OS虚拟内存管理 - Zircon(ARM64)
前言
虚拟内存是通用计算机处理器中 MMU 单元所带来的特性,这也是能否运行通用操作系统的关键。类似 Cortex-M 系列的嵌入式CPU是没有 MMU 的,so 只能跑一些 RT 微内核。
下文所分析的 Zircon 内核原本是 Google 用在 Android 设备 Bootloader 部分的 LK 内核发展而来,而 LK -> Zircon 的最关键的部分就是加入了虚拟内存管理。
虚拟内存的意义
能够面向普通消费大众的 OS 必然会容纳成千上万个程序在 OS 中欢快运行,怎样为每个程序构建一个安全稳定的内存空间是必须的,同时 OS 也必须想办法保护自己的内存空间,否则外来程序的运行非常容易造成 OS 本身的错误奔溃。
简单的来说,OS 通过虚拟内存将内存空间划分为以下结构,以达到安全隔离的目的。
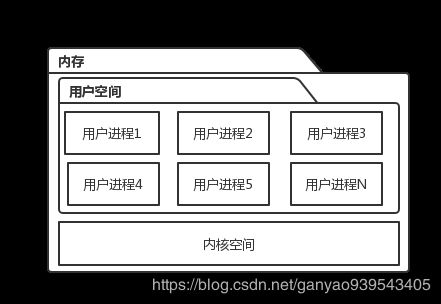
用户空间
用户空间简单的来说就是提供给用户应用程序运行的内存空间,每个应用进程原则上内存空间也是相互隔离的。
他们之间的通讯通过另外一种叫 IPC 的方式进行,一般由内核提供这一中间人的角色,帮助在两个进程空间之间传输数据。
内核空间
在内核中也有很多线程,之所以叫线程而不叫线程,是因为这些内核线程都运行在同一个内核空间内。
一般内核拥有较为高级的权限,能够同时访问用户空间和内核空间
MMU 的意义
如果 CPU 没有 MMU,那么 OS 想实现上面所说的内存结构是不可能的。
简单想一下就知道在编程时,汇编指令并没有限制我们想访问的内存地址范围,理论上我们可以访问并且修改内存的各个区域。
而 MMU 这时候起到了关键性的作用。
无 MMU 的情况
当没有 MMU 的时候,寻址指令可以通过总线直接访问到实际的设备或者内存地址
一路畅通无阻
这里省略缓存

有 MMU
MMU 拦截了 CPU 发出的寻址信号,这时候 CPU 发出的时虚拟地址(VA)。
用软件的思维来说,我们把寻址操作想成 Java 中的 Field Access 操作,那 MMU 就是 Hook 住了所有的 Field Access,然后根据配置的 Hook 逻辑替换成真正的地址(物理地址 PA)
- MMU 先去高速缓存中的 TLB 中查询是否有近期查过的 VA,如果有直接返回对应的 PA
- 如果 TLB 没有命中,则根据 MMU 中寄存器的配置在内存中寻找到根页表
- 解析 VA,从 VA 的一段段中解析出每一级页表的 index,根据 index 一级级查到物理页
- 如果没有查到,则 MMU 产生缺页中断,这里 OS 负责处理中断逻辑,缺页的原因各种各样,有可能时该页确实没有加载到内存中,需要懒加载(linux mmap)。而我们只需要关注的情况是:
- 在缺页中断处理逻辑中,OS 判断该页确实不允许此虚拟内存空间访问/读写,那么则判定为非法内存访问操作,如果是应用程序的话就直接强制退出。
- 最后 PA 到达真正的物理设备
从上述逻辑我们不难看出 MMU 确实可以帮助 OS 在硬件层面实现内存区域的隔离保护。
除此之外,CPU 一般还会提供多个运行等级,OS 内核一般运行在较为高级的等级,而 MMU 则设定为较高等级的运行状态才能进行修改配置。这样就避免了用户程序更改 MMU 从而绕过 OS 内存隔离

Zircon VM 数据结构
ArchVmAspaceInterface
ArchVmAspaceInterface 是个接口,描述了各个平台下虚拟内存管理需要实现的重要接口。主要需要根据各个平台的 MMU 独立实现。
而下面我们要介绍的就是 ARM64 平台的实现。
class ArchVmAspaceInterface {
public:
virtual ~ArchVmAspaceInterface() {}
virtual zx_status_t Init(vaddr_t base, size_t size, uint mmu_flags) = 0;
virtual zx_status_t Destroy() = 0;
// main methods
// Map a physically contiguous region into the virtual address space
virtual zx_status_t MapContiguous(vaddr_t vaddr, paddr_t paddr, size_t count,
uint mmu_flags, size_t* mapped) = 0;
// Map the given array of pages into the virtual address space starting at
// |vaddr|, in the order they appear in |phys|.
// If any address in the range [vaddr, vaddr + count * PAGE_SIZE) is already
// mapped when this is called, this returns ZX_ERR_ALREADY_EXISTS.
virtual zx_status_t Map(vaddr_t vaddr, paddr_t* phys, size_t count,
uint mmu_flags, size_t* mapped) = 0;
// Unmap the given virtual address range
virtual zx_status_t Unmap(vaddr_t vaddr, size_t count, size_t* unmapped) = 0;
// Change the page protections on the given virtual address range
virtual zx_status_t Protect(vaddr_t vaddr, size_t count, uint mmu_flags) = 0;
virtual zx_status_t Query(vaddr_t vaddr, paddr_t* paddr, uint* mmu_flags) = 0;
virtual vaddr_t PickSpot(vaddr_t base, uint prev_region_mmu_flags,
vaddr_t end, uint next_region_mmu_flags,
vaddr_t align, size_t size, uint mmu_flags) = 0;
// Physical address of the backing data structure used for translation.
//
// This should be treated as an opaque value outside of
// architecture-specific components.
virtual paddr_t arch_table_phys() const = 0;
};
VmObject
简称 VMO,Zircon 虚拟内存基础对象,描述一块数据,一片内存
VmObject 可以被映射到其他虚拟内存空间(VmAddressRegion::CreateVmMapping)
VMO 是 Zircon 共享内存机制的基本数据单元
VmObject 继承自 DoublyLinkedListable,很明显是个循环链表。
并且是个树形结构
// list of every child
fbl::DoublyLinkedList<VmObject*> children_list_ TA_GUARDED(lock_);
// parent pointer (may be null)
fbl::RefPtr<VmObject> parent_ TA_GUARDED(lock_);
VMO 有两个子类
- VmObjectPaged:代表 VMO 虚拟内存页的实现
- VmObjectPhysical:代表 VMO 物理内存的实现
也就是说 VMO 既可以是一页或者多页虚拟内存
也可以是一段物理内存
VmAddressRegion::CreateVmMapping
上面说了可以通过 VmAddressRegion::CreateVmMapping 将一个 VMO 映射到其他的地址。
- 如果是 specific 的,则修改已有的页表
- 否则寻找一块新的虚拟内存区域 map
if (is_specific) {
new_base = base_ + offset;
if (!IS_PAGE_ALIGNED(new_base)) {
return ZX_ERR_INVALID_ARGS;
}
if (align_pow2 > 0 && (new_base & ((1ULL << align_pow2) - 1))) {
return ZX_ERR_INVALID_ARGS;
}
if (!IsRangeAvailableLocked(new_base, size)) {
if (is_specific_overwrite) {
return OverwriteVmMapping(new_base, size, vmar_flags,
vmo, vmo_offset, arch_mmu_flags, out);
}
return ZX_ERR_NO_MEMORY;
}
} else {
// If we're not mapping to a specific place, search for an opening.
zx_status_t status = AllocSpotLocked(size, align_pow2, arch_mmu_flags, &new_base);
if (status != ZX_OK) {
return status;
}
}
VmAspace
VmAspace(Virtual Memory Address Space),虚拟内存地址空间,在 Zircon 中使用这个类描述一块虚拟内存寻址空间。
VmAspace 继承自 DoublyLinkedListable,是个循环链表。
class VmAspace : public fbl::DoublyLinkedListable<VmAspace*>, public fbl::RefCounted<VmAspace> {}
vm_page
结构体,描述虚拟内存的基本单位:内存页
kstack
Kernel Stack,内核栈,就是每个内核线程都要有的栈
这是个结构体并不是类,原因是他需要直接嵌入到 thread 结构体中,而不是作为一个指针。
VmAddressRegion/VmMapping
虚拟内存地址区域,描述了一块连续的虚拟内存地址空间,被上边 VmAspace 所包含, 也就是说一块 VmAspace 包含多片 VmAddressRegion。
VmAddressRegion 有 “Alive” 和 “Dead” 两种状态,当 “Alive” 时,VmAddressRegion 代表着一块已经被映射的虚拟内存,而 “Dead” 的时候则无任何意义。
ARM64 的实现
以上我们简单介绍了 Zircon 虚拟内存管理的架构,下面就分析 Zircon 在 Arm64 平台上的实现。
ARM64 页表构建
页表寄存器
- ttbr0_el1 el0(用户态) 异常等级的顶级页表地址
- ttbr1_el1 el1(内核态) 异常等级的顶级页表地址
VA(虚拟内存地址) 格式
ARM64 支持 4K, 16K,64K 三种大小的虚拟内存页大小
而在 Zircon 中,无论是内核空间,还是用户空间,都默认使用 4K 内存页
#define MMU_KERNEL_PAGE_SIZE_SHIFT (PAGE_SIZE_SHIFT)
#define MMU_USER_PAGE_SIZE_SHIFT (USER_PAGE_SIZE_SHIFT)
#ifdef ARM64_LARGE_PAGESIZE_64K
#define PAGE_SIZE_SHIFT (SHIFT_64K)
#elif ARM64_LARGE_PAGESIZE_16K
#define PAGE_SIZE_SHIFT (SHIFT_16K)
#else
#define PAGE_SIZE_SHIFT (SHIFT_4K)
#endif
#define USER_PAGE_SIZE_SHIFT SHIFT_4K
- 在 4K 页大小下,ARM 使用 4 级页表
- 每张页表的大小与页大小一致,那么每张页表有 4K / 8 = 512 = 2^9 项页表项
- 页内偏移 4K = 2^12
- 那么虚拟地址 VA 总共需要 4 * 9 + 12 = 48 bit 描述,可以管理 2^48 = 512TB 的内存空间
- 64 - 48 = 16 位则作为页表基地址,由页属性 - ASID - block/page 构成
如此 ARM64 在 4K 页大小下 VA 的格式为:
高位 —> 低位
| 页表基地址 | L0 页表 index | L1 页表 index | L2 页表 index | L3 内存页 index | 页内偏移 |
|---|---|---|---|---|---|
| 16 | 9 | 9 | 9 | 9 | 12 |
以 Boot 阶段的页表为例
该阶段的任务是为启动阶段 Zircon 内核构建页表。
boot-mmu.cpp -> arm64_boot_map()
首先在 boot 的汇编阶段,页表地址寄存器已经被指向了顶级页表的地址:
msr ttbr0_el1, page_table0
msr ttbr1_el1, page_table1
页表实际为树型结构
4级页表则为 4 层树结构,每个叶子有 512 个子节点
总共有 2^0 + 2^9 + 2^18 + 2^27 张页表
2^36 个内存页
2^48 bit 内存
注意:以上数量为最大数量,实际如果没有用到相应的地址则不会构建对应的页表
那么构建页表的过程,其实就是自顶向下构建树的过程
如果 L0 页表基地址为 kernel_table0 想把一块长为 len(页大小的倍数) 的内存,从 paddr 映射到 vaddr 则需要经历以下过程:
- 从 vaddr 中取出 L0 的 index,到 L0(kernel_table0) 页表查对应的 L1 页表的地址
- 如果为空则分配一块物理内存存放对应的 L1 页表,L0[index] = &L1
- 以相同逻辑处理 L1 的 index
- 以相同逻辑处理 L2 的 index
- L3 为最后一级页表,L3[index] 指向的是内存页的基地址,以 0 填充这块内存。
- 最后循环到下一个 4K 页重复上述操作,直到 len 都被映射完毕
代码:
// 构建页表
// inner mapping routine passed two helper routines
__NO_SAFESTACK
static inline zx_status_t _arm64_boot_map(pte_t* kernel_table0,
const vaddr_t vaddr,
const paddr_t paddr,
const size_t len,
const pte_t flags,
paddr_t (*alloc_func)(),
pte_t* phys_to_virt(paddr_t)) {
// loop through the virtual range and map each physical page, using the largest
// page size supported. Allocates necessar page tables along the way.
//1. 填充该页虚拟内存所对应的顶级页表(L0)
size_t off = 0;
while (off < len) {
// make sure the level 1 pointer is valid
// L0 页表的 index
size_t index0 = vaddr_to_l0_index(vaddr + off);
pte_t* kernel_table1 = nullptr;
switch (kernel_table0[index0] & MMU_PTE_DESCRIPTOR_MASK) {
default: { // invalid/unused entry
// entry 还不是页表项
// 分配一页物理内存,返回地址
paddr_t pa = alloc_func();
// 填充
kernel_table0[index0] = (pa & MMU_PTE_OUTPUT_ADDR_MASK) |
MMU_PTE_L012_DESCRIPTOR_TABLE;
__FALLTHROUGH;
}
case MMU_PTE_L012_DESCRIPTOR_TABLE:
kernel_table1 = phys_to_virt(kernel_table0[index0] & MMU_PTE_OUTPUT_ADDR_MASK);
break;
case MMU_PTE_L012_DESCRIPTOR_BLOCK:
// not legal to have a block pointer at this level
return ZX_ERR_BAD_STATE;
}
//2. 填充该页虚拟内存所对应的 L1 页表
// make sure the level 2 pointer is valid
size_t index1 = vaddr_to_l1_index(vaddr + off);
pte_t* kernel_table2 = nullptr;
switch (kernel_table1[index1] & MMU_PTE_DESCRIPTOR_MASK) {
default: { // invalid/unused entry
// a large page at this level is 1GB long, see if we can make one here
// 大页使用 block 而不是 page
if ((((vaddr + off) & l1_large_page_size_mask) == 0) &&
(((paddr + off) & l1_large_page_size_mask) == 0) &&
(len - off) >= l1_large_page_size) {
// set up a 1GB page here
kernel_table1[index1] = ((paddr + off) & ~l1_large_page_size_mask) |
flags | MMU_PTE_L012_DESCRIPTOR_BLOCK;
off += l1_large_page_size;
continue;
}
paddr_t pa = alloc_func();
kernel_table1[index1] = (pa & MMU_PTE_OUTPUT_ADDR_MASK) |
MMU_PTE_L012_DESCRIPTOR_TABLE;
__FALLTHROUGH;
}
case MMU_PTE_L012_DESCRIPTOR_TABLE:
kernel_table2 = phys_to_virt(kernel_table1[index1] & MMU_PTE_OUTPUT_ADDR_MASK);
break;
case MMU_PTE_L012_DESCRIPTOR_BLOCK:
// not legal to have a block pointer at this level
return ZX_ERR_BAD_STATE;
}
//3. 填充该页虚拟内存所对应的 L2 页表
// make sure the level 3 pointer is valid
size_t index2 = vaddr_to_l2_index(vaddr + off);
pte_t* kernel_table3 = nullptr;
switch (kernel_table2[index2] & MMU_PTE_DESCRIPTOR_MASK) {
default: { // invalid/unused entry
// a large page at this level is 2MB long, see if we can make one here
if ((((vaddr + off) & l2_large_page_size_mask) == 0) &&
(((paddr + off) & l2_large_page_size_mask) == 0) &&
(len - off) >= l2_large_page_size) {
// set up a 2MB page here
kernel_table2[index2] = ((paddr + off) & ~l2_large_page_size_mask) |
flags | MMU_PTE_L012_DESCRIPTOR_BLOCK;
off += l2_large_page_size;
continue;
}
paddr_t pa = alloc_func();
kernel_table2[index2] = (pa & MMU_PTE_OUTPUT_ADDR_MASK) |
MMU_PTE_L012_DESCRIPTOR_TABLE;
__FALLTHROUGH;
}
case MMU_PTE_L012_DESCRIPTOR_TABLE:
kernel_table3 = phys_to_virt(kernel_table2[index2] & MMU_PTE_OUTPUT_ADDR_MASK);
break;
case MMU_PTE_L012_DESCRIPTOR_BLOCK:
// not legal to have a block pointer at this level
return ZX_ERR_BAD_STATE;
}
//3. 填充该页虚拟内存所对应的 L3 页表
// generate a standard page mapping
size_t index3 = vaddr_to_l3_index(vaddr + off);
kernel_table3[index3] = ((paddr + off) & MMU_PTE_OUTPUT_ADDR_MASK) | flags | MMU_PTE_L3_DESCRIPTOR_PAGE;
off += PAGE_SIZE;
}
return ZX_OK;
}
Boot 完毕后的页表映射
Boot 完毕后与 Boot 中的页表映射区别在于:
- Boot 中只需要映射内核空间,而 Boot 完成后也需要映射用户空间
- Boot 中的页表固定为 4K 页大小,而 Boot 后的可以为 16K 甚至 64K 大小
- 所以更具具体为几级页表需要微调代码
具体体现为:由原来的 L0 -> L1 -> L2 ->L3 固定顺序构建的逻辑,改为动态递归构建
1.首先要算出特定页大小的 index 在 VA 中的长度:
- 因为页表大小始终 = 页大小
- 页表项大小 = 64bit = 8byte
- 那么页表项 = 页表大小/8 个 = 2^page_shift / 2^3
- 页表 index 的长度为 page_shift - 3
- 页内偏移长度 = page_shift
2.然后要解决的是计算出在特定页大小某一等级页表的 index 在 VA 中的偏移
MMU_LX_X(page_shift, level)
max_level * (page_shift - 3) + page_shift = 64
page_shift + (max_level - level) * (page_shift - 3) = MMU_LX_X
上边 2式 - 1式 : MMU_LX_X(page_shift, level) = ((4 - (level)) * ((page_shift) - 3) + 3)
// 定义各个level的地址bit偏移
// 2^page_shift = 单页大小, page_shift 也代表着虚拟地址中页内偏移所占 bit 数
// level 则是页表的等级
// 那么这段宏的含义就是,对应等级的页表在虚拟地址中的偏移
// 比如当页大小等于 4K,顶级页表 L0
// page_shift = 12 level = 0
// 虚拟地址 bit 分布如下
// 页表基地址 L0 L1 L2 L3 页内Offset
// 16 9 9 9 9 12
// L0 偏移则是 39, 39 - 48 bit
#define MMU_LX_X(page_shift, level) ((4 - (level)) * ((page_shift) - 3) + 3)
3.构建步骤变更为:
假设先在将
vaddr -> paddr
页大小 = 2^page_shift
index_shift 为当前等级页表在 VA 中的偏移
-
取出当前(假设0) level 的 index
1.vaddr 高 16 位抹 0 = vaddr_rel,用 vaddr - kernal_base,kernel_base 是 kernel 的基地址,因为整个内存空间是一张页表,所以 VA 的高 16 位必然相同
VA =页表基地址- L0 index - L1 index - LN index - 页内偏移
2.然后 index = vaddr_rel >> index_shift
VA =页表基地址- L0 index -L1 index - LN index - 页内偏移
最后剩下 L0 index -
算出页内偏移
1.vaddr 高 16 位抹 0,用 vaddr - kernal_base,kernel_base 是 kernel 的基地址,因为整个内存空间是一张页表,所以 VA 的高 16 位必然相同
VA =页表基地址- L0 index - L1 index - LN index - 页内偏移
2.当前等级页表所能管理的内存块大小 block_size = 1 << index_shift;
3.vaddr 当前 index_shift - 64 位抹 0 = vaddr_rem,通过 vaddr & (block_size - 1)
VA =页表基地址-L0 index- L1 index - LN index - 页内偏移
4.block_size - vaddr_rem = 页内偏移,还需要和剩下需要映射的内存大小 size 比一下大小 MIN(size, block_size - vaddr_rem);
VA =页表基地址-L0 index-L1 index - LN index -页内偏移 -
判断是否是最后一级页表,是则根据传入的页表属性填充最后一级页表项目,否则递归执行,下一级页表 index 偏移 = index_shift - (page_size_shift - 3)
代码:
// map 一页
// NOTE: caller must DSB afterwards to ensure TLB entries are flushed
ssize_t ArmArchVmAspace::MapPageTable(vaddr_t vaddr_in, vaddr_t vaddr_rel_in,
paddr_t paddr_in, size_t size_in,
pte_t attrs, uint index_shift,
uint page_size_shift,
volatile pte_t* page_table) {
ssize_t ret;
volatile pte_t* next_page_table;
vaddr_t index;
vaddr_t vaddr = vaddr_in;
vaddr_t vaddr_rel = vaddr_rel_in;
paddr_t paddr = paddr_in;
size_t size = size_in;
size_t chunk_size;
vaddr_t vaddr_rem;
vaddr_t block_size;
vaddr_t block_mask;
pte_t pte;
size_t mapped_size;
LTRACEF("vaddr %#" PRIxPTR ", vaddr_rel %#" PRIxPTR ", paddr %#" PRIxPTR
", size %#zx, attrs %#" PRIx64
", index shift %u, page_size_shift %u, page_table %p\n",
vaddr, vaddr_rel, paddr, size, attrs,
index_shift, page_size_shift, page_table);
if ((vaddr_rel | paddr | size) & ((1UL << page_size_shift) - 1)) {
TRACEF("not page aligned\n");
return ZX_ERR_INVALID_ARGS;
}
// 初始 index_shift = L0 的 shift = 39
// vaddr_rel = vaddr 消去高 16 bit
// size = 页大小
mapped_size = 0;
while (size) {
//以第一次循环为例,下次循环以此类推
//所能管理的内存块大小
//初始值 2^39
block_size = 1UL << index_shift;
//2^39 - 1 = 000000000000111111111111111
block_mask = block_size - 1;
//消去 39 - 47 bit,现在 vaddr_rem 只有 0 - 38 bit的值了
vaddr_rem = vaddr_rel & block_mask;
//block_size - vaddr_rem = 对于 size 大小的内偏移 = 页内偏移
chunk_size = MIN(size, block_size - vaddr_rem);
//现在循环的等级页表的 index(9 bit),现在是 L0,即 39 - 47 bit 的值
index = vaddr_rel >> index_shift;
//发现这个不是最后一级页表
if (((vaddr_rel | paddr) & block_mask) ||
(chunk_size != block_size) ||
(index_shift > MMU_PTE_DESCRIPTOR_BLOCK_MAX_SHIFT)) {
//从这一级页表中查询 index,得到下一级页表
next_page_table = GetPageTable(index, page_size_shift, page_table);
if (!next_page_table)
goto err;
//如果还有下一级页面表,则递归 Map
ret = MapPageTable(vaddr, vaddr_rem, paddr, chunk_size, attrs,
index_shift - (page_size_shift - 3),
page_size_shift, next_page_table);
if (ret < 0)
goto err;
} else {
// 最后一级页表对应的页表项
pte = page_table[index];
if (pte) {
TRACEF("page table entry already in use, index %#" PRIxPTR ", %#" PRIx64 "\n",
index, pte);
goto err;
}
//设置页表项为要 map 的物理地址
pte = paddr | attrs;
if (index_shift > page_size_shift)
pte |= MMU_PTE_L012_DESCRIPTOR_BLOCK;
else
pte |= MMU_PTE_L3_DESCRIPTOR_PAGE;
if (!(flags_ & ARCH_ASPACE_FLAG_GUEST))
pte |= MMU_PTE_ATTR_NON_GLOBAL;
LTRACEF("pte %p[%#" PRIxPTR "] = %#" PRIx64 "\n",
page_table, index, pte);
//再次填充到页表
page_table[index] = pte;
}
vaddr += chunk_size;
vaddr_rel += chunk_size;
paddr += chunk_size;
size -= chunk_size;
mapped_size += chunk_size;
}
return mapped_size;
err:
UnmapPageTable(vaddr_in, vaddr_rel_in, size_in - size, index_shift,
page_size_shift, page_table);
return ZX_ERR_INTERNAL;
}
由虚拟地址得到物理地址
这个方法等于是模拟了 MMU 的工作:
逻辑与上面类似,就不重复了
简单来说也是去每一级页表 index -> 由 index 一级一级查找下一个页表,最后找到目标内存页面
PA = 目标页基地址 + 页内偏移
// 由虚拟地址查询物理地址
zx_status_t ArmArchVmAspace::Query(vaddr_t vaddr, paddr_t* paddr, uint* mmu_flags) {
fbl::AutoLock a(&lock_);
return QueryLocked(vaddr, paddr, mmu_flags);
}
// 模拟 MMU 工作
zx_status_t ArmArchVmAspace::QueryLocked(vaddr_t vaddr, paddr_t* paddr, uint* mmu_flags) {
ulong index;
uint index_shift;
uint page_size_shift;
pte_t pte;
pte_t pte_addr;
uint descriptor_type;
volatile pte_t* page_table;
vaddr_t vaddr_rem;
canary_.Assert();
LTRACEF("aspace %p, vaddr 0x%lx\n", this, vaddr);
DEBUG_ASSERT(tt_virt_);
DEBUG_ASSERT(IsValidVaddr(vaddr));
if (!IsValidVaddr(vaddr))
return ZX_ERR_OUT_OF_RANGE;
// Compute shift values based on if this address space is for kernel or user space.
// 从 vaddr 中截取 L0 页表的 index
if (flags_ & ARCH_ASPACE_FLAG_KERNEL) {
// 如果是虚拟地址是内核页
// L0 index 在虚拟地址中的 bit 偏移*
// 等于 39
index_shift = MMU_KERNEL_TOP_SHIFT;
// 页内偏移 在虚拟地址中的位置
// 等于 12
page_size_shift = MMU_KERNEL_PAGE_SIZE_SHIFT;
// kernel base 虚拟地址
vaddr_t kernel_base = ~0UL << MMU_KERNEL_SIZE_SHIFT;
// 消去虚拟地址高 16bit
vaddr_rem = vaddr - kernel_base;
// 获得 L0 的 index(9bit)
index = vaddr_rem >> index_shift;
ASSERT(index < MMU_KERNEL_PAGE_TABLE_ENTRIES_TOP);
} else if (flags_ & ARCH_ASPACE_FLAG_GUEST) {
index_shift = MMU_GUEST_TOP_SHIFT;
page_size_shift = MMU_GUEST_PAGE_SIZE_SHIFT;
vaddr_rem = vaddr;
index = vaddr_rem >> index_shift;
ASSERT(index < MMU_GUEST_PAGE_TABLE_ENTRIES_TOP);
} else {
index_shift = MMU_USER_TOP_SHIFT;
page_size_shift = MMU_USER_PAGE_SIZE_SHIFT;
vaddr_rem = vaddr;
index = vaddr_rem >> index_shift;
ASSERT(index < MMU_USER_PAGE_TABLE_ENTRIES_TOP);
}
page_table = tt_virt_;
while (true) {
// L0 的 index(9bit)
index = vaddr_rem >> index_shift;
// 消去 L0 的那 9bit
// 到现在整个 vaddr 64bit 只剩下 L1-L2-L3-页内偏移
vaddr_rem -= (vaddr_t)index << index_shift;
// 从 L0 页表中查询 L1 的地址
pte = page_table[index];
descriptor_type = pte & MMU_PTE_DESCRIPTOR_MASK;
pte_addr = pte & MMU_PTE_OUTPUT_ADDR_MASK;
LTRACEF("va %#" PRIxPTR ", index %lu, index_shift %u, rem %#" PRIxPTR
", pte %#" PRIx64 "\n",
vaddr, index, index_shift, vaddr_rem, pte);
if (descriptor_type == MMU_PTE_DESCRIPTOR_INVALID)
return ZX_ERR_NOT_FOUND;
//已经循环到业内偏移的低 12 bit,则可以退出循环了,paddr 已经组装完毕!
if (descriptor_type == ((index_shift > page_size_shift) ? MMU_PTE_L012_DESCRIPTOR_BLOCK : MMU_PTE_L3_DESCRIPTOR_PAGE)) {
break;
}
if (index_shift <= page_size_shift ||
descriptor_type != MMU_PTE_L012_DESCRIPTOR_TABLE) {
PANIC_UNIMPLEMENTED;
}
// 取下一个等级的页表
page_table = static_cast<volatile pte_t*>(paddr_to_physmap(pte_addr));
index_shift -= page_size_shift - 3;
}
//最后出来 vaddr_rem 仅有 vaddr 的低 12 bit 的页内偏移
//还有对应的最后一级 L3 页表的 pte
if (paddr)
//则物理地址 = pte 内容(目标页基地址) + 页内偏移
*paddr = pte_addr + vaddr_rem;
//如果需要查 mmu flag 的话,填充 flag 返回
if (mmu_flags) {
*mmu_flags = 0;
if (flags_ & ARCH_ASPACE_FLAG_GUEST) {
s2_pte_attr_to_mmu_flags(pte, mmu_flags);
} else {
s1_pte_attr_to_mmu_flags(pte, mmu_flags);
}
}
LTRACEF("va 0x%lx, paddr 0x%lx, flags 0x%x\n",
vaddr, paddr ? *paddr : ~0UL, mmu_flags ? *mmu_flags : ~0U);
return 0;
}
页表切换/切换虚拟内存空间
当我们在不同的进程中切换时,需要为每个进程切换不同的进程空间。
切换虚拟内存空间的实现
Zircon 会为每个用户进程创建独立的虚拟内存空间,也就是说会为每个进程创建单独的页表。
当切换内存空间时,只需要重新对 MMU 的页表寄存器赋值就可以了,修改为当前进程空间的 L0 页表地址。
// 重写页表地址
ARM64_WRITE_SYSREG(ttbr0_el1, ttbr);
切换所带来的性能问题
从本文开始可以知道,MMU 会将近期查到的页地址存储在 Cache 中,叫做 TLB 的东西。下一次查询就可以先查 TLB 以加快寻址速度,不然但的话一次寻址 MMU 将多次访问内存。
当 CPU 运行的代码从用户进程 A 切换到用户进程 B 时,由于 A 和 B 的进程地址空间一般是不一样的,所以当前的 TLB 对于 B 进程完全没有意义,而且可能导致 B 错误的访问到 A 的进程空间。
所以,我们就需要将用户空间的 TLB 完全清空,而这样一来,当 CPU 再次切换到进程 A 时,MMU 就需要重新从内存中查页表,内存压力将越来越大。。。
ASID
幸好 ARM64 想到了这一点,还记得 VA 的高 16 位么?其中就承载了一个叫 ASID 的信息,每条 VA 都会携带上对应进程的 ASID,这样的话 MMU 就有能力区别 TLB 中的 VA 是哪个进程的。
这样的话,进程切换将完全没有必要 Flush TLB,而是让 Cache 自然淘汰。
当然,当进程死亡的时候,还是可以主动 Flush TLB 的,而且因为 ASID,CPU 也有能力单独抹掉某个进程空间的 TLB。
ttbr = ((uint64_t)aspace->asid_ << 48) | aspace->tt_phys_;
// 重写页表地址
ARM64_WRITE_SYSREG(ttbr0_el1, ttbr);
Zircon 切换实现
// 切换内存地址空间,即切换页表
void ArmArchVmAspace::ContextSwitch(ArmArchVmAspace* old_aspace, ArmArchVmAspace* aspace) {
if (TRACE_CONTEXT_SWITCH)
TRACEF("aspace %p\n", aspace);
uint64_t tcr;
uint64_t ttbr;
if (aspace) {
aspace->canary_.Assert();
DEBUG_ASSERT((aspace->flags_ & (ARCH_ASPACE_FLAG_KERNEL | ARCH_ASPACE_FLAG_GUEST)) == 0);
tcr = MMU_TCR_FLAGS_USER;
ttbr = ((uint64_t)aspace->asid_ << 48) | aspace->tt_phys_;
// 重写页表地址
ARM64_WRITE_SYSREG(ttbr0_el1, ttbr);
if (TRACE_CONTEXT_SWITCH)
TRACEF("ttbr %#" PRIx64 ", tcr %#" PRIx64 "\n", ttbr, tcr);
} else {
tcr = MMU_TCR_FLAGS_KERNEL;
if (TRACE_CONTEXT_SWITCH)
TRACEF("tcr %#" PRIx64 "\n", tcr);
}
ARM64_WRITE_SYSREG(tcr_el1, tcr);
}
销毁虚拟内存空间
- 通知物理内存管理器 PMM 释放对应的物理内存空间
- Flush 对应的 TLB
- 需要 Flush 所有 CPU 中对应的 TLB
- ARM64 可以用 tlbi 指令实现
- X86 则需要使用核间中断通知每个 CPU 自行操作
zx_status_t ArmArchVmAspace::Destroy() {
canary_.Assert();
LTRACEF("aspace %p\n", this);
fbl::AutoLock a(&lock_);
DEBUG_ASSERT((flags_ & ARCH_ASPACE_FLAG_KERNEL) == 0);
// XXX make sure it's not mapped
vm_page_t* page = paddr_to_vm_page(tt_phys_);
DEBUG_ASSERT(page);
pmm_free_page(page);
// 需要 flush 所有 CPU 的缓存中该 ASID 空间残余的 TLB
// ARM64 可以使用 tlbi 指令实现这一操作
// X86 是不支持的,需要使用核间中断通知每个 CPU 自行操作
if (flags_ & ARCH_ASPACE_FLAG_GUEST) {
paddr_t vttbr = arm64_vttbr(asid_, tt_phys_);
__UNUSED zx_status_t status = arm64_el2_tlbi_vmid(vttbr);
DEBUG_ASSERT(status == ZX_OK);
} else {
ARM64_TLBI(ASIDE1IS, asid_);
asid.Free(asid_);
asid_ = MMU_ARM64_UNUSED_ASID;
}
return ZX_OK;
}