AI芯片:寒武纪Cambricon-X结构分析
Cambricon-X
Cambricon-X是针对稀疏系数的矩阵计算架构。
深鉴科技的韩松等人的研究发现,可以将传统的深度学习网络模型的许多权重系数去掉,甚至能去掉90%以上,而并不影响模型的计算精度。如下图所示。
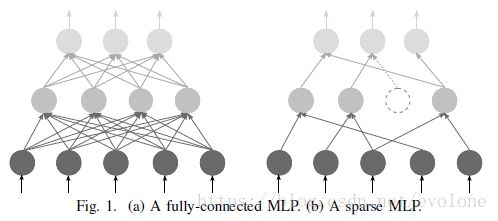
目前的深度学习模型的权重系数太多,造成需要的乘法计算非常多,计算时间长,速度慢。
相信,未来的模型会更加复杂,需要的计算更多,时间更久。
未来把模型进行系数删减,就成了必然。
但是,删减了大量权值系数后,模型网络所需要的乘法计算次数明显变少,但是因为系数的稀疏带有不可控的随机性,不同filter的有效权重可能是不同位置的,所以,这就造成了大量权重并行计算时,无法做到同步,导致目前现有的处理器设计都并不能充分利用系数稀疏带来的加速效果。
Cambricon-X就是寒武纪在这个方面的一个探索。
Cambricon-X架构
下图为Cambricon-X的架构。

可以看出,整个架构还是和DianNao很像。
当然还是有不同的。
最大的不同是,为了利用到稀疏系数带来的加速效果,首先就需要将系数为0的权重所对应的输入数据去掉。这个,由Fig4中的Buffer Controller来实现。
Buffer Controller的具体结构见Fig5,主要由indexing实现数据的筛选。
Indexing从输入神经元数据(input neurons)中挑选出非0权重对应的输入数据,按顺序排列好,然后传输给对应的PE。然后,由PE去执行乘法/加法等操作。
PE结构如下图所示。

可以看到,PE中有个小SB,用于存放有效的权重。
权重的存储方式是,将单个神经元的所有不为0的权重存储在一起,如下图所示。

假设每个地址能存储4个权重。
在图7中,假设只有2个神经元:
神经元0,只有0和4,两个权重参数w00 和 w40,存储在address0。
神经元1,有5个权重参数w11, w21 , w31, w51, w61, 这样一个地址不能完全存储,于是需要2个地址,存储在address1和address2.
权重的稀疏性,造成每个神经元计算时,需要读取权重的次数不相同,比如,神经元0只需要读一次权重memory,神经元1需要读2次权重memory,这种不规律,造成难以大量神经元同步计算,无法直接利用脉动阵列的优势。
Indexing Module
既然权重是无规律稀疏的分布。那么,怎么将权重与对应的输入数据匹配起来呢?
Cambricon引入了Indexing Module(IM)

Cambricon-X的每个PE都配置有一个单独的Indexing Units。
依然采用了输入数据在不同神经元上复用的思想。
按照上方图7的例子,依然是2个神经元,在非稀疏情况下每个神经元计算一个卷积结果需要八个输入数据和8个权重(n0, n1,…,n7,共8个),现在是稀疏的,还是一次读取了8个数据,但是神经元0只需要其中2个数据,神经元1需要其中5个数据。
这就需要一种机制去实现权重与输入数据的对应关系。
Cambricon采用的是用标志位connections[i]表示是否有对应连接关系,如图9所示。
Direct Indexing
直接想到的映射机制是直接映射,每个connections的每个bit对应一个输入数据,如图10所示。

这种方式的优点:简单直接;缺点:当稀疏性较大时,会有许多connections[i]是无效的0,浪费芯片内的空间资源。
为了降低空间浪费的问题,又引入了step indexing。
Step Indexing
顾名思义,只存储非零的connections[i],并存储相邻两个非零的connections[i]的距离step(中间间隔的无效0的个数),然后通过累加step,就能恢复出原始的稀疏阵列。如图11所示。(论文原图中有小错误,如图红色标注所示)

这种方式的优点是:可以节省无效0占据的空间;缺点是:需要额外的计算器去累加step,并且需要耗费一些时间。
不过,由于目前用到的模型的尺寸都很大,比如yolo_v3中的网络就往往是416X416的,如果能去除90%的冗余权重,那么step indexing就能明显减少无效0占据的空间。
Cambricon-X的设计中,经过综合考虑,选择的是step indexing。
总结
到了这里,Cambricon-X的内部结构就很清晰了。
整体来看,结构类似DianNao,只有一列(或一行)计算单元,而不是TPU的那种二维的脉动阵列,输入数据的复用效率就低了不少。
估计Cambricon-X,是按照复用输入数据的思路来控制的。猜测其运算方式是:每次读取一次卷积需要的输入数据,然后将数据传输给当前的所有PE的IM,然后每个IM根据step indexing去计算并匹配权重和输入数据,完成数据的匹配后,统一或者各自自主传输给各自的PE(计算单元,内部是乘法器及加法器等),当所有PE计算完成后,将结果写入NBout(buffer),才能进行下一次的计算.
有个缺点:因为要复用输入数据,所以是按照输入数据来控制计算的,就算有PE提前算完,估计也必须等着别的PE计算完成。所以,一次计算的时长,是计算最慢的那个PE决定的,这就表明,Cambricon-X的频率不会非常高。
不过,如果矩阵非常稀疏,那么Cambricon的优势还是非常明显的。
而且,随着之后模型尺寸越来越大,计算量也越来越大,算力非常紧缺,研究稀疏性矩阵的计算,非常有应用前景,特别是嵌入式终端方面,比如手机。
不管怎么样,Cambricon-X还是一个很不错的探索!!
感谢寒武纪!!