弱监督目标检测之一 最小熵隐变量模型
目标检测是计算机视觉一个非常重要的子任务。目标检测需要发现并准确定位自然图片中的物体。在2012年之前,目标检测主要基于手工设计的特征以及传统分类器。2012年以后,出现了很多基于深度学习的目标检测方法。基于深度学习的目标检测主要分为两类:one-stage和two-stage。One-stage的检测器会密集地在图片中放置很多不同scale和aspect-ratio的anchor boxes,然后通过回归对每一个anchor-box进行打分和回归,已确认每一个anchor-box框住每一类物体的置信度,并对anchor-box进行回归,以便更有效地定位物体。One-stage的检测器有Yolo[1]系列、SSD[2]系列以及最新的RetinaNet[3]等。Two-stage的目标检测器主要包括区域生成、特征提取、分类回归三个步骤。区域生成会针对每一张图片生成一定数量的可能包含物体的region proposals(生成方式包括off-line的,比如Edge-boxes[4],Selective Search[5],MCG[6]等以及online的region proposal network[7]),然后通过卷积神经网络(VGG16、ResNet等)以及区域pooling生成对每一个region proposal的特征表达,然后再经过全连接层对每一个区域进行分类以及回归。Two-stage的监测器主要是R-CNN系列,比如RCNN,Fast RCNN,Faster RCNN,R-FCN等。上面提到的模型是全监督设置下的检测模型,模型训练需要大量带有bounding-box标注(全监督信息)的图片,这种标注往往是time-consuming的。弱监督目标检测只需要指示图片中是否存在相应类别物体的image-level的弱监督信息。image-level的标注只指示图片中是否含有相应类别的物体,但是没有物体在图片中具体位置的坐标值,因此获得只有image-level标注(弱监督信息)的图片是很容易的,比如可以通过图片搜索引擎google image、Flicker等。
弱监督目标检测一般首先通过region proposal的方法,产生一定数量的可能包围物体的region proposal,然后通过隐变量学习(Latent Variable Learning)或者多实例学习(Multiple Instance Learning)的方式对proposals进行选择。
弱监督目标检测一般方法可以分为三类:隐变量学习(Latent Variable Learning)、多实例学习(Multiple Instance Learning)、深度多实例学习网络(Deep Multiple Instance Learning Network)。下面分别对三类方法一些典型的模型进行介绍,最后介绍我所在的实验室中国科学院大学电子学院模式识别与智能系统开发实验室发表在CVPR 2018的工作以及IEEE TPAMI上的工作MLEM,《Min-Entropy Latent Model for Weakly Supervised Object Detection》,其中代码已开源。
-
隐变量学习Latent Variable Learning
隐变量学习将图片中的每一个instance的location看做latent variable,然后通过一定的方式学习这些latent variables。一般隐变量学习问题都是非凸优化问题,因此在学习过程中,模型容易陷入局部极小值,有很多方法被提出来解决这个问题。凸聚类(Convex Cluster)是其中一种经典的办法。
在论文[8]提到了一种凸聚类的方法,促使可能包含相同类别物体的proposal的appearance更加的相似(图1)。在训练一个最大化间隔latent SVM[9]支持向量机对proposal进行分类的同时,引入一个正则化项,enforcing similarity between object windows and “representatvie” clusters。
![]()
其中![]() 为标准的
为标准的![]() 正则化项,
正则化项,![]() 是latent SVM的损失函数,
是latent SVM的损失函数,![]() 是enforce similarity的正则化项。
是enforce similarity的正则化项。
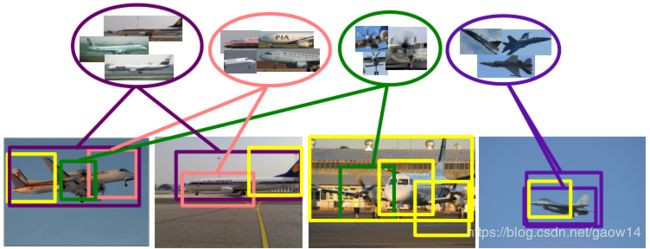
图 1
2. 多实例学习Multiple Instance Learning
另外一类解决弱监督目标检测的方法是把检测问题看成一个多实例学习的问题,其中把每一张图片看成一个bag,图片中的objects看做一个个的instances。然后在训练的时候迭代地从bag中选出得分高的proposal进行检测器的训练。由于只有image-level的监督信息,因此多实例学习弱监督目标检测的检测器的训练需要较好的初始样本,一般是选取每一张图片中面积较大的proposal,这样的proposal可能包括了图片面积的大部分,这样可以防止训练过早收敛到性能很差的局部解。
文献[10]提到了一种Mul-fold multiple instance learning方法,将正类训练样本进行划分,并进行交叉验证训练,从而减少训练过程中的随机性,防止训练陷入局部极小值。文献[12]提到了一种bag-splitting的方法,以减少模型优化过程中正样例的随机性。
3. 深度多实例学习网络 Deep Multiple Instance Learning Network
由于卷积神经网络可以提取很generic特征,从而对instance进行更好的特征表达,而端到端的学习也可以对检测模型进行协同的优化,从而演变出了端到端的深度多实例学习网络。比如WSDNN[13]、OICR[14]。OICR对instance classifier进行online refinement。PCL[15]对OICR的online refinement方法进行改进,从而得到更好的检测性能。
4. Min-Entropy Latent Model
下面着重介绍我所在的实验室:中国科学院大学电子学院模式识别与智能系统开发实验室发表在CVPR2018以及IEEE TPAMI上的工作MELM[16]。本文代码已开源。
上面提到的方法都未能较好地解决定位随机性以及局部极小值的问题。某一类物体,比如“car”,其几个不同的部分都可以最小化分类损失,但是由于物体外貌的歧义而未能优化目标检测器。而且检测器有时候只能检测出物体的某一个representative的部位,比如针对“person”,检测出“head”,而未能检测出更大的“extent”从而把整个人各部分检测出来。如图3所示,WSDNN方法在不同的迭代次数其检测出来的window不一样,而我们的MELM方法检测结果具有很好的稳定性,而且可以检测出更大的“extent”而不只是某一representative的部分。而针对局部极小值的问题,我们提出了“Clique Partition Module”和“Recurrent Learning”实现延拓优化(Continuation Optimization)从而更好地解决非凸问题。

图 2
其中一个“Clique”定义为一些空间上有联系(互相有重叠,并且重叠的IOU超过了某一个阈值)和类别上(有较大的并且相同的类别得分)也有联系的proposals的集合,如图3所示。

图3
我们的论文的贡献主要是四个。
一是采用深度神经网络结合最小熵隐变量模型以便更有效地discover instance并且最小化学习过程中的定位随机性;
二是采用一个“Clique Partition Module”更好地检测物体(instance collection)、检测出物体的更多的部分(object extent activation)。
三是用一个“Recurrent Learning”的算法分别将图像分类和目标检测看做一个“predictor”和一个“corrector”,并且利用延拓优化(Continuation Optimization)的方法解决非凸优化问题。
四是在PASCAL VOC数据集上取得了state-of-the-art的分类、定位和检测性能。
MELM主要包括三个部分,第一个部分就是上面提到的“Clique Partition Module”,这个部分可以从冗余的proposals中选择出空间和类别相近的proposals组成不同的cliques。第二个部分“Global Min-Entropy Model”可以发现可能包含“objects”和“object parts”的cliques,第三个部分“Local Min-Entropy Model”用于进一步更加准确定位第二个部分所发现的cliques中的objects。各个部分如图4所示。

图4
下面将会对各个部分以及优化方法进行详细的介绍。
4.1 Min-Entropy Latent Model
首先是一些符号约定和问题定义。x∈X![]() 代表一张图片,y∈Y
代表一张图片,y∈Y![]() 为图片标签,y={0,1}
为图片标签,y={0,1}![]() 。其中y=1
。其中y=1![]() 表示图片中至少包含某一类物体的一个实例(positive image),y=0
表示图片中至少包含某一类物体的一个实例(positive image),y=0![]() 代表图片中没有任何一类positive class的实例(negative image)。h
代表图片中没有任何一类positive class的实例(negative image)。h![]() 代表物体的location,H
代表物体的location,H![]() 为一张图片中所有的object proposals(采用Selective Search的fast模式,一般数目大约2000)。Hc
为一张图片中所有的object proposals(采用Selective Search的fast模式,一般数目大约2000)。Hc![]() 代表proposal clique并且是是H
代表proposal clique并且是是H![]() 的一个子集。Θ
的一个子集。Θ![]() 为模型参数。最小熵模型(Min-Entropy Latent Model)按照如下的方式进行定义。
为模型参数。最小熵模型(Min-Entropy Latent Model)按照如下的方式进行定义。
![]()
![]()
![]()
其中![]() 和
和![]() 分别代表global和local entropy model,并且分别用于cliques discovery和objects localization。
分别代表global和local entropy model,并且分别用于cliques discovery和objects localization。
4.1.1 Clique Partition
我们从每一张图片的![]() 中选择200得分最高的proposals组成一个小的集合
中选择200得分最高的proposals组成一个小的集合![]() ,从而建立一个个cliques。其中所得到的一个个proposals cliques满足下面的式子。
,从而建立一个个cliques。其中所得到的一个个proposals cliques满足下面的式子。
C![]() 式cliques的数目。下面简要谈一谈cliques的partition方法。首先所有的proposals按照得分进行降序排列,然后迭代进行下面的两个步骤。1.选择一个得分最高的但是还未属于任何一个clique的proposal组成一个新的clique;2.将与待观察的clique中的任何一个proposal的overlap超过一定阈值τ
式cliques的数目。下面简要谈一谈cliques的partition方法。首先所有的proposals按照得分进行降序排列,然后迭代进行下面的两个步骤。1.选择一个得分最高的但是还未属于任何一个clique的proposal组成一个新的clique;2.将与待观察的clique中的任何一个proposal的overlap超过一定阈值τ![]() 的proposals放入待观察的clique里面去。
的proposals放入待观察的clique里面去。 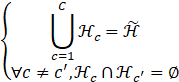
![]() 式cliques的数目。下面简要谈一谈cliques的partition方法。首先所有的proposals按照得分进行降序排列,然后迭代进行下面的两个步骤。1.选择一个得分最高的但是还未属于任何一个clique的proposal组成一个新的clique;2.将与待观察的clique中的任何一个proposal的overlap超过一定阈值
式cliques的数目。下面简要谈一谈cliques的partition方法。首先所有的proposals按照得分进行降序排列,然后迭代进行下面的两个步骤。1.选择一个得分最高的但是还未属于任何一个clique的proposal组成一个新的clique;2.将与待观察的clique中的任何一个proposal的overlap超过一定阈值![]() 的proposals放入待观察的clique里面去。
的proposals放入待观察的clique里面去。
4.1.2 Object Clique Discovery with Global Min-Entropy
Global Min-Entropy Model定义如下。
![]()
![]()
其中![]() 为clique
为clique ![]() 的概率,定义如下。
的概率,定义如下。
![]()
![]() 为proposal
为proposal ![]() 的object score,是其中object clique discovery分支的全连接层的输出。Global min-entropy定义如下。
的object score,是其中object clique discovery分支的全连接层的输出。Global min-entropy定义如下。
![]()
其中![]() 。
。
最后object clique discovery branch的损失函数定义如下。
![]()
4.1.3 Object Localization with local Min-Entropy
Global Min-Entropy发现了cliques之后,这些cliques可以区分positive images和negative images,但是会包含一些假阳性proposals。因此需要进一步对这些cliques里面的proposals进行选择,以便更好地定位出物体。因此local Min-Entropy Model定义如下。
![]()
其中

![]()
![]() 是h*在clique中的neighbors。
是h*在clique中的neighbors。![]() ,
,![]() 是两个proposals
是两个proposals ![]() 和
和![]() 的IOU。Object localization分支的损失函数定义如下。
的IOU。Object localization分支的损失函数定义如下。
![]()
将各个模块整合在一起后,整体的模型框架如下图所示。

图5
4.1.4 Model Implementation
如图6所示,MELM采用了VGG16的网络架构,但是最后一层的全连接层去掉,根据任务(clique discovery和object localization)加相应的全连接层。在学习过程中,针对每一张图片产生大概2000个proposals,然后对CONV5输出的整张图片的feature map进行ROI-pooling,从而对每一个proposal的特征进行提取。最后MELM采用了recurrent learning的算法进行优化。Recurrent Learning将image-level的监督信息迁移到目标检测的任务上来。在feed-forward过程中,global min-entropy model发现cliques,然后local min-entropy model定位的物体又作为pseudo-objects进行detectors训练。学习到的detectors的输出又会对每一个proposals的object probability进行更新如图6所示。
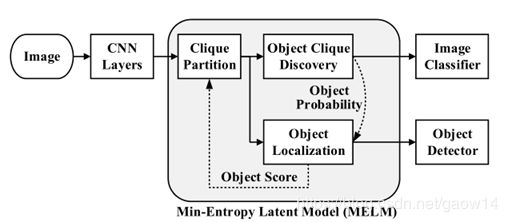
图 6
当然也可以加多个检测分支,即Accumulated Recurrent Learning,见图7。
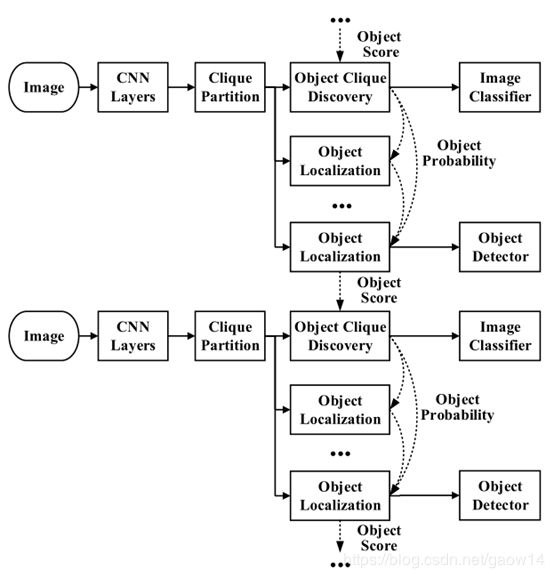
图 7
4.2 Experiments
最后来看看实验的结果。论文在PASCAL VOC 2007,2010,2012数据集以及ILSVRC数据集以及MSCOCO数据集上进行了大量的实验,取得了state-of-the art的性能。
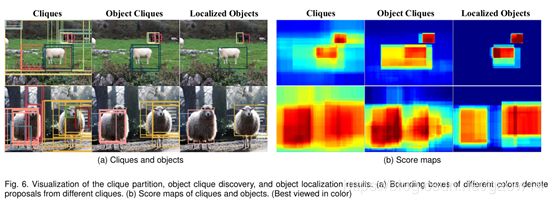
图 8
图9显示了在不同的训练epoch的objects cliques。
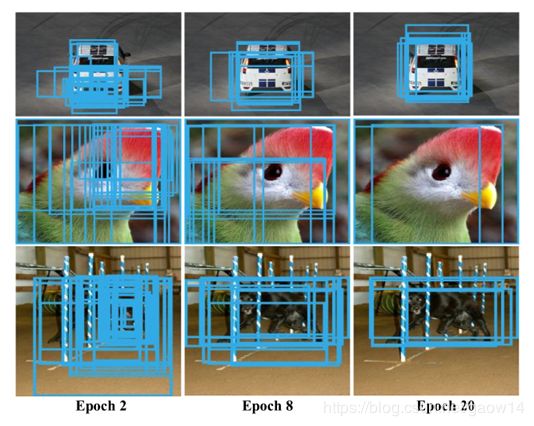
图 9
可以看到,在训练早期,object clique会包含object extent(objects和object parts),这保证了object extent会被卷积神经网络的filters激活,从而有助于后面local min-entropy model更加准确地定位物体。
4.2.2 Randomness Analysis
图10a显示了global和local entropy的变化,可以看到在学习过程中,min-entropy目标函数被优化。图10b显示了全连接层的梯度的变化。在训练早期阶段,Global Min-Entropy梯度略大于Local Min-Entropy的梯度,这显示在早期网络更加关注于优化图片分类器。在训练后期,Global Min-Entropy的梯度慢慢下降,Local Min-Entropy主导了网络的训练,这显示主要是检测器被优化。

图 10
图10c和10d显示,与WSDNN相比,MELM有更高的定位准确率和较小的定位方差。图11显示了更多的检测比较结果.

图 11
4.2.3 Performance and Comparison
在PASCAL VOC 2007数据及上,MELM检测性能与之前state-of-the-art方法的性能的比较如图12所示。

图 12
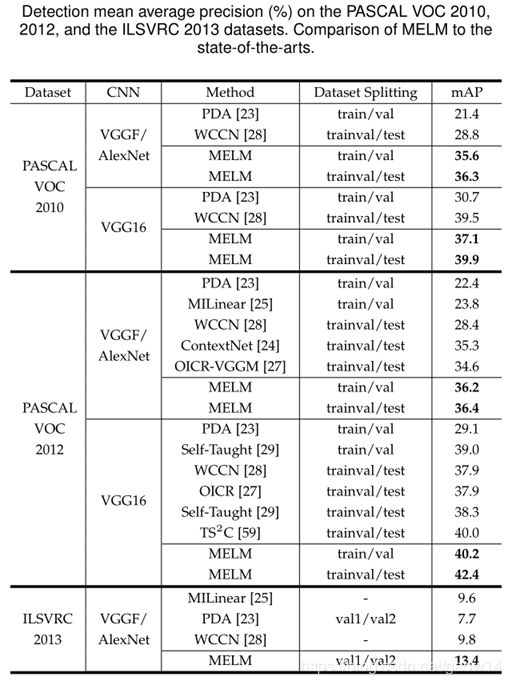
图 13
在PASCAL VOC 2010,2012以及ILSVRC2013数据集上,MELM与其他方法的性能比较如下所示。
总结一下,本论文提出了一个深度MELM(Min-Entropy Latent Model)用于目标检测,并在PASCAL VOC 2007,2010,2012和ILSVRC2013上取得了state-of-the-art的性能。MLEM包括三个部分:Clique Partition,Object Clique Discovery(Global Min-Entropy Latent Model),Object Localization(Local Min-Entropy Latent Model),通过clique partitioning和clique discovery,MLEM可以从大量的proposals中准确有效地学到object regions。最小化熵可以减小系统的随机性,因此利用这一原则,可以减少检测器训练过程中的positive instances位置的方差也可以减轻检测器的检测结果的歧义。而Recurrent Learning算法的引入,又有效地对复杂的非凸问题进行优化。