python数据分析:客户价值分析案例实战
简介:本案例以电信运营商客户信息为数据,通过层次聚类和K-means聚类,对用户划分成不同的群体,然后可以根据用户群体的不同特征提供个性化的策略,从而达到提高ARPU的效果。
1.商业理解
根据客户的日常消费行为,我们可以把客户划分为不同的群体,根据不同群体的消费行为特征,我们可以作出针对性的营销策略。从而达到发展新业务、减少客户流失率,争取新用户,提高ARPU的目标
对运营商用户的分类,一般可以分为:
公众用户
企业用户
大客户
本次针对公众用户进行划分,目标将“公众用户”分类为:
高端用户
中端用户
离网趋势用户
其他用户
2.展示数据
本次采用的数据有:
客户的个人信息
客户的通话信息
各资费套餐的详情

3.数据预处理
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.cluster.hierarchy#聚类、层次
#读入数据
custinfo=pd.read_csv("custinfo.csv")
custcall=pd.read_csv("custcall.csv")
#数据聚合
custcall_average=custcall.groupby(custcall["Customer_ID"]).mean()
del custcall_average["month"]
#数据合并
data = pd.merge(custinfo,custcall_average,left_on='Customer_ID',right_index=True)#使用右边dataframe的索引值作为连接键
data.index=data["Customer_ID"]
del data["Customer_ID"]4.数据观察
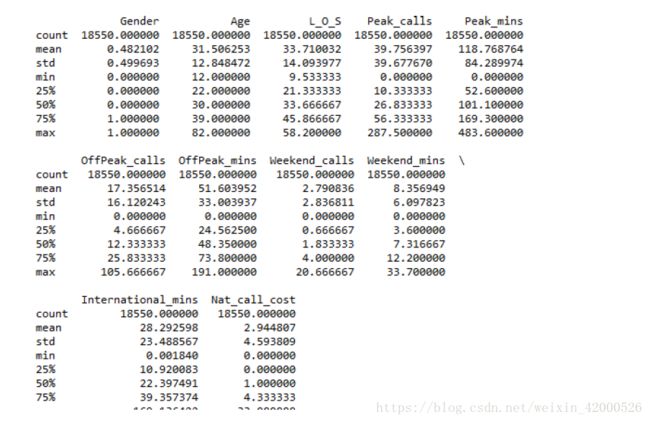
des=data.describe()
#查看取值离散变量的分布
pd.value_counts(data["Gender"]) #查看性别分布
pd.value_counts(data['Tariff'])#套餐
pd.value_counts(data['Handset'])#手机品牌
for i in data.columns:
if i not in ['Gender','Tariff','Handset']:
plt.figure()
sns.distplot(data[i],bins=10,hist_kws=dict(edgecolor='k'),kde=False)
plt.show()
5.模型建立
#模型建立
#数据整理
xunibinaliang=data[["Gender",'Tariff','Handset']]
dummies=pd.get_dummies(xunibinaliang) #将类别变量转为虚拟变量,gender为二值型,get_dummies处理后还是一列
data_zs=pd.DataFrame
i=data.columns.difference([u'Age',u'Gender',u'Tariff',u'Handset']) #一维数组做差
data_zs=(data[i]-data[i].mean())/data[i].std()#确定聚类数目
from scipy.cluster.hierarchy import linkage,dendrogram
#进行层次聚类
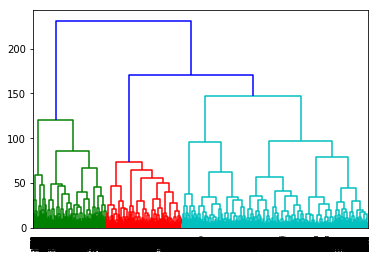
Z = linkage(data_zs, method = 'ward', metric = 'euclidean')
P = dendrogram(Z, 0) #将层级聚类结果以树状图表示出来 dendrogram-树图
plt.show()#观察树图,认为分成4类比较合适
#K-means聚类
#参数初始化
k = 4 #聚类的类别
iteration = 500 #聚类最大循环次数,即迭代次数
#构建k-means模型
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4,max_iter=iteration) #构造聚类器,分为k类,并发数4
model.fit(data_zs) #开始聚类6.数据展示
#简单打印结果
r1 = pd.Series(model.labels_).value_counts() #label_:每个样本对应的簇类别标签,统计各个类别的数目
r3=model.labels_
r2 = pd.DataFrame(model.cluster_centers_) #行为每一类的聚类中心,每一列的意义是按照data_zs
r4=model.cluster_centers_
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data_zs.columns)+ [u'class'] #重命名表头#这里传入的列表名必须list
print(r)
#类中心比较
r[i].plot(figsize=(10,10))
plt.show()
#每个类别各属性的概率密度图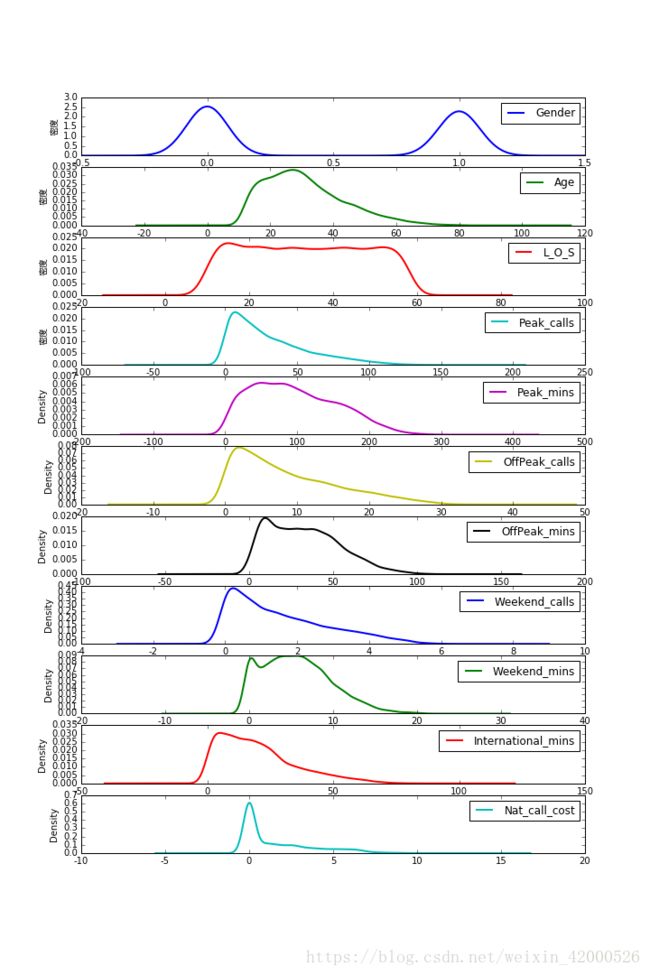
分群的注意点:
1)群间差异是否明显
2)群内特征是否相似
3)分群对业务是否有指导意义