Focal Loss 论文笔记
Focal Loss:Focal Loss for Dense Object Detection
摘要:
\quad \; 到目前为止(2017年8月),目标检测的最高准确率都由R-CNN的衍生算法(two-stage)引领。在该类算法中,会在稀疏的目标候选位置(可能存在目标的位置)上使用一个分类器。相比之下,one-stage目标检测算法直接对原始图像进行密集的检测,这种算法可能更快,更简单,但准确率却一直没有超过two-stage目标检测算法。在本文,我们对该现象进行了研究,发现训练中“目标和背景类别的极度不均衡”(the extreme foreground-background class imbalance encountered)是最主要原因。本文提出通过对标准交叉熵损失函数的改进来解决类别不均衡的问题,改进后的损失函数会降低容易分类的example的权重。本文提出的Focal Loss会重点在难分类的example上训练,防止算法一直停留在对容易分类的example的训练上(Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training.)。为了评估本文提出的损失函数的有效性,我们设计并训练了一个简单的密集检测网络----RetinaNet。我们的结果表明:通过使用Focal Loss,RetinaNet超越了现存的two-stage目标检测算法,并且也保持了one-stage检测算法的速度优势。本文相关的代码详见:https://github.com/facebookresearch/Detectron。
文章目录
- 1. 简介
- 2. 相关研究(目标检测的常用方法)
- 3. Focal Loss
- 3.1. 加权交叉熵(Balanced Cross Entropy)
- 3.2. Focal Loss 的定义
- 3.3. 类别不均衡与模型初始化(Class Imbalance and Model Initialization)
- 3.4. 类别不均衡与两阶段检测算法(Class Imbalance and Twostage Detectors)
- 4. RetinaNet 检测算法
- 4.1. 推理和训练
- 5. 实验
- 5.1. 训练 Dense 检测算法
- 5.2. 模型架构设计
- 5.3. 与当前顶尖算法的对比
- 6. 结论
- 附录 A:Focal Loss*
- 附录 B:Derivatives
1. 简介
\quad \; 当前准确率最高的目标检测算法都是基于 two-stage 算法(基于候选区)。与R-CNN [11] 框架类似,第一阶段产生一组稀疏的对象候选位置,第二阶段使用一个卷积神经网络对候选区域进行分类(一个目标类别或背景)。尽管通过一系列的改进 [10, 28, 20, 14],two-stage 框架连续在COCO比赛中获胜。
\quad \; 虽然 two-stage 算法已经取得了较大地成功,但人们不禁要问:一个简单的 one-stage 检测算法能不能达到相似的准确率呢?one-stage 检测算法直接将图片作为输入(检测算法考虑了目标的“位置”、“尺度”、“宽高比”)。最近,one-stage 检测算法的相关研究(YOLO、SSD)提高了检测准确率,并且速度比最好的 two-stage 方法快10%~40%。
\quad \; 我们提出了一个 one-stage 目标检测算法,该算法第一次在COCO上达到了 two-stage 算法(FPN, Mask R-CNN)的准确率。在研究中,我们确定训练过程中的类别不均衡是阻碍 one-stage 检测算法准确率的主要因素,并提出了一个新的损失函数来消除该问题。
\quad \; 类别不均衡可以通过类似R-CNN的two-stage级联及启发式采样来解决。proposal 生成技术(例如 Selective Search [35], EdgeBoxes [39], DeepMask [24, 25], RPN [28])快速缩小候选对象位置的数量到一个非常小的数字(1-2k),过滤掉绝大部分背景采样。第二个阶段为分类阶段,启发式采样(例如固定的目标,背景比(1:3))或在线hard example mining (OHEM [31]) 被用来处理目标,背景之间的平衡。
\quad \; 与 two-stage 算法不同,one-stage 检测算法必须处理输入图像的大量的候选目标位置(~100k位置(不同空间位置,尺度、宽高比))。虽然也可以采用启发式采样来进行类别均衡,但其是非常低效的,因为训练过程仍主要由容易分类的背景主导。
\quad \; 而类似抽样启发式也可能被应用,他们效率低下的训练程序仍由容易分类背景的例子。启发式采样的低效是目标检测算法的经典问题,该问题一般通过 bootstrapping [33, 29] 或 hard example mining [37, 8, 31] 等技术来解决。
\quad \; 在本文,我们提出了一种新的损失函数(相比前述技术,提出的技术在解决类别不均衡方面更加高效)。提出的损失函数是一种动态缩放的交叉熵损失函数,如图1所示,随着正确类别的置信度的增加,其的缩放系数会逐渐退化到零。直观地说,该缩放系数能够自动降低训练过程中容易分类的 example 的权重,并快速地使模型集中在 hard example。实验表明我们提出的 Focal Loss 可以训练出一个高准确率的one-stage检测算法,并且性能超过了前述的启发式抽样和hard example mining及最好的one-stage检测算法。

\quad \; 为了说明提出的 Focal Loss 的作用,我们设计了一个简单的 one-stage 目标检测算法(名为RetinaNet)。其采取了特征金字塔并使用了锚点框。其借鉴了 [22, 6, 28, 20] 的思想。RetinaNet不仅高效,而且准确;我们最好的模型(基于 ResNet-101-FPN backbone)在COCO的test-dev上取得了39.1的AP,同时速度也有5fps,超过了到目前为止的所有one-stage及two-stage检测算法(见图2)。

2. 相关研究(目标检测的常用方法)
经典目标检测算法:
\quad \; 滑动窗检测算法。其以滑动的形式对整张图像进行检测,这种方法有着悠久、丰富的历史。Viola and Jones [37]使用boosted 目标检测算法来进行人脸检测,这推动了该种模型的广泛使用。HOG [4] 和通道特征积分 [5] 的引入产生了高效的行人检测算法。DPMs [8] 有助于 dense 检测器扩展到更通用的目标类别并且在PASCAL上有着非常好的结果。滑动窗方法是计算机视觉中的主要检测范式,随着深度学习的复兴、two-stage检测算法的发展,滑动窗方法很快就主导了目标检测算法。
Two-stage检测算法:
\quad \; 现代目标检测的主流范式基于 two-stage 方法。正如 Selective Search 的研究一样,第一阶段生成一组稀疏的候选 proposal(应该包含所有的目标,同时过滤掉绝大数背景),第二阶段将 proposal 分类为 foreground classes 或 background。R-CNN [11] 将第二阶段的分类器升级为了一个卷积网络,从而使得准确率有了较大提高并且引领了当前的目标检测算法。通过不断的改进,R-CNN 在速度[15, 10]和目标proposal的生成(通过学习来进行proposal的生成)[6, 24, 28]上都有了很大的提高。Region Proposal Networks (RPN) 将proposal 的生成过程和第二阶段集成为单个卷积网络,从而产生了 Faster R-CNN 框架 [28]。另外,已经有很多人对此框架进行了扩展,例如 [20, 31, 32, 16, 14]。
One-stage检测算法:
\quad \; OverFeat [30]是第一个现代one-stage目标检测算法(基于深度网络)。最近的 SSD [22, 9] 和 YOLO [26, 27] 使得人们又开始关注 one-stage 检测方法。这些算法对检测速度进行了优化(更快),但是它们的准确率却一直低于 two-stage 检测方法。SSD 的 AP 比 two-stage 方法低10-20%,而 YOLO 希望在极致的检测速度和准确率之间找到平衡(见图2)。最近的研究表明,two-stage检测算法可以通过减小输入图像的分辨率和 proposal 的数量来简单地加速检测方法,但是 one-stage 方法的准确率却一直低于 two-stage 方法(即使计算量更大)[17]。本文旨在研究:one-stage检测算法的准确率能否达到或超过two-stage方法,并有相似或更快的检测速度。
\quad \; RetinaNet检测算法的网络结构与之前的dense检测算法有很多相似之处,尤其是RPN [28]中引入的“anchors”概念、SSD [22]中使用的特征金字塔。这里强调下:RetinaNet检测算法的高准确率不是由于算法在网络结构设计方面的创新,而是由于本文提出的新损失函数。
类别不均衡(Class Imbalance):
\quad \; 经典的 one-stage 目标检测算法(比如boosted检测算法)、DPMs 及最近的一些研究(比如SSD检测算法)在训练过程中面临类别不均衡的问题(class imbalance)。这些检测算法会给每张图像生成104-105个候选位置,但是只有几个位置含有目标。类别不均衡导致了以下两个问题:(1). 因为大多数位置都是容易分类的背景(不包含有用的学习信息),所以训练时不充分的。(2). 容易分类的背景会主导训练过程并导致训练出的模型性能不高(lead to degenerate model)。一个常见的解决方案是使用某种形式的 hard negative mining [33, 37, 8, 31, 22],这些方法通过对 hard example 进行采样或更复杂的采样/重新赋权重策略 [2]。本文证明了,提出的 focal loss 自然地处理了 one-stage 检测算法中的类别不均衡问题,并允许我们去有效地在所有 example 上训练,而不需要抽样、同时不会出现容易分类的背景主导 loss 和梯度的情况出现。
鲁棒估计(Robust Estimation):
\quad \; 现在已经有了很多关于鲁棒损失函数的研究(例如:Huber loss)。这些函数通过减小离群值(hard example (with large error))在损失函数中的权重。与之相反,Focal loss 旨在通过降低群内值(easy example (容易分类的背景))在 loss 中的权重(即使这些点很多)来解决类别不均衡问题。换句话说,Focal loss 与之前的鲁棒损失相反:其使得优化算法始终聚焦在一组稀疏的 hard example 上。
3. Focal Loss
\quad \; Focal Loss 被用来解决 one-stage 检测算法的问题(在 one-stage 检测算法中,foreground 类和 background 类极度不均衡 (例如1:1000))。让我们从二分类交叉熵(CE)损失函数开始 focal loss 的介绍:将 Focal loss 扩展到多分类任务不仅非常简单并且工作的非常好。为了简单,本文将以二分类问题为例进行研究。
(1) CE ( p , y ) = { − log ( p ) if y = 1 − log ( 1 − p ) otherwise \text{CE}(p,y)= \begin{cases} -\text{log}(p) \qquad \quad \text{if} \ \ y=1 \\ -\text{log}(1-p) \quad \ \text{otherwise}\end{cases} \tag{1} CE(p,y)={−log(p)if y=1−log(1−p) otherwise(1)上式中, y ∈ { ± 1 } y\in\{\pm1\} y∈{±1} 用来表明 ground truth 类别, p ∈ [ 0 , 1 ] p\in[0,1] p∈[0,1] 是模型预测的 y = 1 y=1 y=1 的概率。为了标记方便,我们定义 p t p_{t} pt 为: (2) p t = { p if y = 1 1 − p otherwise p_{t}= \begin{cases} p \qquad \ \ \ \text{if} \ \ y=1 \\ 1-p \quad \text{otherwise}\end{cases} \tag{2} pt={p if y=11−potherwise(2)然后交叉熵就可以重写为: CE ( p , y ) = CE ( p t ) = − log ( p t ) \text{CE}(p,y)=\text{CE}(p_{t})=-\text{log}(p_{t}) CE(p,y)=CE(pt)=−log(pt)
\quad \; 经典的交叉熵损失函数如图1中的蓝线所示。经典交叉熵损失函数的一个典型特性是:即使一个 example 很容易分类 ( p t ≫ 0.5 p_{t} \gg 0.5 pt≫0.5),其仍会导致不小的 loss。当对大量的容易分类的 example 的 loss 求和后,很容易淹没罕见的类(example 数量比较少的类)
3.1. 加权交叉熵(Balanced Cross Entropy)
\quad \; 解决类别不均衡问题的一个常用方法是:给类别 1 添加一个权重系数 α \alpha α,给类别 class-1 添加一个权重系数 1 − α 1-\alpha 1−α 。在实际使用中, α \alpha α 的设置方法一般有两种:(1). 设置为类别出现的频率的倒数。(2). 被看做一个超参数,通过交叉验证来设置。为了标记的简单,本文定义 α t \alpha_{t} αt 与 p t p_{t} pt 的意义类似。然后,加权交叉熵可以写为: (3) CE ( p t ) = − α t log ( p t ) \text{CE}(p_{t})=-\alpha_{t}\text{log}(p_{t}) \tag{3} CE(pt)=−αtlog(pt)(3)
这个损失函数是经典交叉熵的一个简单扩展,其将作为 focal loss 实验的 baseline。
3.2. Focal Loss 的定义
\quad \; 与我们实验所要说明的一样,dense 检测算法训练过程中的严重类别不均衡主导了交叉熵损失。容易分类的负样本主导了 loss 和 梯度。当使用 α \alpha α 解决类别均衡问题时,它不会容易分类、难分类的样本区别对待。与之不同,本文提出减小容易分类样本的权重,从而使得算法专注于难分类的样本。
\quad \; 准确来说,我们打算给经典的交叉熵损失函数添加一个调制系数 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ,其中的 γ \gamma γ 为一个调整的 focusing 参数(大于0)。本文将 focal loss 定义为: (4) FL ( p t ) = − ( 1 − p t ) γ log ( p t ) \text{FL}(p_{t})=-(1-p_{t})^{\gamma} \text{log}(p_{t}) \tag{4} FL(pt)=−(1−pt)γlog(pt)(4)
\quad \; 图1 展示了 γ ∈ [ 0 , 5 ] \gamma \in [0,5] γ∈[0,5] 时的 focal loss。我们可以注意到 focal loss 的两个特性:(1). 当一个 example 被分类错误且 p t p_{t} pt 非常小时,调制系数接近于1,此时,focal loss 与经典的交叉熵损失函数近乎一样。随着 p t → 1 p_{t} \rightarrow 1 pt→1,调制系数逐渐趋向于0,此时,容易分类的 example 的 loss 的权重被减小。(2). 通过 focusing 参数 γ \gamma γ 的调整可以使得容易分类的 example 的权重被平滑地降低。当 γ = 0 \gamma=0 γ=0 时,Focal Loss 等价于经典的交叉熵(CE),并且随着 γ \gamma γ 的增加,调制系数的影响同样会增加(本文发现 γ = 2 \gamma=2 γ=2 在实验中工作的很好)。
\quad \; 直觉上来说,调制系数减少了容易分类的 example 对 loss 的贡献。例如:Focal Loss 减小了容易分类的样本的损失(当 p t = 0.9 p_{t}=0.9 pt=0.9 时,损失将比标准交叉熵小 100 倍;当 p t ≈ 0.968 p_{t} \approx 0.968 pt≈0.968 时,损失将比标准交叉熵小 1000 倍)。同时,Focal Loss 增加了错误分类的样本的损失(当 p t ≤ 0.5 p_{t} \leq 0.5 pt≤0.5 且 γ = 2 \gamma=2 γ=2 时,损失将被放大 4 倍)。
\quad \; 在实际使用中,我们使用加权形式的 focal loss: (5) FL ( p t ) = − α t ( 1 − p t ) γ log ( p t ) \text{FL}(p_{t})=-\alpha_{t}(1-p_{t})^{\gamma}\text{log}(p_{t}) \tag{5} FL(pt)=−αt(1−pt)γlog(pt)(5)
\quad \; 我们在本文的实验中采用了公式5形式的 focal loss,因为加权形式可以轻微的提高准确率。注意:在具体的代码实现中,我们将 sigmoid 激活函数与 loss 的计算进行了结合,从而提高数值稳定性。
\quad \; 在本文的主要实验中,我们使用上面了公式5形式的 focal loss,其的准确形式并不重要。在附录中,我们罗列了其它形式的 focal loss,并且证明了其与公式 5 一样同等有效。
3.3. 类别不均衡与模型初始化(Class Imbalance and Model Initialization)
\quad \; 二分类模型被默认初始化为对于 y = − 1 y=-1 y=−1 或 1 1 1 有着相同的概率。在这样的初始化之下,当存在类别不均衡时,最常出现的类别会主导总损失,并导致训练早期的不稳定。为了解决这个问题,我们在训练早期,为稀有类别(foreground)的概率值( p p p),引入了一个预设值(‘prior’)。我们用 π \pi π 来表示、设置这个预设值,从而保证模型对于稀有类别的样本的预测概率是比较低的(比如 0.01)。注意:这只是一个模型初始化方面的改变(详见 4.1 节),并没有改变损失函数。我们发现在类别严重不均衡的情况下,这能同时提高交叉熵、focal loss 的训练稳定性。
3.4. 类别不均衡与两阶段检测算法(Class Imbalance and Twostage Detectors)
\quad \; Two-stage 检测算法一般使用标准交叉熵(不加权)。与 Focal Loss 不同,其一般通过下面两种机制来解决类别不均衡问题:(1). two-stage 级联。(2). biased minibatch 采样。第一阶段进行 object proposal [35, 24, 28],该阶段将近乎无限多的可能出现 object 的位置减少到 1-2k 个位置。更重要的是,筛选出的 proposal 不是随机的,而是一些极有可能对应 true object 位置的 proposal。该阶段可以去除绝大多数的容易的 negatives。第二阶段,biased 采样一般被用来去构建 minibatch(例如,包含1:3的pos/neg的样本)。这个比例可以看做一种隐式的 α \alpha α 加权(通过采样实现)。本文提出的 Focal Loss 直接通过损失函数来解决 one-stage 检测算法的类别不均衡问题。
4. RetinaNet 检测算法
\quad \; RetinaNet 是一个single、unified的网络,其由一个 backbone 网络和两个 task-specific 子网络组成。backbone 网络(一个现成的卷积网络)以整张图像为输入,输出特征图谱。第一个 task-specific 子网络以 backbone 网络的输出为输入,以卷积形式进行 object 的分类;第二个 task-specific 子网络以卷积形式进行 bounding box 回归;两个子网络的具体情况详见图3。虽然这些组成部分有很多东西可以调整,但绝大多数参数对特定值不是特别敏感。后面我们将对 RetinaNet 的各部件做详细介绍。

Feature Pyramid Network Backbone:
\quad \; 我们以 [20] 中的 Feature Pyramid Network (FPN) 作为 RetinaNet 的 backbone 网络。简而言之,FPN 使用 top-down 路径和横向连接对卷积网络进行了增强,从而高效地构建一个丰富、多尺度的特征金字塔(feature pyramid)(见图 3a-b)。特征金字塔的不同层可以检测不同尺度的 object。FPN 相比 Fully Convolutional Network(FCN)提高了多尺度预测能力,这个提高见以下研究:RPN [28] 和 DeepMask-style proposal [34] 及其它的 two-stage 检测算法(Fast R-CNN [10] 或 Mask R-CNN [14])的研究。
\quad \; 按照 [20] 中的步骤,在 ResNet [16] 上面构建了 FPN。我们基于 P 3 P_{3} P3 到 P 7 P_{7} P7 级的特征构建一个 Pyramid(注: P i P_{i} Pi 中的 i i i 表示 Pyramid 的分辨率为输入的 2 l 2^{l} 2l 分之一) 。在 [20] 中,所有的 Pyramid 层有着 256 个通道。Pyramid 的细节与 [20] 几乎一样,但也有差别。虽然很多设计的选择不是非常重要,但请注意:FPN backbone 非常重要:前期我们进行了一些实验,直接使用 ResNet 最后一层的特征产生了低的 AP。RetinaNet 中的 P 3 P_{3} P3 ~ P 5 P_{5} P5 直接取 ResNet 的 C 3 C_{3} C3 ~ C 5 C_{5} C5 即可,通过在 C 5 C_{5} C5 上增加一个步长为2的 3x3 卷积来获得 P 6 P_{6} P6,通过在 P 6 P_{6} P6 后添加一个步长为2的 3x3 卷积及 ReLU 激活函数;与 [20] 的区别:(1). 本文没有使用 P 2 P_{2} P2 (考虑到计算量) (2). 本文的 P 6 P_{6} P6 通过步长为2的卷积实现,而不是下采样。(3). 本文使用 P 7 P_{7} P7 来提高大目标的检测。这些小修改在保持准确率的同时,提高了检测速度。
锚点框(Anchors):
\quad \; 本文使用了类似于[20]中的RPN锚点框变种的锚点框策略。特征金字塔的 P 3 P_{3} P3 到 P 7 P_{7} P7,锚点框对应的感受野的大小为从 3 2 2 32^{2} 322 到 51 2 2 512^{2} 5122。与 [20] 一样,我们在每个 pyramid 级别使用三种宽高比的锚点框 (1:2,1:1,2:1)。为了使锚点框的覆盖密度超过 [20],在每个级别,我们添加了下列尺寸的锚点框( 2 0 2^{0} 20, 2 1 / 3 2^{1/3} 21/3, 2 2 / 3 2^{2/3} 22/3)。这提高了本文的 AP。每个级别共计 9 个锚点框,这些锚点框的像素覆盖范围为 32-813。
\quad \; 我们通过一个 K 维的 one-hot 向量来为每个锚点框指定类别,一个 4 维向量来为锚点框指定 bbox 框。类别:我们按照RPN [28]的方法为各锚点框指定类别,但针对 multi-class 检测作为修改,并调整了阈值。具体来说,根据 IoU 来为各个锚点框分配标签,如果锚点框与 ground truth object box的 IoU 大于0.5,就将锚点框分配给该 object;如果 IoU 属于 [1, 0.4),就将该锚点框分配给 background。由于每个锚点框只能属于一个类别,所以使用了 one-hot 编码。如果 IoU 属于 [0.4, 0.5),就不为锚点框指定类别,并在训练中忽略这些锚点框。边界框:边界框标签定义为锚点框与 object 真实边界框之间的偏差(offset);如果没给锚点框指定 foreground 类别,就不给锚点框指定边界框标签。
分类子网络 (Classification Subnet):
\quad \; 分类子网络会为各个空间位置的锚点框及类别预测含有目标的概率。分类子网络是一个以 P i P_{i} Pi 为输入的小 FCN。不同 P i P_{i} Pi 层上的分类子网络使用相同的参数。分类子网络的设计很简单。
\quad \; 分类子网络对各个空间位置的锚点框、目标类别,预测了目标的出现概率。分类子网络是一个以 FPN 不同层次的特征为输入的小 FCN。不同层次特征上的 FCN 有着共同的参数。分类子网络的设计很简单,以 FPN 特定层次的特征图谱(C个通道)为输入。分类子网络由四个 3x3 卷积层(C个filters,ReLU)组成,然后使用一个有着 K A 个滤波器的 3x3 卷积层(Sigmoid)(见 图 3c)。在本文的绝大多数实验中,C=9,A=9。
\quad \; 与 RPN [28] 不同,我们的目标分类子网络更深,只使用了 3x3 卷积,并且分类子网络不与边框回归子网络共享参数。我们发现这些设计比网络的超参数更加重要(效果更好)。
边框回归网络 (Box Regression Subnet):
\quad \; 边框回归子网络和分类子网络是并行的。与分类子网络类似,边框回归子网络是一个以 FPN 不同层次的特征为输入的小 FCN。该 FCN 的输出为预测的边框相对于锚点框的偏移量。边框回归子网络与分类子网络的设计基本一致,除了回归子网络的最后一层卷积层使用了 4A 个滤波器,使用了线性激活函数(见 图 3d)。每个空间位置都有 A 个锚点框,每个锚点框的输出为一个表示预测框与锚点框之间的偏置值的 4 维向量(我们使用了 RCNN [11] 中的标准 box 参数)。注意:与最近的一些研究工作不同,我们使用了一个不考虑类别的 bbox 回归器,其有着更少的参数,但我们发现考不考虑类别性能接近(we found to be equally effective)。目标分类子网络和边框回归子网络的输入相同,但有着独立的参数(两个子网络互不干扰)。
4.1. 推理和训练
推理:
\quad \; RetinaNet 整体是一个 FCN(图3),其包含了一个 ResNet-FPN backbone、一个分类子网络 及 一个边框回归子网络。如图3所示,推理过程需要将图片以前馈的形式通过整个网络。为了提高速度(这里的做法只是提高了decode速度),在 FPN 的每个特征层次上,我们只解码(decode)最多 1k 个 top-scoring 预测(通过使用阈值 0.05 对检测器的 confidence 进行过滤)。然后将各个 FPN 特征层次上的 top-scoring 预测进行合并,并使用 NMS(阈值为 0.5) 来产生最终的预测结果。
Focal Loss:
\quad \; 我们将 Focal Loss 作为分类子网络的损失函数。如第5章所示,我们发现 γ = 2 \gamma=2 γ=2 在实践中表现非常好,RetinaNet is relatively robust to γ ∈ [ 0.5 , 5 ] \gamma \in [0.5, 5] γ∈[0.5,5]。注意:在训练 RetinaNet 时,focal loss 被用于每个图像的 ~100k 个锚点框上。这与使用启发式采样 (RPN) 和 hard example mining(OHEM, SSD)来选择少量的锚点框完全不同。单张图像的总 focal loss 的计算方法如下:首先计算 ~100k 锚点框的 focal loss 的和,然后使用被指定为 ground-truth 框的锚点框数量进行标准化(The total focal loss of an image is computed as the sum of the focal loss over all ~100k anchors, n o r m a l i z e d normalized normalized b y by by t h e the the n u m b e r number number o f of of a n c h o r s anchors anchors a s s i g n e d assigned assigned t o to to a a a g r o u n d − t r u t h ground-truth ground−truth b o x box box)。我们通过被指定为 ground-truth 的锚点框的数量进行标准化,而不是总的锚点框数量,因为锚点框中的绝大多数都是容易分类的 negatives(这些 easy negative 在 focal loss 中有着微乎其微的值)。最后,我们注意到:稀有类的权重 α \alpha α 有一个稳定的范围,但是通常需要配合 γ \gamma γ 进行选择(见表 1a, 1b)。通常情况下,当 γ \gamma γ 增加时, α \alpha α 应该轻微减小(在我们的实验中, γ \gamma γ=2, α \alpha α=0.25 效果最好)。
初始化(Initialization):
\quad \; 我们用 ResNet-50-FPN 和 ResNet-101-FPN [20] 进行了实验。基础的 ResNet-50 和 ResNet-101 都是在 ImageNet 1k 上训练的;本文使用的是 [16] 开源的模型。为 FPN 新添加的层都按照 [20] 的方式进行初始化。除子网络的最后一层外的所有添加的卷积层 bias 都初始化为0,权重用 σ = 0.01 \sigma=0.01 σ=0.01 的高斯分布进行初始化。分类子网络的最后一个卷积层的 bias 初始化为 b = l o g ( ( 1 − π ) / π ) b=log((1-\pi)/\pi) b=log((1−π)/π),这里的 π \pi π 用来指定在训练开始,foreground 锚点框的 confidence 为 ~ π \pi π。在所有的实验中,我们令 π \pi π=0.01,尽管其的值对特定值是非常鲁棒的,如 3.3 节所示,这个初始化防止了,在训练的第一次迭代,大量的 background 锚点框产生一个巨大的、不稳定的 loss 值。
优化(Optimization):
\quad \; 我们使用 stochastic gradient descent (synchronized(同步) SGD over 8 GPUs) 来训练 RetinaNet。Minibatch 的大小为 16(2 图片/GPU)。无特殊情况时,所有模型都训练 90k 次迭代。初始学习速率为 0.01,然后在第 60k、80k 次迭代将学习速率除以 10。无特殊说明时,只使用水平翻转进行数据增强。权重衰减系数为 0.0001,移动平均系数为 0.9(Weight decay of 0.0001 and momentum of 0.9 are used)。我们以 focal loss(分类子网络)和 standard smooth L 1 L_{1} L1(边框回归 [10] 子网络) 的和为训练损失。从表 1e 可知,训练时间最短 10 小时,最长 35 小时。
5. 实验
\quad \; 我们在 COCO 数据集 [21] 的 bbox 检测任务上进行了实验。在训练中,数据集的划分与 [1, 20] 一致,使用了 COCO trainval35k 数据集划分方法(80k/40k/…,80k图像用于训练,从40k中采样35k用于评估)。我们通过 minival 划分(留下来5k图像用于评估),研究了算法各部分对性能的影响及敏感度。本文的大部分结果都是在 COCO test-dev 数据上的 AP,这部分数据没有公开的标签,需要将预测结果提交给评估服务器来获取结果。
5.1. 训练 Dense 检测算法
\quad \; 我们进行了大量的实验,来分析提出的损失函数 及 各种优化策略对 dense 检测算法的影响。所有实验的 backbone 都是 50/100 ResNets with a Feature Pyramid Network (FPN)。所有的 ablation 研究中,训练和测试都使用了 600 像素尺度的图像。
网络初始化:
\quad \; 我们首先尝试使用标准交叉熵损失函数来训练 RetinaNet(不对初始化、学习策略做出修改)。网络不收敛,训练过程中出现了发散现象。但是,通过本文提出的方法(见4.1节)对最后一个卷积层的初始化便可以保证收敛( π \pi π=0.01)。通过更改最后一层的初始化,RetinaNet with ResNet-50 可以在 COCO 数据集达到 30.2 的 AP(这个结果其实已经很好)。结果对 π \pi π 的具体值不敏感,所以所有实验中都令 π \pi π=0.01。
加权交叉熵(Balanced Cross Entropy):
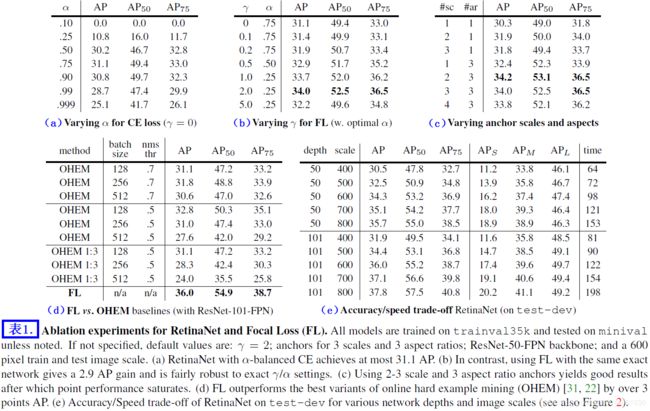
\quad \; 我们接下来尝试使用 α \alpha α-balanced CE 损失(详见3.1 节)来提升网络的学习。同时我们也对不同的 α \alpha α 进行了实验(详见表1a)。 α \alpha α=0.75 能够给 AP 带来 0.9 的提高。
Focal Loss:
\quad \; 我们提出的 Focal Loss 的实验结果见表 1b。Focal Loss 引入了一个超参数 γ \gamma γ,该参数控制调制项的程度。当 γ \gamma γ=0 时,focal loss 与交叉熵损失函数等价。随着 γ \gamma γ 的增加,loss 的曲线发生了明显的变化,那些容易分类的样本的损失经过调制变得更低,见图 1。随着 γ \gamma γ 的增加,Focal Loss 能够带来更大的 AP 提升。 γ \gamma γ=2 的 focal loss 能够获得比 α \alpha α-balanced 交叉熵高 2.9 的 AP。
\quad \; 对于表 1b 中的所有实验,我们为各个 γ \gamma γ 找到了最优 α \alpha α 值。我们可以看到:更高的 γ \gamma γ 需要配合更低的 α \alpha α(因为 easy negatives 被降低了权重,所以也需要调低 positives 的权重)。总体来说,更改 γ \gamma γ 的好处非常多,事实上, α \alpha α 的最优值范围为 [0.25, 0.75](我们对 α ∈ [ 0.01 , 0.999 ] \alpha \in [0.01, 0.999] α∈[0.01,0.999] 进行了测试)。在所有的实验中,我们都令 γ \gamma γ=2.0, α \alpha α=0.25,但其实 α \alpha α=0.5 时的效果也不错(0.4 AP lower)。
Analysis of Focal Loss:
\quad \; 为了更好地理解 focal loss,我们一个收敛了的模型的损失的经验分布进行了分析。为此,我们用 γ \gamma γ=2.0 的 focal loss 对 ResNet-101 600 像素的模型进行了训练(其有着 36.0 的 AP)。我们使用该模型对大量的随机图像进行了处理,并采样了~ 1 0 7 10^{7} 107个negative窗 及 ~ 1 0 5 个 10^{5}个 105个positive窗的预测概率。然后,分别为 positives 和 negatives 的 samples 计算 focal loss (FL),并进行标准化使得损失的和为 1。计算完标准化的 loss 后,我们将 loss 从低到高进行排序,并分别绘制 positive 和 negative samples 在不同 γ \gamma γ 设置下的累积分布函数(Given the normalized loss, we can sort the loss from lowest to highest and plot its cumulative distribution function (CDF) for both positive and negative samples and for different settings for γ \gamma γ (even though model was trained with γ \gamma γ = 2))。
\quad \; positive 和 negative samples 的累积分布函数如图4所示。如果我们观察 positive samples,我们可以看到对于不同的 γ \gamma γ 值,CDF 看起来相当相似(即CDF对 γ \gamma γ值不敏感)。例如,占 positive samples 20% 的难分类 positive samples 的 loss 占了 positive loss 的一半。随着 γ \gamma γ 的增加,loss 逐渐关注前 20% 的examples,但是这种影响是微不足道的。
\quad \; γ \gamma γ 对于 negative samples 的影响是截然不同的。对于 γ \gamma γ=0,positive 和 negative CDFs 是完全相似的。但是,随着 γ \gamma γ 的增加,注意力几乎都集中在 hard negative examples。实际上,当 γ \gamma γ=2 时,损失由小部分的 samples 主导。我们可以看到,FL 能够有效地降低 easy negatives 的 loss,将注意力放在 hard negative examples。

Online Hard Example Mining(OHEM):
\quad \; [31] 提出通过使用 high-loss examples 来构建 minibatchs 来提高 two-stage 检测算法的性能。具体来说,在 OHEM 中,每个 example 的得分是根据它的 loss 评定的,然后使用 NMS 进行处理,然后用 high-loss examples 来构建一个 minibatch。NMS 阈值和 batch_size 是可调的参数。与 Focal Loss 类似,OHEM 将更多的关注力放在错误分类的样本,但与 Focal Loss 不同,OHEM 完全丢弃了容易分类的样本。我们也实现了 SSD 的 OHEM 的变种:在对所有样本使用 NMS 后,minibatch 被以 positive:negative=1:3 的形式进行构建,来帮助确保每个 minibatch 有足够的 positives。
\quad \; 我们在 one-stage 检测算法(类别严重不均衡)中对上述 OHEM 变种进行了测试。在选定 batch_size 和 NMS 阈值下,原始的 OHEM 和 “OHEM 1:3” 的结果见表 1d。这些结果使用 ResNet-101,在此设置下,使用 FL 的 baseline 取得了 36.0 的 AP。相反,OHEM(no 1:3 ratio, batch size 128, nms of 0.5)最高只得到了 32.8 的 AP。两个结果的 AP 相差了 3.2,表明 FL 在训练 dense 检测算法时,比 OHEM 有着更高的效率。注意:我们也尝试了 OHEM 的一些其它参数和其的变种,但并没有取得更好的结果。
Hinge Loss:
\quad \; 最后,在早期的实验中,我们尝试使用 Hinge Loss 来训练模型。在 Hinge Loss 中,当 p t p_{t} pt 大于指定值时,损失为 0。但是,这是不稳定的,并且我们也没有获得有意义的结果(好结果)。对于损失函数的探究结果见附录。
5.2. 模型架构设计
锚点框的密度(Anchor Density):
\quad \; 在 one-stage 检测算法中一个最重要的设计因素是怎么密集地覆盖图像中可能的对象边框。Two-stage 检测算法通过使用一个区域池化操作[10],能够对任何位置、尺度、宽高比的边框进行分类。相反,由于 one-stage 检测算法使用一个固定的采样网格,所以在这些方法中,一个取得高边框覆盖度的方法是在每个空间位置使用多个“锚点框”[28]来覆盖各种各样的尺度、宽高比的边框。
\quad \; 我们以扫描的形式将不同尺度、宽高比的锚点框应用于各个空间位置及 FPN 中的各个特征层次(pyramid level)。我们分析了每个位置 只有一个方形锚点框 到 12个锚点框(4种尺度 ( 2 k / 4 2^{k/4} 2k/4, for k ≤ k \leq k≤ 3 )、3种宽高比 [0.5, 1, 2])的各种情况。使用 ResNet-50 的结果见表 1c。令人惊讶的是:只使用一个方形锚点框时,竟然可以达到 30.3 的 AP。但是,当使用 3 种尺度和 3 种宽高比时(共计9个默认锚点框),AP 几乎可以提高 4 的点(to 34.0)。在本研究的所有实验中,我们都使用了这种设置。
\quad \; 最后,我们可以看到:当锚点框的数量超过 6-9 后,不能产生进一步的AP提升。锚点框的饱和(性能不能进一步提高)说明:更高密度的锚点框不能给 two-stage 检测算法带来收益。
速度和准确率的权衡(Speed versus Accuracy):
\quad \; 更大的 backbone 网络可以产生更高的准确率,但是推理速度也越低。同理,图像尺度(通过图像的窄边来定义)越大准确率越高,但推理越慢。关于上述两个因素的影响见 表 1e。在图2中,我们绘制了 RetinNet 的速度 / 准确率曲线,并且将其和最近的一些方法做了比较(数据集:COCO test-dev)。从图 2 中可以看出,RetinaNet 获得了比现有方法更高的准确率及性能。其中 600 像素尺度的 RetinaNet with ResNet-101-FPN 获得了与 ResNet-101-FPN Faster R-CNN [20] 相当的准确率,并且 RetinaNet (122ms) 推理过程比 Faster R-CNN (172ms) 快的多(都是在 Nvidia M40 GPU 上测的)。使用更大的图像尺度可以使 RetinaNet 超越 two-stage 检测算法的准确率,并且推理速度更快。为了更快的运行速度,我们使用 500 像素尺度的 ResNet-50-FPN,而不是 ResNet-101-FPN。更高帧率的检测速度可能需要特殊的网络设计 [27],这超越了本文的研究范围,不做具体讨论。我们注意到在本研究后,Faster R-CNN 的很多变种 [12] 可以获得更快、更准确的结果。
5.3. 与当前顶尖算法的对比
\quad \; 我们在 COCO 数据集上进行了评估,并在 test-dev 上和当前的顶尖算法做了对比(one-stage、two-stage)。表 2 中罗列的 RetinaNet-101-800 模型在训练中,使用了尺度抖动,获得了 1.3 的 AP 提高(Results are presented in Table 2 for our RetinaNet-101-800 model trained using scale jitter and for 1.5x longer than the models in Table 1e (giving a 1.3 AP gain))。与当前最准确的 one-stage 方法(DSSD [9])相比,RetinaNet 将 AP 提高了 5.9(39.1 vs. 33.2),并且更快(见图2)。与当前的 two-stage 方法相比,RetinaNet 比当前性能最好的 Faster R-CNN 模型(based on Inception-ResNet-v2-TDM [32])的 AP 高 2.3。将 ResNeXt-32x8d-101-FPN 作为 RestinaNet 的 backbone,可以将结果提高 1.7 AP,在 COCO 上达到了超过 40 的 AP。
6. 结论
\quad \; 在本研究中,我们发现类别不均衡是 one-stage 目标检测算法不能超越 two-stage 目标检测算法的主要原因。为了解决这个问题,我们提出了 Focal Loss,其给交叉熵引入了一个调制系数,来使得学习过程聚焦于 hard negative examples 的学习。我们的方法是简单、高效的。我们通过一个全卷积的 one-stage 检测算法来说明了其的高效,并且进行了大量的实验分析,达到了 state-of-the-art 准确率和速度。源码见:https://github.com/facebookresearch/Detectron [12]。
附录 A:Focal Loss*
\quad \; Focal Loss 的确切形式是不重要的。
我们从标准的交叉熵
附录 B:Derivatives
\quad \;
注意:欢迎大家转载,但需注明出处哦
\quad \quad \; https://blog.csdn.net/u014061630/article/details/84198098