评分卡模型剖析之一(woe、IV、ROC、信息熵)
信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广义线性模型。
本文重点介绍模型变量WOE以及IV原理,为表述方便,本文将模型目标标量为1记为违约用户,对于目标变量为0记为正常用户;则WOE(weight of Evidence)其实就是自变量取某个值的时候对违约比例的一种影响,怎么理解这句话呢?我下面通过一个图标来进行说明。
Woe公式如下:

| Age |
#bad |
#good |
Woe |
| 0-10 |
50 |
200 |
=ln((50/100)/(200/1000))=ln((50/200)/(100/1000)) |
| 10-18 |
20 |
200 |
=ln((20/100)/(200/1000))=ln((20/200)/(100/1000)) |
| 18-35 |
5 |
200 |
=ln((5/100)/(200/1000))=ln((5/200)/(100/1000)) |
| 35-50 |
15 |
200 |
=ln((15/100)/(200/1000))=ln((15/200)/(100/1000)) |
| 50以上 |
10 |
200 |
=ln((10/100)/(200/1000))=ln((10/200)/(100/1000)) |
| 汇总 |
100 |
1000 |
|
表中以age年龄为某个自变量,由于年龄是连续型自变量,需要对其进行离散化处理,假设离散化分为5组(至于如何分组,会在以后专题中解释),#bad和#good表示在这五组中违约用户和正常用户的数量分布,最后一列是woe值的计算,通过后面变化之后的公式可以看出,woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响。再加上woe计算形式与logistic回归中目标变量的logistic转换(logist_p=ln(p/1-p))如此相似,因而可以将自变量woe值替代原先的自变量值;
讲完WOE下面来说一下IV:
IV公式如下:
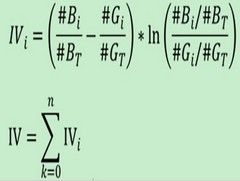
其实IV衡量的是某一个变量的信息量,从公式来看的话,相当于是自变量woe值的一个加权求和,其值的大小决定了自变量对于目标变量的影响程度;从另一个角度来看的话,IV公式与信息熵的公式极其相似。
事实上,为了理解WOE的意义,需要考虑对评分模型效果的评价。因为我们在建模时对模型自变量的所有处理工作,本质上都是为了提升模型的效果。在之前的一些学习中,我也总结了这种二分类模型效果的评价方法,尤其是其中的ROC曲线。为了描述WOE的意义,还真的需要从ROC说起。仍旧是先画个表格。

数据来自于著名的German credit dataset,取了其中一个自变量来说明问题。第一列是自变量的取值,N表示对应每个取值的样本数,n1和n0分别表示了违约样本数与正常样本数,p1和p0分别表示了违约样本与正常样本占各自总体的比例,cump1和cump0分别表示了p1和p0的累计和,woe是对应自变量每个取值的WOE(ln(p1/p0)),iv是woe*(p1-p0)。对iv求和(可以看成是对WOE的加权求和),就得到IV(information value信息值),是衡量自变量对目标变量影响的指标之一(类似于gini,entropy那些),此处是0.666,貌似有点太大了,囧。
上述过程研究了一个自变量对目标变量的影响,事实上也可以看成是单个自变量的评分模型,更进一步地,可以直接将自变量的取值当做是某种信用评分的得分,此时需要假设自变量是某种有序变量,也就是仅仅根据这个有序的自变量直接对目标变量进行预测。
正是基于这种视角,我们可以将“模型效果的评价”与“自变量筛选及编码”这两个过程统一起来。筛选合适的自变量,并进行适当的编码,事实上就是挑选并构造出对目标变量有较高预测力(predictive power)的自变量,同时也可以认为,由这些自变量分别建立的单变量评分模型,其模型效果也是比较好的。
就以上面这个表格为例,其中的cump1和cump0,从某种角度看就是我们做ROC曲线时候的TPR与FPR。例如,此时的评分排序为A12,A11,A14,A13,若以A14为cutoff,则此时的TPR=cumsum(p1)[3]/(sum(p1)),FPR=cumsum(p0)[3]/(sum(p0)),就是cump1[3]和cump0[3]。于是我们可以画出相应的ROC曲线。
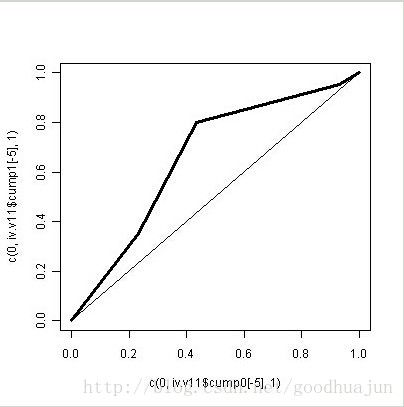
可以看得出来这个ROC不怎么好看。之前也学习过了,ROC曲线有可以量化的指标AUC,指的就是曲线下方的面积。这种面积其实衡量了TPR与FPR之间的距离。根据上面的描述,从另一个角度看TPR与FPR,可以理解为这个自变量(也就是某种评分规则的得分)关于0/1目标变量的条件分布,例如TPR,即cump1,也就是当目标变量取1时,自变量(评分得分)的一个累积分布。当这两个条件分布距离较远时,说明这个自变量对目标变量有较好的辨识度。
既然条件分布函数能够描述这种辨识能力,那么条件密度函数行不行呢?这就引出了IV和WOE的概念。事实上,我们同样可以衡量两个条件密度函数的距离,这就是IV。这从IV的计算公式里面可以看出来,IV=sum((p1-p0)*log(p1/p0)),其中的p1和p0就是相应的密度值。IV这个定义是从相对熵演化过来的,里面仍然可以看到x*lnx的影子。
至此应该已经可以总结到:评价评分模型的效果可以从“条件分布函数距离”与“条件密度函数距离”这两个角度出发进行考虑,从而分别得到AUC和IV这两个指标。这两个指标当然也可以用来作为筛选自变量的指标,IV似乎更加常用一些。而WOE就是IV的一个主要成分。
那么,到底为什么要用WOE来对自变量做编码呢?主要的两个考虑是:提升模型的预测效果,提高模型的可理解性。
首先,对已经存在的一个评分规则,例如上述的A12,A11,A14,A13,对其做各种函数变化,可以得到不同的ROC结果。但是,如果这种函数变化是单调的,那么ROC曲线事实上是不发生变化的。因此,想要提高ROC,必须寄希望于对评分规则做非单调的变换。传说中的NP引理证明了,使得ROC达到最优的变换就是计算现有评分的一个WOE,这似乎叫做“条件似然比”变换。
用上述例子,我们根据计算出的WOE值,对评分规则(也就是第一列的value)做排序,得到新的一个评分规则。

此处按照WOE做了逆序排列(因为WOE越大则违约概率越大),照例可以画出ROC线。
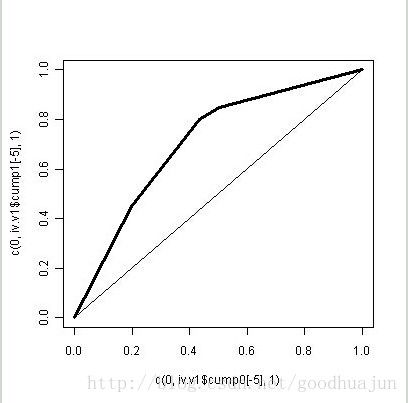
可以看出来,经过WOE的变化之后,模型的效果好多了。事实上,WOE也可以用违约概率来代替,两者没有本质的区别。用WOE来对自变量做编码的一大目的就是实现这种“条件似然比”变换,极大化辨识度。
同时,WOE与违约概率具有某种线性关系,从而通过这种WOE编码可以发现自变量与目标变量之间的非线性关系(例如U型或者倒U型关系)。在此基础上,我们可以预料到模型拟合出来的自变量系数应该都是正数,如果结果中出现了负数,应当考虑是否是来自自变量多重共线性的影响。
另外,WOE编码之后,自变量其实具备了某种标准化的性质,也就是说,自变量内部的各个取值之间都可以直接进行比较(WOE之间的比较),而不同自变量之间的各种取值也可以通过WOE进行直接的比较。进一步地,可以研究自变量内部WOE值的变异(波动)情况,结合模型拟合出的系数,构造出各个自变量的贡献率及相对重要性。一般地,系数越大,woe的方差越大,则自变量的贡献率越大(类似于某种方差贡献率),这也能够很直观地理解。
总结起来就是,做信用评分模型时,自变量的处理过程(包括编码与筛选)很大程度上是基于对单变量模型效果的评价。而在这个评价过程中,ROC与IV是从不同角度考察自变量对目标变量的影响力,基于这种考察,我们用WOE值对分类自变量进行编码,从而能够更直观地理解自变量对目标变量的作用效果及方向,同时提升预测效果。
这么一总结,似乎信用评分的建模过程更多地是分析的过程(而不是模型拟合的过程),也正因此,我们对模型参数的估计等等内容似乎并不做太多的学习,而把主要的精力集中于研究各个自变量与目标变量的关系,在此基础上对自变量做筛选和编码,最终再次评估模型的预测效果,并且对模型的各个自变量的效用作出相应的评价。