作者:赵放、杜勇、王洪松、吴子丰
行为识别是指通过分析视频、深度传感器等数据,利用特定的算法,对行人的行为进行识别、分析的技术。这项技术被广泛应用在视频分类、人机交互、安防监控等领域。行为识别包含两个研究方向:个体行为识别与群体行为(事件)识别。近年来,深度摄像技术的发展使得人体运动的深度图像序列变得容易获取,结合高精度的骨架估计算法,能够进一步提取人体骨架运动序列。利用这些运动序列信息,行为识别性能得到了很大提升,对智能视频监控、智能交通管理及智慧城市建设等具有重要意义。同时,随着行人智能分析与群体事件感知的需求与日俱增,一系列行为分析与事件识别算法在深度学习技术的推动下应运而生。下面将介绍我们最新的相关研究。

图1 行为识别的定义及应用领域
1.基于层级化循环神经网络的人体骨架运动序列行为识别
目前基于人体骨架的行为识别方法主要可分为两类:1)基于局部特征的方法:该类方法是对序列中的各时刻的人体骨架的局部几何结构做特征提取,然后利用词包(Bag of Words, BoW)模型结合时间金字塔(Temporal Pyramid, TP)或是结合动态时间规整(Dynamic Time Warping, DTW)进行识别,该类方法没有或是只能局部考虑运动序列的时序信息,其识别过程更多地依赖局部静态结构特征;2)基于序列状态转移的方法:该类方法主要是利用HMM 对行为演化的动态过程进行建模,其两个主要不足是不仅需要对序列做预对齐,同时还需要估计状态转移过程的迁移概率,这本是两个比较困难的问题,其识别的精度也往往偏低。本研究主要基于微软的Kinect 和运动捕获系统提取的人体骨架运动序列,结合人体运动的相对性,提出了基于递归神经网络的人体骨架运动序列的行为识别模型。提出的模型首先对已经提取好的人体骨架姿态序列中节点坐标进行归一化,以消除人体所处绝对空间位置对识别过程的影响,利用简单平滑滤波器对骨架节点坐标做平滑滤波以提高信噪比,最后将平滑后的数据送入一个层次化双向递归神经网络同步进行深度特征表达提取、融合及识别,同时提供了一种层次化单向递归神经网络模型以应对实际中的实时分析需求。该方法主要优点是根据人体结构特征及运动的相对性,设计端到端的分析模式,在实现高精度识别率的同时避免复杂的计算,便于实际应用。本工作及其扩展版本先后发表在CVPR-2015及IEEE TIP-2016上。
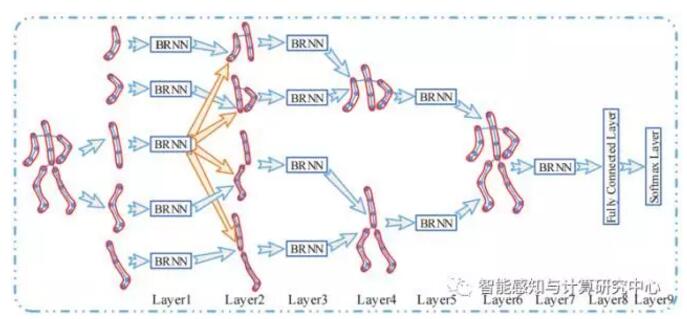
图2 基于层级化RNN的人体骨架序列行为识别示意图
2.基于双流循环神经网络的行为识别
由于深度传感器的成本的降低和实时的骨架估计算法的出现,基于骨架的行为识别研究越来越受欢迎。传统方法主要基于手工特征设计,对行为中运动的表达能力有限。最近出现了一些基于循环神经网络的算法,可以直接处理原始数据并预测行为。这些方法只考虑了骨架坐标随着时间的动态演变,而忽略了它们在某一个时刻的空间关系。在本文中,我们提出一种基于双流循环神经网络的方法如图三,分别对骨架坐标的时间动态特性和空间相对关系建模。对于时间通道,我们探索了两种不同的结构:多层循环神经网络模型和层次化的循环神经网络模型。对于空间通道,我们提出两种有效的方法把坐标的空间关系图转换为关节点的序列,以方便输入到循环神经网络中。为了提高模型的泛化能力,我们探究了基于三维坐标变换的数据增强技术,包括旋转、缩放和剪切变换。 在深度视频的行为识别标准数据库的测试结果显示,我们的方法对于一般行为,交互式行为和手势的识别结果都有相当大的提高。该工作已被CVPR-2017接收。
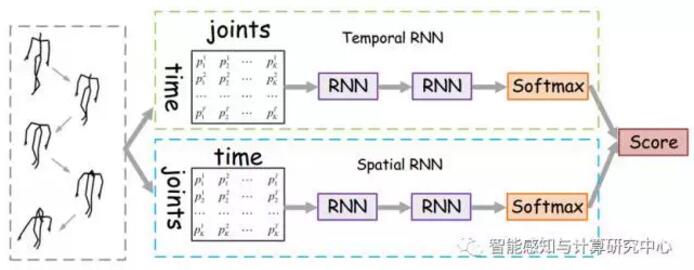
图3 基于双流RNN的骨架的行为识别方法
3.基于类相关玻尔兹曼机的视频事件分析
我们研究了有监督模型中的视频表达学习,以期望利用类标签学到更有区分力的表达,可同时用于视频分类和检索。我们知道,由于低层视觉特征与类标签之间的语义鸿沟、高维低层特征对后续分析所产生的计算代价以及有标签训练样本的缺乏,在不受控制的网络视频中分析无结构的群体行为和事件是一个非常具有挑战性的任务,如图四所示。为了克服这些困难,我们希望能够学习一个含有语义信息的紧凑中层视频表达。因此,我们提出了一种新的有监督概率图模型:类相关受限玻尔兹曼机(Relevance Restricted Boltzmann Machine, ReRBM),学习一种低维的隐语义表达用于复杂行为和事件分析。提出的模型在受限玻尔兹曼机(RBM)的基础上进行了一些关键性扩展:1)将稀疏贝叶斯学习与RBM结合来学习具有区分力的与视频类相关的隐含特征;2)将RBM中的二进制随机隐含单元替换为非负线性单元来更好的解释复杂视频内容,并使得变分推理能够适用于提出的模型;3)开发了有效的变分EM算法用于模型的参数估计和推理。我们在三个具有挑战性的标准视频数据集(Unstructured Social Activity Attribute、Event Video和Hollywood2)上对提出的模型进行了评估。实验结果表明,相比其他的一些隐变量概率图模型如图五所示,提出的模型所学到的类相关特征提供了对视频数据更具有区分力的语义描述,在分类准确率和检索精度上获得了最好结果,特别是在使用很少有标签训练样本的情况下。这项工作发表在机器学习、神经信号处理领域顶级国际会议NIPS 2013上,其扩展后的版本被计算机视觉领域顶级国际期刊IJCV 2016发表。

图 4 不同类型的活动 (简单动作、结构化活动、非结构化群体事件)

图5 基于类相关受限玻尔兹曼机的视频表达
4.采用双通道卷积神经网络的基于行走行为的身份识别
基于行走行为的身份识别,即步态识别一般指的是给定一个步态序列,要求从一个匹配库中找出与之最相似的序列,从而确定所给定序列中人的身份。步态是远距离、非受控情况下唯一可感知的生物特征,使用范围可远达50米,在远距离大范围的视觉监控场合具有不可替代的应用前景和研究价值。我们提出的方法处理的是预先提取好的步态能量图(Gait Energy Images,GEI),步态能量图是将视频序列中提取出的行人剪影对齐后沿时间维度平均得到的一种2D的灰度图像。首先,考虑到基于步态能量图的步态识别中局部细节差异的重要性,多点的局部比较应该会优于一次全局比较;其次,两个处于不同视角的样本可能会在表观上出现巨大的差异,如果只考虑比较单元自己的局部区域,将很难捕捉到足够的信息进行比较;另外还需要判别式地学习特征和比较模型。以上的三点都可以在一个深度卷积神经网络中实现,从而我们提出了基于上下文的跨视角步态识别方法如图六所示,在极为困难的同时跨视角和行走状态的任务中,也能够达到足够让人接受的识别效率。相关成果已发表在IEEE TMM-2015与TPAMI-2017上。

图6 步态识别流程图与提出的模型结构图
参考文献
[1] Yong Du, Wei Wang, and Liang Wang. Hierarchical Recurrent Neural Network for Skeleton Based Action Recognition. IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR). 2015.
[2] Yong Du, Yun Fu, Liang Wang. Representation Learning of Temporal Dynamics for Skeleton-Based Action Recognition. IEEE Transactionson Image Processing (TIP). 2016.
[3] Hongsong Wang and Liang Wang. Modeling Temporal Dynamics and Spatial Configurations of Actions Using Two-Stream Recurrent Neural Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[4] Fang Zhao, Yongzhen Huang, Liang Wang, Tieniu Tan. Relevance Topic Model for Unstructured Social Group Activity Recognition. Advances in Neural Information Processing Systems (NIPS). 2013.
[5] Fang Zhao, Yongzhen Huang, Liang Wang, Tao Xiang, and Tieniu Tan. Learning Relevance Restricted Boltzmann Machine for Unstructured Group Activity and Event Understanding. International Journal of Computer Vision (IJCV).2016.
[6] Zifeng Wu, Yongzhen Huang, Liang Wang. Learning Representative Deep Features for Image Set Analysis. IEEE Transactions on Multimedia (TMM). 2015.
[7] Zifeng Wu, Yongzhen Huang, Liang Wang, Xiaogang Wang, and Tieniu Tan. A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). 2017.