易的接口与我们的服务(gRPC语言)对接,还保证了AI玩家之间的同步(确保他们在相同的帧,等等)。我们把这些python代码命名为模拟器控制器。
妥了:全部用C#写
BizHawk提供了一个简单的C#界面,利用工具来控制游戏和模拟器的方方面面。我们使用这一接口将Lua代码导入C#,很快有了一个用C#操作街霸的工具。
在C#中我们能够访问所有的.NET库,所以很快通过插口连接到我们的模拟器控制器代码。我们从游戏中的每一帧抓取一个观察结果,将观察结果发送给模拟器控制器,控制器将咨询Gyroscope AI,并向模拟器返回下一帧应该按下的动作(按钮)。
我们现在有了运行街霸II的有效方法,就像在主机上玩一样快,向Gyroscope发送游戏观察结果,返回控制器应按下的按钮动作。我们也有能力同步比赛的AI机器人双方。是时候出来训练了!
综合起来:训练AI

训练初期,AI(图中Dhalsim)随机按下按钮
定义好观察结果、动作、奖励值,再将AI连接到超级任天堂,我们准备好啦。针对内置的游戏机器人来训练我们的AI。每个角色大约训练8小时或者说3000场比赛。
我们的假设是,训练好的AI将:
(1)最大限度地提高奖励值,
(2)可以在训练结束后拥有相当高的胜率。

训练3000场比赛后,Dhalsim积极进取,胜率50%
因为玩街霸是对我们服务创造性的应用,所以我们预设要做一些必要的调整——我们的AI之前不会对上述快速奖励值进行优化,也没有控制过这样大的动作空间。经过了两个特别有意思的周末,我们尝试了观察空间、动作空间、奖励值函数和DQN参数的许多变体,直到得到一个高胜率的AI。
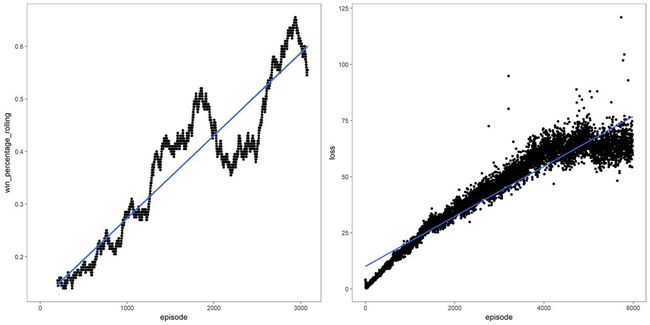
训练期间的胜率和模型损失
除了标准模型调优技术和良好的科学原则(一次只改变一个量),我们还有一个重大发现:方向控制按压与按钮控制按压的权重不同。我们发现方向控制只对一帧有效,在游戏中影响很小;然而,按钮控制一旦按下,作用会维持一系列帧,在游戏中影响重大。比如,完成拳击这一动作需要很多帧。这意味着在一帧内采取的动作会延续很多帧。此外,虽然与方向控制按压相比,按钮按压非常重要,但相应地也需要更加频繁的按压才能起作用。为了完成这一游戏行为,也为了使AI行为更加人性化,我们让AI在20帧(即1/3秒)内一直重复按钮按压,完后再采取下一个动作。在这20帧内奖励值累积。换句话说,我们让AI以1/3秒游戏时间为单位来采取动作、观察结果,不是以每帧为单位。
我们常常被问到,为什么不用“获胜”作为奖励值。简单来说,这样做奖励值是延迟的,会导致训练更困难更耗时。健康差值是合理的探索,我们相信这样会引起获胜——嗯,它做到了。
Gyroscope获胜!

80%胜率;注意AI机智地拦截对方招数,还神奇地走位
刚开始训练的时候,我们的AI随机行动,对战3星级对手(街霸采用星级评价体系)的胜率是20%。所以,20%胜率是底线,超过20%才能说明AI取得了成效。最后, AI对抗游戏内置3星级机器人的胜率达到90%!设置得非常简单,训练时间又短,能取得这样的成绩我们很激动。此外,我们预计训练过程再长点的话还能达到更高的胜率,但可能会对训练用的机器人过拟合。针对比赛,取得80%胜率后我们就停止训练,以避免过拟合。
WindowsBAT脚本最差

一切都很糟
AI获胜后,我们开始用街霸II的每个角色训练它。为了训练每个角色,我们使用Google云端平台支持多个Windows Server 2016实例(在Windows上构建BizHawk效果最佳),然后写了一些.bat脚本进行全部的训练。训练需要通过一些R脚本来自动完成玩家选择、游戏重置、模型记录、进度绘制等功能。我们为BizHawk增加了一些命令行选项,使其更容易自动化。
会场上:战斗吧!

SDC上我们的展位
会场上,我们布置展位来展示四场AI战斗,场场都是两个AI控制的角色对抗。我们还画了比赛树状图——安排展位没展示到的角色参加比赛。
我们摆放了分别贴有每个角色照片的罐子,向观众发放抽奖券。观众将抽奖券放入自己认为会获胜的角色的罐子里;比赛结束后,我们从获胜角色的罐子中抽一张券,这张券的持有人获得一台迷你超级任天堂!我们还展示了训练过程,让观众看到GyroscopeAI的工作原理。
每天下午4:30,我们按树状图进行比赛。先测试一场,再进行正式比赛。
第一天的比赛:M.Bison碾压全场。
四分之一决赛
Guile对战Vega:Guile被吊打。Vega AI很快就学会了缩短距离,弯腰躲闪,刺向对方,用着飘逸的走位,Vega胜出。
Blanka对战M.Bison:M.Bison实力碾压。他的独门攻击几乎无法阻挡,就这样,M.Bison胜出。
Chun-Li对战Sagat:Chun-Li也是近距离作战——她的速度和近地攻击打败了Sagat的长距离袭击和频繁神奇的走位。Chun-Li胜出。
Balrog对战Dhalsim:十分有趣——Dhalsim几乎一直在空中,用他的长腿攻击Balrog。Dhalsim胜出。
半决赛
Vega对战M.Bison:M.Bison的攻击太猛烈了。M.Bison进入决赛。
Chun-Li对战Dhalsim:Dhalsim在空中发起的进攻杀伤力非常大,轻松击败Chun-Li。
决赛
M.Bison对战Dhalsim:基本上M.Bison角色太过强大以至于无可匹敌。M.Bison获胜!
第二天的比赛:E.Honda搅动风云

E.Honda对战Blanka
第二天,我们重新开始比赛,M.Bison从比赛中除名(夜里他因以作弊代码的形式滥用兴奋剂被捕)。我们选择让E.Honda加入,但他在测试时表现很差。
当天有两场战斗格外引人注目:
(1)Vega对抗Sagat,是一场持久战,Vega靠近Sagat时,至少躲过了三次Sagat的神奇走位(两次是拿准时间的弯腰躲闪,一次是跃过火球);
(2)决赛,E.Honda对抗Sagat。决赛E.Honda击败Sagat是一场难以置信的战斗,最后他俩的血量都已经接近0了,这时E.Honda一击制胜。E.Honda这次能赢真的是运气特别好,因为我们之后又重新进行了100场E.Honda对战Sagat的比赛,E.Honda只赢了11场。

Gyroscope创始人(我们)和第二天迷你超级任天堂的获得者
课程推荐
数据科学实训营第4期
报名优惠倒计时第3天!
如果,你正在求职、跳槽、研究,需快速提升实战技能
如果,你渴望大展身手,搏一席之地
如果,你想在数据时代掌握主动权
那么,你需要实训营助你一臂之力!
扫描海报二维码,获取成长机会!

志愿者介绍
回复“志愿者”加入我们



往期精彩文章
点击图片阅读
波士顿动力那只跌倒后可以爬起来的机器人,刚刚完成了两个完美后空翻!


