面试准备-java【1】
1、HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)
HashMap线程不安全,hashmap允许key,value为null
hashtable线程安全,方法加synchronized,不允许value为null
HashMap多线程get不安全,多线程扩容阶段中,rehash步骤不安全
http://www.importnew.com/22011.html
concurrentHashMap:
1.7版本,采用segment分段锁,一个hashmap中有多个segment,每个segment存放多个k-v桶(数组),每个数组后面是链表。锁是加在每个segment上。
1.8版本,锁的粒度更细了,去掉了segment,直接加在链表的表头,整体结构和普通的hashMap没差别,使用volatile保证可见性。同时在初始化,以及定位到相应数组位置时量表为空的特殊情况下,使用CAS无锁操作。链表长度超过阈值,也会进行树化。
2、HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
链表长度超过8采用红黑树,resize的时候不是重新计算hash,而是用hash&oldCap(数组容量)来判断是在原位置,还是移动到oldCap+oldIndex位置
http://www.importnew.com/22011.html
http://www.importnew.com/20386.html
https://my.oschina.net/hosee/blog/618828
3、final finally finalize
final 用于声明属性,方法和类, 分别表示属性不可变(不可重新赋值), 方法不可覆盖, 类不可继承。可以增强代码的可读性,明确哪些代码是不可被修改的,一定程度上增加平台的稳定性。
匿名内部类,引用局部变量,局部变量为什么用final修饰:内部类引用局部变量不是直接引用,而是copy一份,用final修饰,可以减少数据一致性问题
finally 是异常处理语句结构的一部分,表示总是执行。对于需要关闭的连接等资源,使用try-with-resources语句。
finalize 是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等. JVM不保证此方法总被调用。不推荐使用,java9中,该方法被标注为deprecated
4、强引用 、软引用、 弱引用、虚引用
https://blog.csdn.net/mazhimazh/article/details/19752475
5、try catch finally 的执行顺序
先执行try或catch里里面的代码,然后再执行finally,再执行try或catch里面的return.基础数据类型finally的修改不影响return,如果是返回对象,因为返回对象的引用,finally的修改会影响。
6、cloneable接口实现原理
cloneable只是一个接口,需要实现接口,重写Object的clone方法,此时是浅拷贝,复制属性,对于对象属性是拷贝引用
深拷贝,被克隆的对象以及对象属性要实现Serializable,用ByteArrayOutputStream,ObjectOutputStream,ObjectInputStream 复制属性
https://blog.csdn.net/boonya/article/details/70849997
7、异常分类以及处理机制
https://www.cnblogs.com/lulipro/p/7504267.html
8、wait和sleep的区别
1、首先,要记住这个差别,“sleep是Thread类的方法,wait是Object类中定义的方法”。尽管这两个方法都会影响线程的执行行为,但是本质上是有区别的。
2、Thread.sleep不会导致锁行为的改变,如果当前线程是拥有锁的,那么Thread.sleep不会让线程释放锁。如果能够帮助你记忆的话,可以简单认为和锁相关的方法都定义在Object类中,因此调用Thread.sleep是不会影响锁的相关行为。
3、Thread.sleep和Object.wait都会暂停当前的线程,对于CPU资源来说,不管是哪种方式暂停的线程,都表示它暂时不再需要CPU的执行时间。OS会将执行时间分配给其它线程。区别是,调用wait后,需要别的线程执行notify/notifyAll才能够重新获得CPU执行时间。
9、数组在内存中如何分配
数组是一种引用数据类型,栈内存保存堆内存的引用,对内存分配连续内存存储数据,如果是对象,那么连续内存里存的是对象的引用
10、抽象类和接口有什么区别
接口是公开的,里面不能有私有的方法或变量,是用于让别人使用的,而抽象类是可以有私有方法或私有变量的,
另外,实现接口的一定要实现接口里定义的所有方法,而实现抽象类可以有选择地重写需要用到的方法,一般的应用里,最顶级的是接口,然后是抽象类实现接口,最后才到具体类实现。
还有,接口可以实现多重继承,而一个类只能继承一个超类,但可以通过继承多个接口实现多重继承,接口还有标识(里面没有任何方法,如Remote接口)和数据共享(里面的变量全是常量)的作用。
11、synchronized 的实现原理以及锁优化?
jvm完成同步,在编译阶段加入相应的代码。
3: monitorenter //进入同步方法
//..........省略其他
15: monitorexit //退出同步方法
16: goto 24//跳到24行
//省略其他.......
21: monitorexit //退出同步方法
类似于try{lock,unlock}catchException{}finally{unlock},所以有两次monitorexit
https://blog.csdn.net/Thousa_Ho/article/details/77992743
https://blog.csdn.net/javazejian/article/details/72828483#理解java对象头与monitor
12、synchronized 在静态方法和普通方法的区别?
https://blog.csdn.net/u010842515/article/details/65443084
13、synchronized 和 lock 有什么区别?
synchronized是jvm用指令控制,发生异常会自动释放锁,但是如果线程拿不到锁会一直等待,自旋和适应性自旋
lock是类,锁的获取释放由开发者自己控制,如果发生异常没有释放锁,有可能死锁,利用condition对象,可以实现不同条件,不同粒度的锁操作
https://juejin.im/post/5a43ad786fb9a0450909cb5f
https://blog.csdn.net/u012403290/article/details/64910926
14、Java 的信号灯?
https://blog.csdn.net/u012758088/article/details/70312490
15、怎么实现所有线程在等待某个事件的发生才会去执行?
https://blog.csdn.net/jiyiqinlovexx/article/details/51236323
16、CountDownLatch 和 CyclicBarrier 的用法,以及相互之间的差别?
CountDownLatch,某些线程await之后,等待计数减为0,然后执行,计数只有初始化时候可以设置,相当于该对象不可重用
CyclicBarrier ,通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用。我们暂且把这个状态就叫做barrier,当调用await()方法之后,线程就处于barrier了,等所有线程await之后,线程可以继续工作,也可以指定CyclicBarrier在所有线程await之后做什么操作
https://www.cnblogs.com/dolphin0520/p/3920397.html
17、CAS?CAS 有什么缺陷,如何解决?
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
缺点主要是ABA问题,循环时间开销大和只能保证一个共享变量
1.ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
ABA问题的解决思路就是使用版本号
在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。
这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等
18、线程池的种类,区别和使用场景?
都是使用了ThreadPoolExecutor类,通过设置不同的参数来达到下列线程池。
关键参数:corePoolSize:线程池大小
maximumPoolSize:如果任务过多额外生成线程可以达到的总数
largestPoolSize:记录曾经达到的最大线程数目
keepAliveTime:线程空闲时的存活时间,即当线程没有任务执行时,继续存活的时间;默认情况下,该参数只在线程数大于corePoolSize时才有用;
阻塞队列
饱和策略:ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常;
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常;
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程);
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务;
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
https://blog.csdn.net/u011974987/article/details/51027795
19、分析线程池的实现原理和线程的调度过程?
1、如果线程总数目小于corePoolSize,新建线程执行。
2、如果大于corePoolSize且线程池处于RUNNING状态,就放入队列;如果不成功,那么就用饱和策略执行;如果放入队列成功,做第二次线程池状态校验,可能要做回滚,用饱和策略执行;不回滚情况下,addWorker。
3、addWork失败,用饱和策略执行。
ThreadFactory创建线程,HashSet保存工作线程,ctl(AutomaticInteger)保存线程池运行状态及当前线程数目,二进制方法。
https://www.jianshu.com/p/117571856b28
https://www.jianshu.com/p/87bff5cc8d8c
20、线程池如何调优,最大数目如何确认?
查看largestPoolSize
按照不同业务或者任务,设置业务独有的线程池,线程池满不影响其他业务
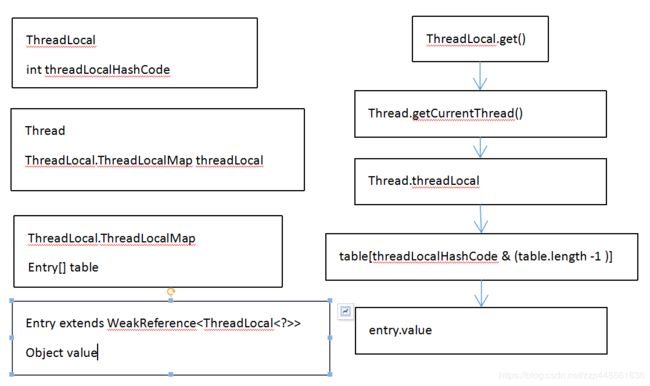
21、ThreadLocal原理,用的时候需要注意什么?
在当前线程中,任何一个点都可以访问到ThreadLocal的值。该线程的ThreadLocal只能被该线程访问,一般情况下其他线程访问不到。
不是ThreadLocal保存了各个Thread的数据,而是Thread保存了各个ThreadLocal的引用和数据
Thread类有属性是ThreadLocal.ThreadMap,当ThreadLocal.get()获取不到ThreadLocal.ThreadMap或者ThreadLocal.set()设置数据时候,初始化Thread中的ThreadLocal.ThreadMap。
ThreadMap是Entry[]数组,Entry的value是ThreadLocal.set()设置的值,并持有ThreadLocal的弱引用,所以ThreadLocal并不会产生内存泄露,因为当Thread被回收时,ThreadLocal的弱引用也被回收了
当使用ThreadLocal.get()的时候,获取当前线程的ThreadMap,用当前ThreadLocal去ThreadMap中获取存储的数据。
ThreadLocal的弱引用在ThreadMap的entry数组中的位置是根据threadLocal一个static修饰的公用的AutomicInteger参数,原子自增后赋值给threadlocal中的一个final对象。然后对entry数组大小做&操作确定位置。所以各个ThreadLocal的位置不一样。
ThreadLocal的弱引用的回收依赖于显式的触发或者等待线程执行结束,这就有可能造成OOM,而且不要和线程池配合,worker线程一般不会主动退出
https://droidyue.com/blog/2016/03/13/learning-threadlocal-in-java/
22、Java反射
Java反射机制主要提供了以下功能:在运行时构造一个类的对象;判断一个类所具有的成员变量和方法;调用一个对象的方法;生成动态代理。反射最大的应用就是框架
Java反射的主要功能:
1)确定一个对象的类
2)取出类的modifiers,数据成员,方法,构造器,和超类.
3)找出某个接口里定义的常量和方法说明.
4)创建一个类实例,这个实例在运行时刻才有名字(运行时间才生成的对象).
5)取得和设定对象数据成员的值,如果数据成员名是运行时刻确定的也能做到.
6)在运行时刻调用动态对象的方法.
7)创建数组,数组大小和类型在运行时刻才确定,也能更改数组成员的值.
反射的应用很多,很多框架都有用到
spring 的 ioc/di 也是反射….
javaBean和jsp之间调用也是反射….
struts的 FormBean 和页面之间…也是通过反射调用….
JDBC 的 classForName()也是反射……
hibernate的 find(Class clazz) 也是反射….
反射还有一个不得不说的问题,就是性能问题,大量使用反射系统性能大打折扣。
23、LinkedHashMap的应用
有序,entry是双向链表,head,tail
https://www.jianshu.com/p/8f4f58b4b8ab
24、volatile 的实现原理?
可见性,有序性,不保证原子性
单例模式,双重检查问题
25、阻塞队列
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。 不保证同优先的元素的顺序
DelayQueue:一个使用优先级队列实现的无界阻塞队列。 指定延时多久才能从队列中获取元素
SynchronousQueue:一个不存储元素的阻塞队列。 每一个put操作必须等待一个take操作,否则不能继续添加元素。队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue的吞吐量高于LinkedBlockingQueue 和 ArrayBlockingQueue。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。在初始化LinkedBlockingDeque时可以设置容量防止其过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中
https://blog.csdn.net/itachi85/article/details/52036684