[深度学习] 物体检测之SSD详解
SSD结构图精华版本:
![[深度学习] 物体检测之SSD详解_第1张图片](http://img.e-com-net.com/image/info8/b4877ecfad1644d29c107f06367eb991.jpg)
SSD结构图详细版本:
![[深度学习] 物体检测之SSD详解_第2张图片](http://img.e-com-net.com/image/info8/de664df8aa5a45fdb793685360dfd200.jpg)
SSD采用了特征金字塔结构进行检测,即检测时利用了conv4_3,conv_7(FC7),conv6_2,conv7_2,conv8_2,conv9_2这些大小不同的feature maps,在多个feature maps上同时进行softmax分类和位置回归。
SSD多尺度特征映射细节:
![[深度学习] 物体检测之SSD详解_第3张图片](http://img.e-com-net.com/image/info8/d24fb76836904a0cb2acdc1959e5a80e.jpg)
SSD算法中使conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2,
conv11_2这些大小不同的feature maps,其目的是为了能够准确的检测到不同尺度的物体,因为在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。
Defalut Box(Prior Box类似于anchor ):
![[深度学习] 物体检测之SSD详解_第4张图片](http://img.e-com-net.com/image/info8/0b2589a248914f2686fed7c32b959c10.jpg)
SSD中的Defalut box和Faster-rcnn中的anchor机制很相似。就是预设一些目标预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。对于不同尺度的feature map 上使用不同的Default boxes。如上图所示,我们选取的feature map包括38x38x512、19x19x1024、10x10x512、5x5x256、3x3x256、1x1x256,Conv4_3之后的feature map默认的box是4个,我们在38x38的这个平面上的每一点上面获得4个box,那么我们总共可以获得38x38x4=5776个;同理,我们依次将FC7、Conv8_2、Conv9_2、Conv10_2和Conv11_2的box数量设置为6、6、6、4、4,那么我们可以获得的box分别为2166、600、150、36、4,即我们总共可以获得8732个box,然后我们将这些box送入NMS模块中,获得最终的检测结果。
以上的操作都是在特征图上面的操作,即我们在不同尺度的特征图上面产生很多的bbox,如果将映射到原始图像中,我们会获得一个密密麻麻的bbox集合,如下图所示:
![[深度学习] 物体检测之SSD详解_第5张图片](http://img.e-com-net.com/image/info8/71ae238302094a8b9e29d9f73fcb85ab.jpg)
Prior box生成规则:
在SSD中引入了Prior Box,实际上与anchor非常类似,就是一些目标的预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。SSD按照如下规则生成prior box:
以feature map上每个点的中点为中心(offset=0.5),生成一些列同心的prior box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
正方形prior box最小边长为 ![]() ,最大边长为
,最大边长为 ![]()
每在prototxt设置一个aspect ratio,会生成2个长方形,长宽为:![]() 和
和 ![]()
![[深度学习] 物体检测之SSD详解_第6张图片](http://img.e-com-net.com/image/info8/9838a3135574421585cf1f03ce283822.jpg)
而每个feature map对应prior box的min_size和max_size由以下公式决定,公式中m是使用feature map的数量(SSD 300中m=6):
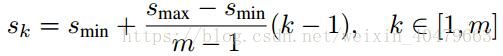
第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。在原文中,Smin=0.2,Smax=0.95。
Priorbox的使用:
知道了priorbox如何产生,接下来分析prior box如何使用。这里以conv4_3为例进行分析。
![[深度学习] 物体检测之SSD详解_第7张图片](http://img.e-com-net.com/image/info8/bef381650cb84c3a98dadaf7b7fe1ef7.jpg)
在conv4_3 feature map网络pipeline分为了3条线路:
- 经过一次batch norm+一次卷积后,生成了[1, num_class*num_priorbox, layer_height, layer_width]大小的feature用于softmax分类目标和非目标(其中num_class是目标类别,SSD 300的VOC数据集中num_class = 21)
- 经过一次batch norm+一次卷积后,生成了[1, 4*num_priorbox, layer_height, layer_width]大小的feature用于bounding box regression(即每个点一组偏移量[dxmin,dymin,dxmax,dymax])
- 生成了[1, 2, 4*num_priorbox]大小的prior box blob,其中2个channel分别存储prior box的4个点坐标和对应的4个variance. 4个variance,这实际上是一种bounding regression中的权重
后续通过softmax分类+bounding box regression即可从priox box中预测到目标。
以conv4_3 feature map分析了如何检测到目标的真实位置,但是SSD 300是使用包括conv4_3在内的共计6个feature maps一同检测出最终目标的。在网络运行的时候显然不能像图6一样:一个feature map单独计算一次softmax socre+box regression(虽然原理如此,但是不能如此实现)。那么多个feature maps如何协同工作?这时候就要用到Permute,Flatten和Concat这3种层了。Permute是SSD中自带的层,上面conv4_3_norm_mbox_conf_perm的的定义。Permute相当于交换blob中的数据维度。在正常情况下blob的顺序为:
bottom blob = [batch_num, channel, height, width]
经过conv4_3_norm_mbox_conf_perm后的blob为:
top blob = [batch_num, height, width, channel]
而Flattlen和Concat层都是自带层.所有操作相当于各层输出中把channel放到了最后一个维度然后逆序相乘再总的相加。
Feature map合并方法:
![[深度学习] 物体检测之SSD详解_第8张图片](http://img.e-com-net.com/image/info8/bdc1d7f87e9f45faad388f50a2aaf994.jpg)
以conv4_3和fc7为例分析SSD是如何将不同size的feature map组合在一起进行prediction。图展示了conv4_3和fc7合并在一起的过程中shape变化(其他层类似)。
对于conv4_3 feature map,conv4_3_norm_priorbox(priorbox层)设置了每个点共有4个prior box。由于SSD 300共有21个分类,所以conv4_3_norm_mbox_conf的channel值为num_priorbox * num_class = 4 * 21 = 84;而每个prior box都要回归出4个位置变换量,所以conv4_3_norm_mbox_loc的channel值为4 * 4 = 16。
fc7每个点有6个prior box,其他feature map同理。
经过一系列图展示的shape变化后,最后拼接成mbox_conf和mbox_loc。而mbox_conf后接reshape,再进行softmax(为何在softmax前进行reshape,Faster RCNN有提及)。
最后这些值输出detection_out_layer,获得检测结果
Loss计算:
![]()
对于SSD,虽然paper中指出采用了所谓的“multibox loss”,但是依然可以清晰看到SSD loss分为了confidence loss和location loss两部分,其中N是match到GT(Ground Truth)的prior box数量;而α参数用于调整confidence loss和location loss之间的比例,默认α=1。
SSD中的confidence loss是典型的softmax loss:
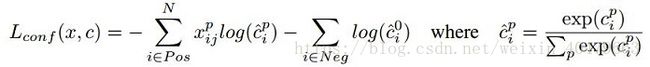
其中![]() 代表第i个prior box匹配到了第j个class为p类别的GT box;
代表第i个prior box匹配到了第j个class为p类别的GT box;
而location loss是典型的smooth L1 loss:
![[深度学习] 物体检测之SSD详解_第9张图片](http://img.e-com-net.com/image/info8/36a39895891f483ca63608d40e412e14.jpg)
提高精度的方法:
-
Matching strategy(匹配策略):
缩进在训练时,groundtruth boxes 与 default boxes(就是prior boxes) 按照如下方式进行配对:
首先,寻找与每一个ground truth box有最大的jaccard overlap的default box,这样就能保证每一个groundtruth box与唯一的一个default box对应起来(所谓的jaccard overlap就是IoU)。
SSD之后又将剩余还没有配对的default box与任意一个groundtruth box尝试配对,只要两者之间的jaccard overlap大于阈值,就认为match(SSD 300 阈值为0.5)。
显然配对到GT的default box就是positive,没有配对到GT的default box就是negative。只有正样本才会参与loss的计算。 -
Hard negative mining:
值得注意的是,一般情况下negative default boxes数量>>positive default boxes数量,直接训练会导致网络过于重视负样本,从而loss不稳定。因此需要平衡正负样本的个数,我们常用的方法就是Hard Ngative Mining,即依据confidience score对default box进行排序,挑选其中confidience高的box进行训练,将正负样本的比例控制在positive:negative=1:3。这样会取得更好的效果。如果我们不加控制的话,很可能会出现Sample到的所有样本都是负样本(即让网络从这些负样本中找正确目标,这显然是不可以的),这样就会使得网络的性能变差。 -
Data augmentation:
数据增广,即每一张训练图像,随机的进行如下几种选择:
- 使用原始的图像
- 采样一个 patch,与物体之间最小的 jaccard overlap 为:0.1,0.3,0.5,0.7 或 0.9
- 随机的采样一个 patch,采样的 patch 是原始图像大小比例是[0.1,1],aspect ratio在 1/2与2之间。当 groundtruth box 的 中心(center)在采样的patch中时,保留重叠部分。在这些采样步骤之后,每一个采样的patch被resize到固定的大小,并且以0.5的概率随机的 水平翻转(horizontally flipped)。
其实Matching strategy,Hard negative mining,Data augmentation,都是为了加快网络收敛而设计的。尤其是Data augmentation,翻来覆去的randomly crop,保证每一个prior box都获得充分训练而已。不过当数据达到一定量的时候,不建议再进行Data augmentation,毕竟“真”的数据比“假”数据还是要好很多。
训练结果(后续会附上源码详解):
训练迭代了130K次,学习率为0.001(出现跳跃是因为之前没有加入VGG16的checkpoint),可以发现在100K次之后基本没有太大变化趋于收敛状态,最后第130K次时候的loss=3.4。
![[深度学习] 物体检测之SSD详解_第10张图片](http://img.e-com-net.com/image/info8/809708feef2c453983ed3af8d2317fad.jpg)
其中用于softmax分类的cross_entrpy和localization的loss也基本收敛以及正负样本个数 如下变化:
![[深度学习] 物体检测之SSD详解_第11张图片](http://img.e-com-net.com/image/info8/69063a98a99f4cc9a6cb4e62830d2cfb.jpg)
训练后SSD300在VOC2007的mAP为62%,论文中为68%。
![]()
论文各种算法mAP在VOC2007和VOC2012上的比较:
![[深度学习] 物体检测之SSD详解_第12张图片](http://img.e-com-net.com/image/info8/2a63e45437914b5c9cdc095c17827278.jpg)
Demo:(类别 | 概率)
对于大目标检测效果比较理想:
![[深度学习] 物体检测之SSD详解_第13张图片](http://img.e-com-net.com/image/info8/a3e530aa73924f5d98318cd5a61b4549.jpg)
![[深度学习] 物体检测之SSD详解_第14张图片](http://img.e-com-net.com/image/info8/f4d0615daef54f8c90eeed4b52ead682.jpg)
对于小目标识别不是很好甚至无法检测:
![[深度学习] 物体检测之SSD详解_第15张图片](http://img.e-com-net.com/image/info8/22abdb3b60134f3dbd67618b206397b0.jpg)
![[深度学习] 物体检测之SSD详解_第16张图片](http://img.e-com-net.com/image/info8/10d9e908032e4dac8731f9163bf71898.jpg)
总结:
- SSD300速度比较快但是精度不高,SSD512的可以在精度上领先Faster-Rcnn,而且在速度上领先YOLO。
- 需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。
- 对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。