通过数据分析带你揭秘如何年薪30W
被骗进来了吧,这其实是个KNN算法的小练习=3=
要求:读取adult.txt文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50k美元。获取年龄、教育程度、职位、每周工作时间作为机器学习数据,获取薪水作为对应结果。
准备工作
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
import matplotlib.pyplot as plt
%matplotlib inline
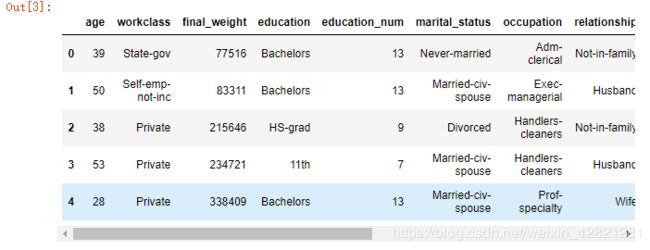
(1)加载数据
shouru=pd.read_csv('./adults.txt')
shouru.head()
(2)如果用knn算法,特征必须是数字,所以要把字符串特征转成数字量化
shouru.shape

shouru.columns

shouru.dtypes

(3)先将标签数据取出
target=shouru[['salary']].copy()
target.head()

(4)将所有不符合的特征取出进行量化(np.map() np.argwhere() )
(注:map函数用来映射,argwhere: 查找按元素分组的非零的数组元素的索引)
cols=[ 'workclass','education','marital_status', 'occupation', 'relationship', 'race', 'sex', 'native_country']
for col in cols:
uni=data[col].unique()
def convert(item):
index=np.argwhere(uni==item)[0][0]
return index
data[col]=data[col].map(convert)
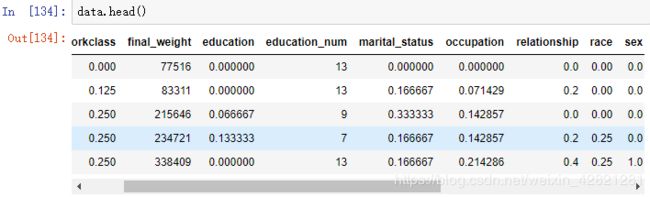
data.head()

全部转化,没有丢失数据
(5)对特征数据和标签数据进行切分
x_train:用于训练的数据 x_test:用于测试的数据 y_train:用于训练的特征 y_test:用于测试的特征(真实结果)
x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.1)
(6)创建算法模型训练数据(neighbors不大于20)
knn=KNeighborsClassifier(n_neighbors=10)
knn.fit(x_train,y_train)

(7)预测结果
y_=knn.predict(x_test)
y_[:10]#(预测结果)
![]()
y_test[:10]#(真实结果)

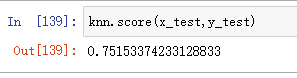
(8)性能测试
knn.score(x_test,y_test)
![]()
(9)改善性能
方案一: 提高数据的质量,量化的时候可以采取进一步的归一化
#对量化后的数据进一步的归一化(可以减小误差)
def func(x):
return (x - min(x)) / (max(x)-min(x))
cols=[ 'workclass','education','marital_status', 'occupation', 'relationship', 'race', 'sex', 'native_country']
data[cols] = data[cols].transform(func)
重新训练数据进行性能测试后,数据有所下降。。。。
方案二: 算法上k-近邻可以通过取最优的k值 ,也可以采取其他算法