python爬虫爬学校官网(悄咪咪)并分析
最近对python爬虫比较感兴趣,就开始学习爬虫。
今天来记录下阶段性成果。
本文对西安邮电大学官网进行爬取,爬取网站上所有新闻内容(自2010年以来,共2461篇新闻稿),
并进行简单分析。
阅读本文需要requests库、beautifulsoup库、re库、jieba库、html必要基础知识。
查看学校官网robots协议
为了防止被查水表,我们先看看官网的robots协议
http://www.xiyou.edu.cn/robots.txt

ok,发现啥都没有。放心大胆地开始爬取。
思路分析
首先获得官网url,爬取新闻中心所有目录页面;通过所有目录页面url,爬取所有新闻页面url存入文件;从文件读取每一个新闻页面url来爬取新闻内容存入文件;通过文件进行词频分析,得出结论。
获得官网url
首先我们获得了学校官网url:http://www.xiyou.edu.cn/
之后的内容都是从此出发进行爬取。
充分观察
打开学校官网,进入新闻中心页面,如图

看到共有新闻中心目录共有247页,每页有10个新闻链接,想要爬取所有新闻页面需要先得到所有目录页面url。
通过观察链接规律得到:
第一页:http://www.xiyou.edu.cn/xwzx/zhxw.htm
从第二页开始依次为:
http://www.xiyou.edu.cn/xwzx/zhxw/246.htm
http://www.xiyou.edu.cn/xwzx/zhxw/245.htm
http://www.xiyou.edu.cn/xwzx/zhxw/244.htm
……
第247页为:
http://www.xiyou.edu.cn/xwzx/zhxw/1.htm
阅读网页源代码
我们进入网页源代码,找到十个新闻链接所在位置
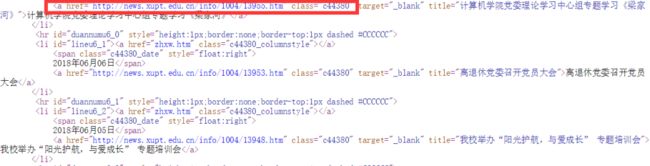
发现需要的链接地址在标签的href属性中,
在具体爬取过程中,发现在数字到208时,新闻页面进行了改版,域名、html格式发生变化,
前缀由 news.xupt.edu.cn 变为 www.xiyou.edu.cn
并且标签的href属性被省略为 “../../info ”前缀,不能直接爬取,所以需要进行特殊操作,爬取时须特别注意。
至此可以开始写第一个爬虫。
第一个爬虫:通过所有目录页面爬取所有新闻页面
具体说明写在注释中
#导入必要库文件
import requests
from bs4 import BeautifulSoup
import bs4
raw = 'http://www.xiyou.edu.cn/xwzx/zhxw'
#打开文件用于写入新闻页面url
with open("test.txt","a+") as f:
urls = []
for i in range(247,0,-1):
#247做单独处理
if i == 247:
url = raw+".htm"
else:
url = raw+'/'+str(i)+'.htm'
#尝试爬取,失败则终止并打印“Error”
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print('Error')
break
soup = BeautifulSoup(r.text, "html.parser")
#搜索目标标签
al = soup.find_all('a',class_="c44380")
for a in al:
#获得链接并对改版前后做不同处理
h = a.get('href')
if h[0]=='.':
temp = 'www.xiyou.edu.cn/info/'+h[-14:]+'\n'
else:
temp = 'news.xupt.edu.cn/info/'+h[-14:]+'\n'
#防止出现重复,写入文件
if temp not in urls:
urls.append(temp)
f.write(temp)
f.close()运行后文件夹中出现test.txt文件,存储了所有2461个新闻页面url如图,用于下一步爬取。
观察新闻页面html文件
通过观察发现新闻内容的每段内容存放在 中,如图

至此可以开始编写第二个爬虫
第二个爬虫:通过每个新闻页面url爬取新闻内容
同样具体说明写在代码中
import requests
from bs4 import BeautifulSoup
import bs4
import re
count=0
#打开文件读取每一个url
with open("test.txt","r") as f:
for line in f.readlines():
line = line.strip()
count+=1
#尝试爬取
try:
r = requests.get('http://'+line, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print('Error')
break
soup = BeautifulSoup(r.text, "html.parser")
#搜索目标标签div
s = soup.find_all('div',id=re.compile("vsb"))
with open("content.txt","a+",encoding='utf-8') as c:
for i in s:
#写入文件
c.write(i.get_text())
c.close()
print("第%d篇爬取成功!……loading……"%(count))
f.close()
#爬取需要一定时间,完成后输出“DONE”
print('DONE')运行过程如图

完成后文件夹中出现content.txt文件,储存所有新闻内容如图

进行词频分析
词频分析知识在前几篇博客已经非常详细,直接贴代码
import jieba
txt = open("content.txt", encoding="utf-8").read()
stopwords = [line.strip() for line in open("CS.txt",encoding="utf-8").readlines()]
'''for ch in'!":。,!.':
txt=txt.replace(ch," ")'''
words = jieba.lcut(txt)
counts = {}
for word in words:
if word not in stopwords:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(30):
word, count = items[i]
print ("%s\t\t%d"%(word,count))结果如下

总结
可以看出学校还是非常重视“学生”工作;“创新”、“创业”也被提上前列,符合“双创”大方向;“交流”、“介绍”也名列前茅,展现开放办学的思路。
声明
代码仅供参考,请勿无限制、无原则地爬取本网站或其他网站
转载请告知作者