Hive进阶之Hive数据导入
使用load语句导入数据
-语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE table name [PARTITION (partcoll=vall,partcol=val2 ...)]
如:
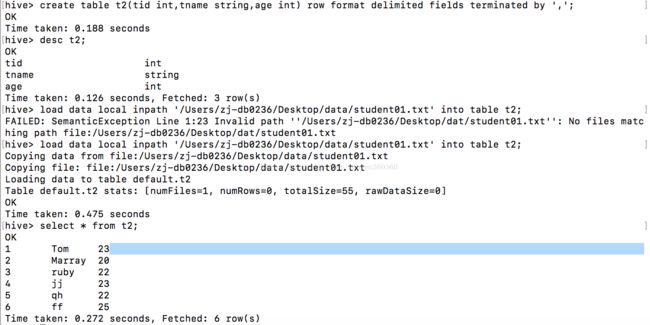
注意如果创建表的时候没有规定分隔符那它默认是制表符(\t),而你导入的数据以','分隔,那便会成为空值如下所示:
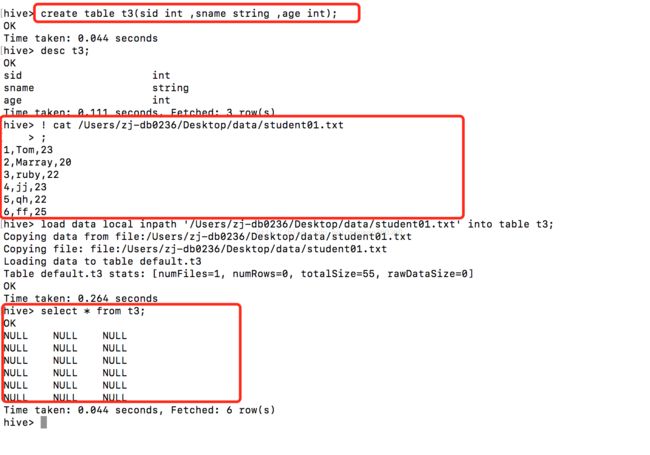
导入目录下的所有文件数据
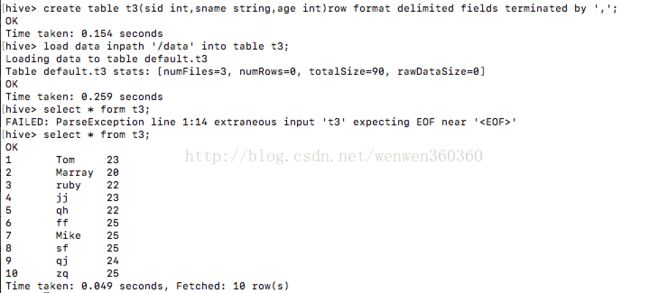
注意不写local代表从hdfs中导入
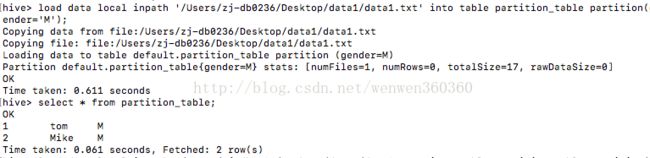
将数据导入分区
使用Sqoop实现关系型数据库数据导入
下载地址
http://sqoop.apache.org/
sqoop安装请看sqoop安装篇
将mysql中的数据导入到hdfs中
注意了sqoop是在命令行中执行不是在hive中执行,我之前一直在hive中执行结果一直给我报这样的错
hive> sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table trade_detail --hive-import --hive-overwrite --hive-table trade_detail --fields-terminated-by',';
NoViableAltException(26@[])
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:999)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:199)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:166)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:373)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:291)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:944)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1009)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:880)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:870)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:268)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:220)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:423)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:792)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:686)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:625)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
FAILED: ParseException line 1:0 cannot recognize input near 'sqoop' 'import' '' zj-db0236deMacBook-Pro:sbin zj-db0236$ sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table trade_detail --hive-import --hive-overwrite -m 1 --hive-table trade_detail --fields-terminated-by ','
Warning: /Users/zj-db0236/Downloads/sqoop-1.4.6.bin__hadoop-0.23/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /Users/zj-db0236/Downloads/sqoop-1.4.6.bin__hadoop-0.23/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /Users/zj-db0236/Downloads/sqoop-1.4.6.bin__hadoop-0.23/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /Users/zj-db0236/Downloads/sqoop-1.4.6.bin__hadoop-0.23/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/06/27 15:25:35 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/06/27 15:25:35 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/06/27 15:25:35 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/06/27 15:25:35 INFO tool.CodeGenTool: Beginning code generation
17/06/27 15:25:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `trade_detail` AS t LIMIT 1
17/06/27 15:25:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `trade_detail` AS t LIMIT 1
17/06/27 15:25:35 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /Users/zj-db0236/Downloads/hadoop-2.7.2
注: /tmp/sqoop-zj-db0236/compile/da5649c40aae421516a4a7b09474d590/trade_detail.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
17/06/27 15:25:36 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-zj-db0236/compile/da5649c40aae421516a4a7b09474d590/trade_detail.jar
17/06/27 15:25:36 WARN manager.MySQLManager: It looks like you are importing from mysql.
17/06/27 15:25:36 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
17/06/27 15:25:36 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
17/06/27 15:25:36 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
17/06/27 15:25:36 INFO mapreduce.ImportJobBase: Beginning import of trade_detail
17/06/27 15:26:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/06/27 15:26:07 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/06/27 15:26:08 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/06/27 15:26:08 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/06/27 15:26:10 INFO db.DBInputFormat: Using read commited transaction isolation
17/06/27 15:26:10 INFO mapreduce.JobSubmitter: number of splits:1
17/06/27 15:26:10 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1498547617140_0002
17/06/27 15:26:10 INFO impl.YarnClientImpl: Submitted application application_1498547617140_0002
17/06/27 15:26:10 INFO mapreduce.Job: The url to track the job: http://zj-db0236deMacBook-Pro.local:8088/proxy/application_1498547617140_0002/
17/06/27 15:26:10 INFO mapreduce.Job: Running job: job_1498547617140_0002
17/06/27 15:26:48 INFO mapreduce.Job: Job job_1498547617140_0002 running in uber mode : false
17/06/27 15:26:49 INFO mapreduce.Job: map 0% reduce 0%
17/06/27 15:27:24 INFO mapreduce.Job: map 100% reduce 0%
17/06/27 15:27:24 INFO mapreduce.Job: Job job_1498547617140_0002 completed successfully
17/06/27 15:27:24 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=137758
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=119
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=33155
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=33155
Total vcore-milliseconds taken by all map tasks=33155
Total megabyte-milliseconds taken by all map tasks=33950720
Map-Reduce Framework
Map input records=5
Map output records=5
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=41
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=149422080
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=119
17/06/27 15:27:24 INFO mapreduce.ImportJobBase: Transferred 119 bytes in 76.2361 seconds (1.5609 bytes/sec)
17/06/27 15:27:24 INFO mapreduce.ImportJobBase: Retrieved 5 records.
17/06/27 15:27:24 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `trade_detail` AS t LIMIT 1
17/06/27 15:27:24 INFO hive.HiveImport: Loading uploaded data into Hive
17/06/27 15:27:26 INFO hive.HiveImport:
17/06/27 15:27:26 INFO hive.HiveImport: Logging initialized using configuration in jar:file:/Users/zj-db0236/Downloads/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
17/06/27 15:28:00 INFO hive.HiveImport: OK
17/06/27 15:28:00 INFO hive.HiveImport: Time taken: 0.679 seconds
17/06/27 15:28:00 INFO hive.HiveImport: Loading data to table default.trade_detail
17/06/27 15:28:01 INFO hive.HiveImport: rmr: DEPRECATED: Please use 'rm -r' instead.
17/06/27 15:28:01 INFO hive.HiveImport: Deleted hdfs://localhost:9000/user/hive/warehouse/trade_detail
17/06/27 15:28:01 INFO hive.HiveImport: Table default.trade_detail stats: [numFiles=2, numRows=0, totalSize=119, rawDataSize=0]
17/06/27 15:28:01 INFO hive.HiveImport: OK
17/06/27 15:28:01 INFO hive.HiveImport: Time taken: 0.456 seconds
17/06/27 15:28:01 INFO hive.HiveImport: Hive import complete.
注意了:如果没有-m 1代表map启动1个如果不加这一句那么每条数据都会启动一个map最后你有多少条数据就会有多少分区,这样很浪费空间
sqoop指定参数说明
--append |
将数据追加到hdfs中已经存在的dataset中。使用该参数,sqoop将把数据先导入到一个临时目录中,然后重新给文件命名到一个正式的目录中,以避免和该目录中已存在的文件重名。 | ||||||||||||||||||||||||||||||||
--as-avrodatafile |
将数据导入到一个Avro数据文件中 | ||||||||||||||||||||||||||||||||
--as-sequencefile |
将数据导入到一个sequence文件中 | ||||||||||||||||||||||||||||||||
--as-textfile |
将数据导入到一个普通文本文件中,生成该文本文件后,可以在hive中通过sql语句查询出结果。 | ||||||||||||||||||||||||||||||||
--boundary-query |
边界查询,也就是在导入前先通过SQL查询得到一个结果集,然后导入的数据就是该结果集内的数据,格式如:--boundary-query 'select id,no from t where id = 3',表示导入的数据为id=3的记录,或者 select min( |
