fastText(二):微博短文本下fastText的应用(一)
众所周知,微博中的内容以短文本居多,文本内容随意性极强,这给建模增加了很大的难度。针对这一问题,这里分享一下fastText在微博短文本的应用。
任务目标
简单介绍一下整个任务的目标:给微博内容打上标签,例如美妆、宠物用品等。这类问题可以转化为经典的多分类问题。然而微博内容较短,并且文字随意性极强,这给整个建模任务增加了难度。考虑到文本分类是一类偏线性的问题,本次建模使用了fastText。另外,值得注意的是,fastText能够产生词向量,它可以帮助我们理解数据。
标注
在真实场景下,监督学习是文本分类任务最靠谱的方法(PS:标注是一件苦差事,哈哈…..)。不同于学术研究,绝大部分的实际场景没有现成的标注数据。因此,要训练一个可用的分类器,数据标注是必不可少的步骤,并且要达到以下几个要求:
- 覆盖率(Coverage):在真实场景下,分类体系涉及上百个类目,标注数据需要覆盖这些类目。
- 准确性(Precision):标注类目基本符合文本描述。
- 一致性(Consistency):标注数据的词分布与真实数据保持一致。
在上述要求中,重点讲一下一致性。在监督学习中,线上和线下数据分布不一致是导致上线效果血崩的重要原因。在文本分类中,词分布是衡量两个数据集是否一致的重要指标。因此,标注数据的词分布应尽可能与真实数据保持一致。为了量化衡量词分布的不同,这里使用Jensen-Shannon distance(JS)来衡量两个分布,计算公式如下所示:
其中 P P 代表标注数据的词分布, Q Q 代表真实数据的词分布, V V 代表训练集词典大小, DKL(P||Q) D K L ( P | | Q ) 代表KL散度, M=12(P+Q) M = 1 2 ( P + Q ) 。
根据上述三个指标,数据标注的流程可以表示为:

通过上述流程,标注数据的JS值最终达到0.107,近似等价于:
由上可知,标注数据和真实数据的词分布已基本一致,接下来就开始建模。
建模
在微博短文本的场景下,关键词往往能代表整个句子的含义。在产出标注数据时,关键词匹配也是主要的规则。然而,人制定的关键词规则是有限的,不能涵盖所有情况。因此fastText的训练目标是:
- 学到人制定的关键词规则
- 扩展出一些新的规则
为了验证fastText对已有规则的学习程度,这里将标注数据按照8:2的方式将数据切分为训练数据和验证数据。在训练fastText时,选择的参数如下所示:
| 参数名 | 数值 |
|---|---|
| dim | 120 |
| lr | 0.3 |
| wordNgrams | 3 |
| minCount | 30 |
| bucket | 10000000 |
| epoch | 100 |
最终在验证集的准确率达到98.5%,证明fastText基本学会了人制定的规则。接下来需要验证fastText的扩展性。这里使用训练好的fastText预测一天的广告微博(未参与训练),并通过人工判断模型的预测效果。出乎意料,模型对真实数据的预测效果完全血崩,其中较为凸出的例子是:
- 你现在最困扰的皮肤问题是_?
- 拍这样一套 艺术中国风婚照 多少钱??!
上面两个微博,显然属于“祛痘”和“婚纱摄影”,但它们的预测类目与真实类目差了十万八千里。面对这个问题,首先想到的问题是模型训练有误。考虑到关键词往往能够代表整个文本的含义,而fastText可以给每个词一个vector表示,因此关键词的近义词质量可以用来判断模型训练效果。以此为基础,使用cosine similarity计算了皮肤问题和婚照的近义词,结果如下:
皮肤问题:
痘坑 0.974714
粗大 0.961591
痘痘 0.956858
暗疮 0.953522
缺水 0.95262
祛痘 0.950534
只收 0.926314
痤疮 0.92352
黑头 0.922379
长痘 0.915288婚照:
造 0.918399
婚纱照 0.915666
全送 0.901924
金夫人 0.882709
样片 0.866033
客片 0.860637
相册 0.850072
底片 0.845974
抢订 0.84424
拍一套 0.808705从上述结果可以看出,fastText在分类的同时,兼顾了关键词的相似度,因此模型训练基本没有问题。当模型训练基本没有差错时,问题可能出在标注数据上,为此统计了“皮肤问题”和“婚照”在训练集的分布情况:
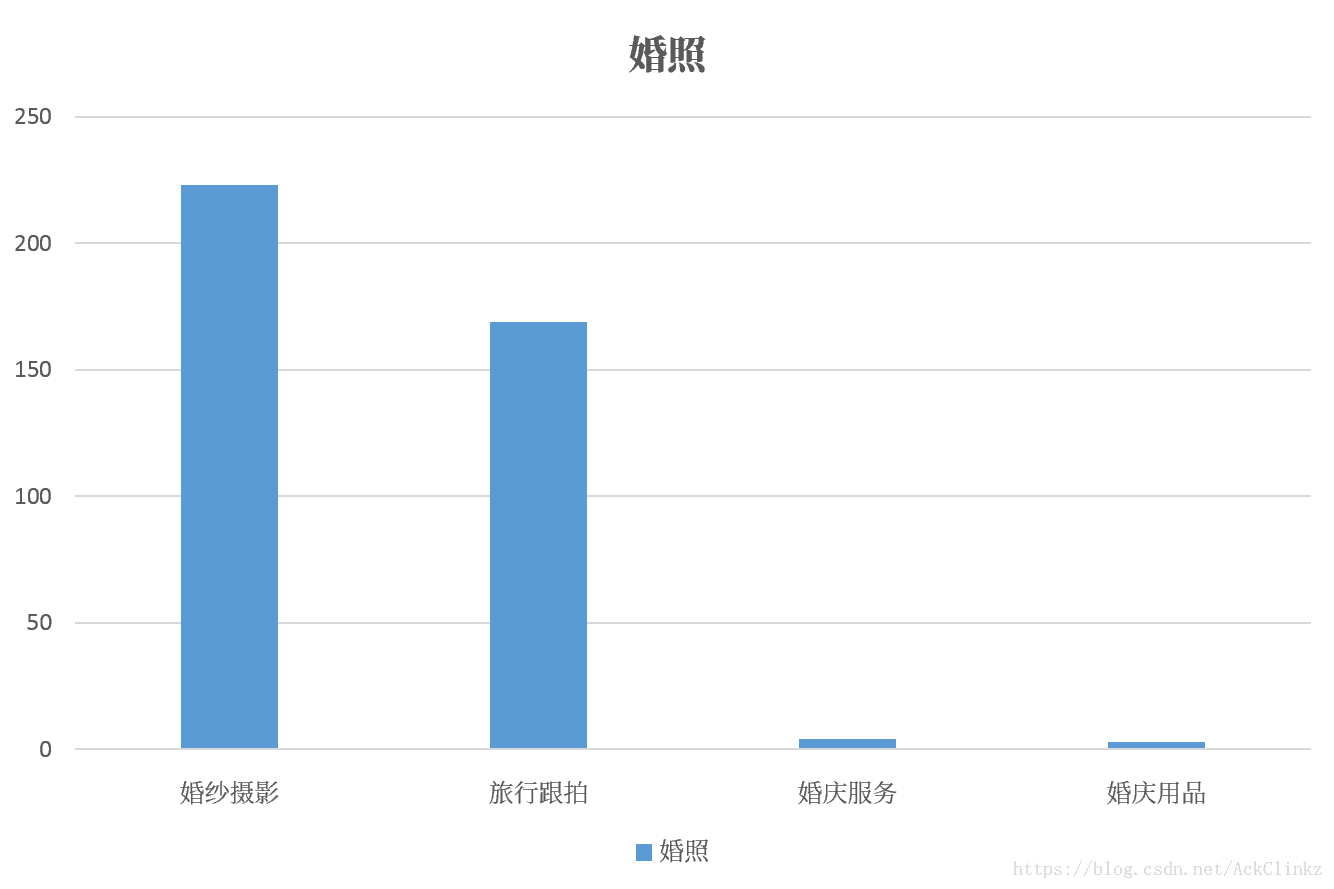
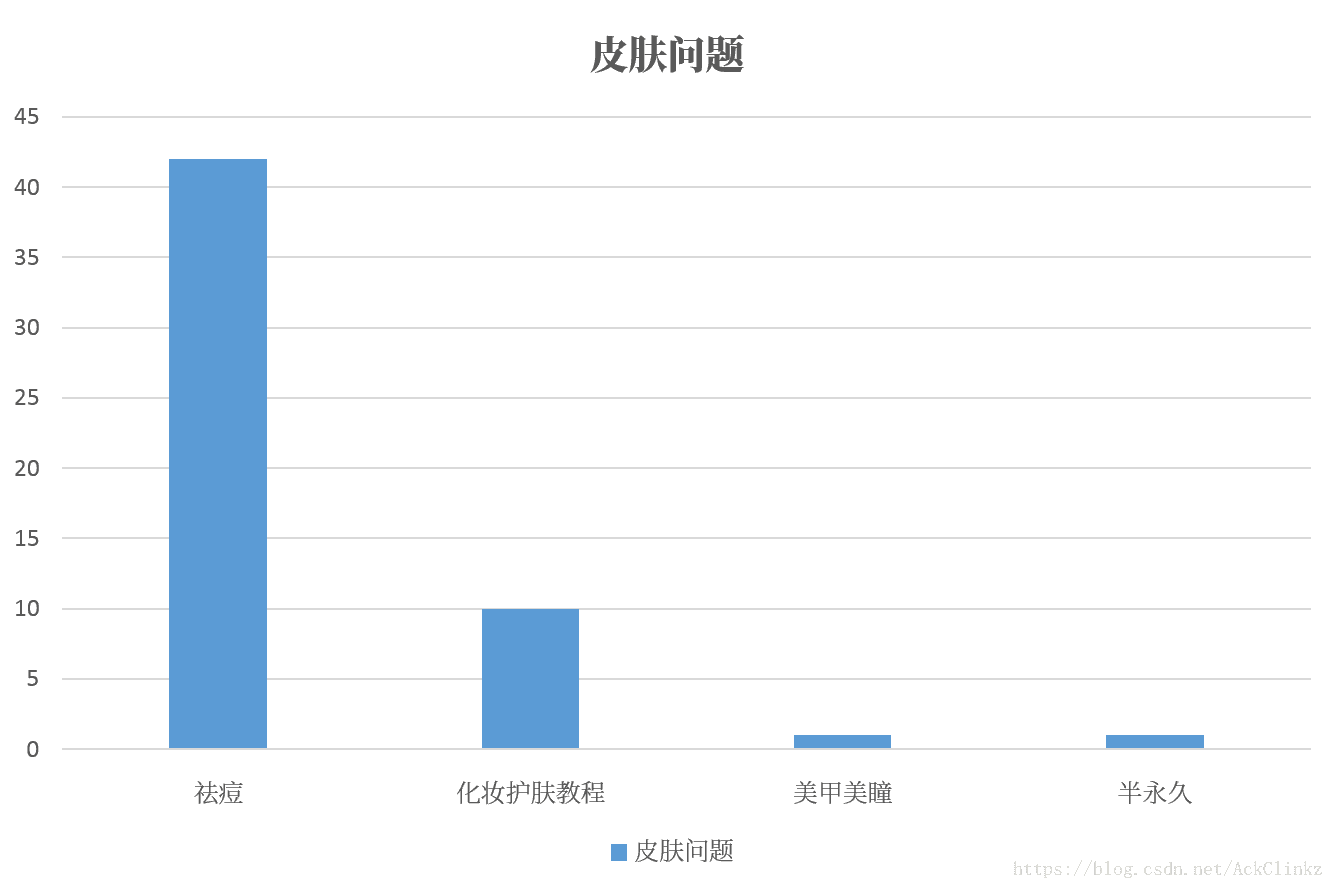
其中纵轴代表数量,横轴代表类目。显然,在标注数据中,“婚照”和“皮肤问题”的分布符合它的真实类目,标注数据不存在问题。此时,一个问题浮现与我的脑海,fastText对上述两个关键词的学习效果如何呢?结果如下:

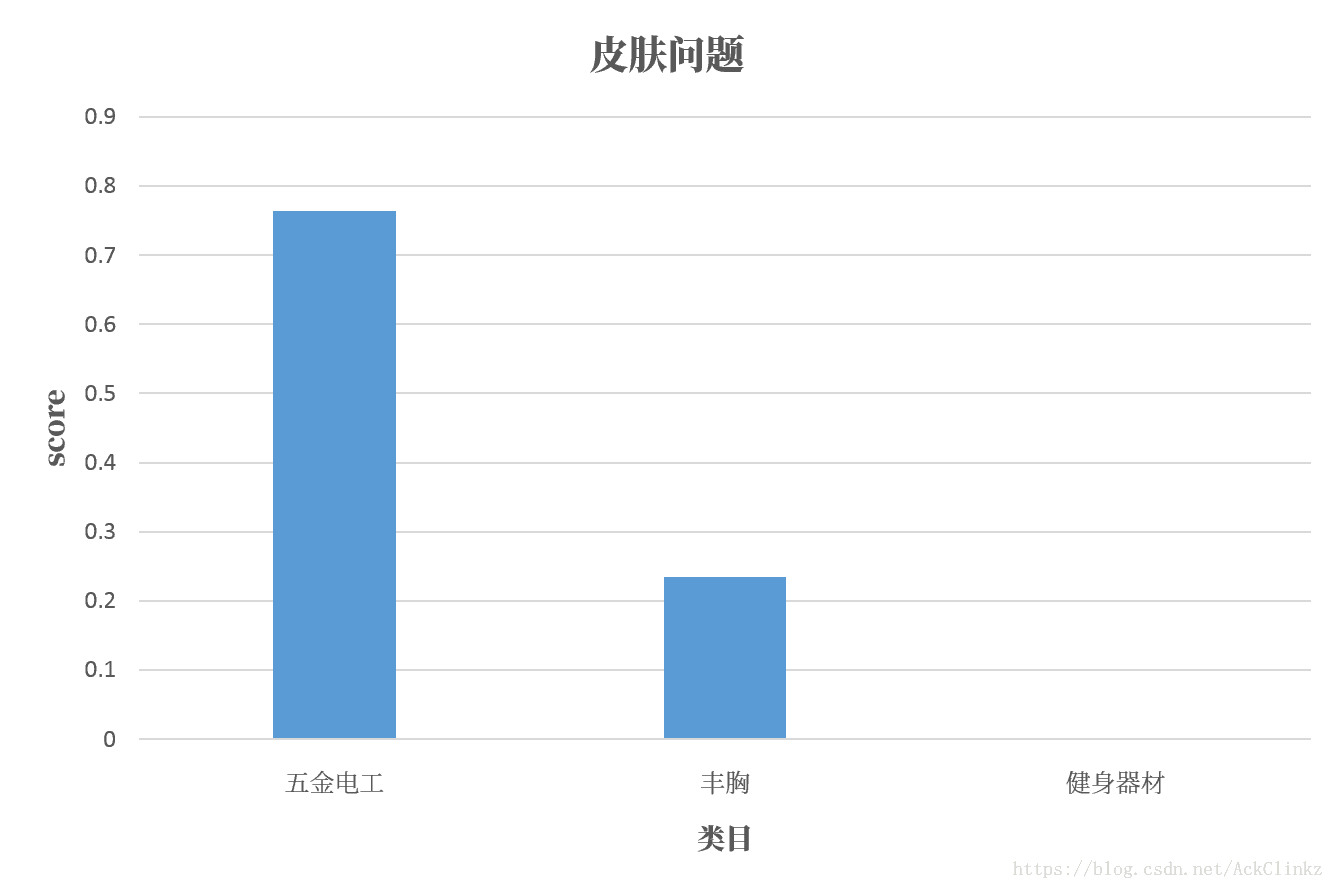
其中,横轴代表类目,纵轴代表预测打分。显然,fastText的预测效果十分差。在分析原因之前,先总结一下上述实验结论:
- 验证集效果极佳
- 真实数据效果很差
- 真实样本的预测效果不好
- 关键词的近义词质量不错
- 标注数据中,关键词的分布基本符合人的要求
- 关键词的预测效果极差
上述结论,可以进一步表述为:1. 使用余弦相似度
作为测度时,模型训练效果不错( w w 表示词向量)。2. 使用线性分类器
作为测度时,模型训练效果很差( θ θ 表示模型,这里假设使用softmax作为分类器)。对于上述问题,可以通过fastText的基本原理来分析。假设,fastText使用softmax作为loss,此时代价函数
其中 y y 表示类别(0或1),h表示隐层状态 1n∑ni=1wi 1 n ∑ i = 1 n w i 。此时,更新参数 θ θ 的方式是:
其中 C C 代表类别,
类似于Word2Vec中CBOW,句子中词向量的更新方式是:
其中 L L 代表句子中词的个数。值得注意的是, ∂L∂h ∂ L ∂ h 的偏导十分复杂。为此,fastText对 ∂L∂h ∂ L ∂ h 作了近似计算,最终词向量的更新方式为
从词向量的更新方式可知,当两个词多次出现在同一个句子时,它们的词向量会向着相同的方向变化。随着模型的训练,最终使这两个词余弦相似。下图是“皮肤问题”、“婚照”和它们的近义词共同出现次数的统计:
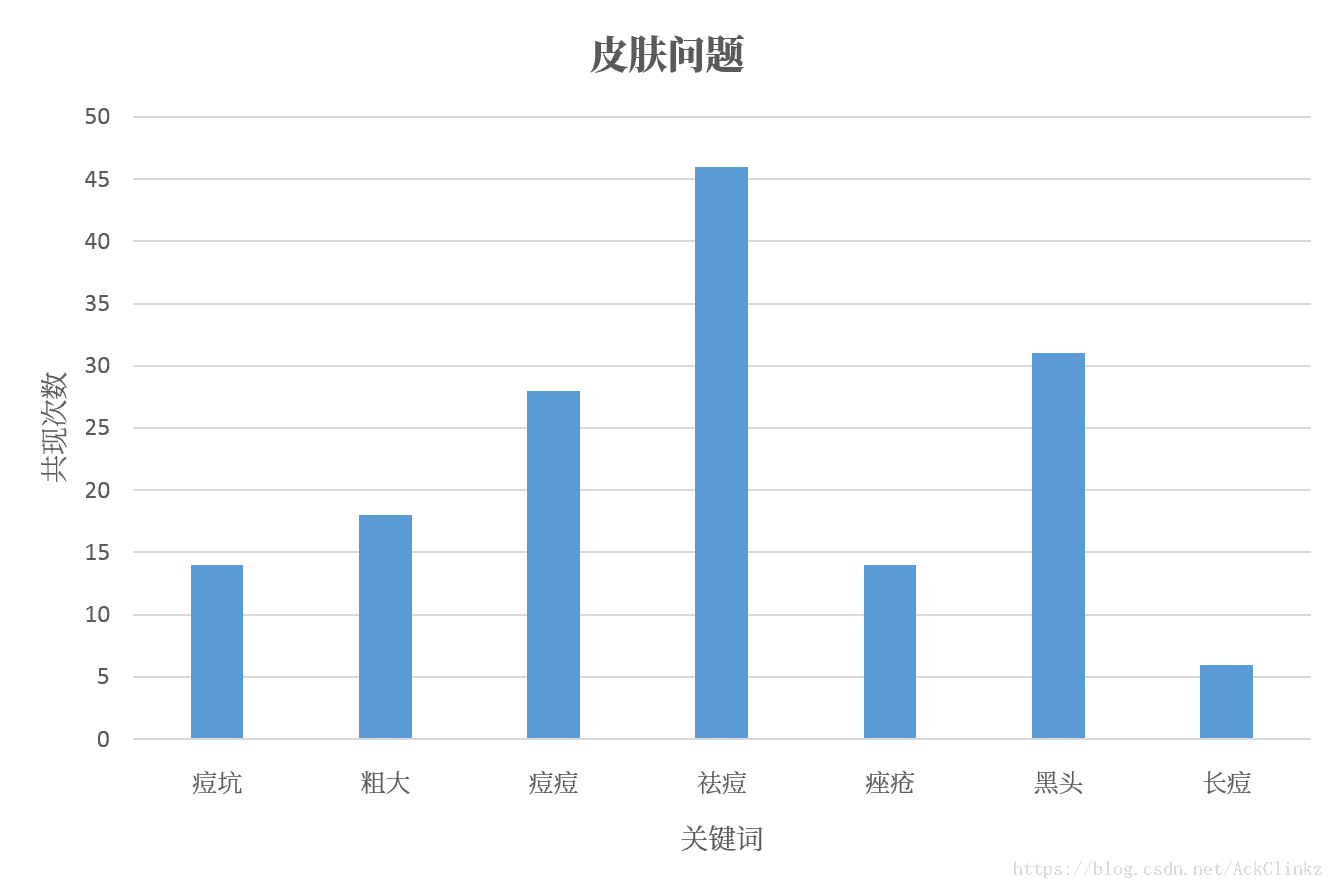
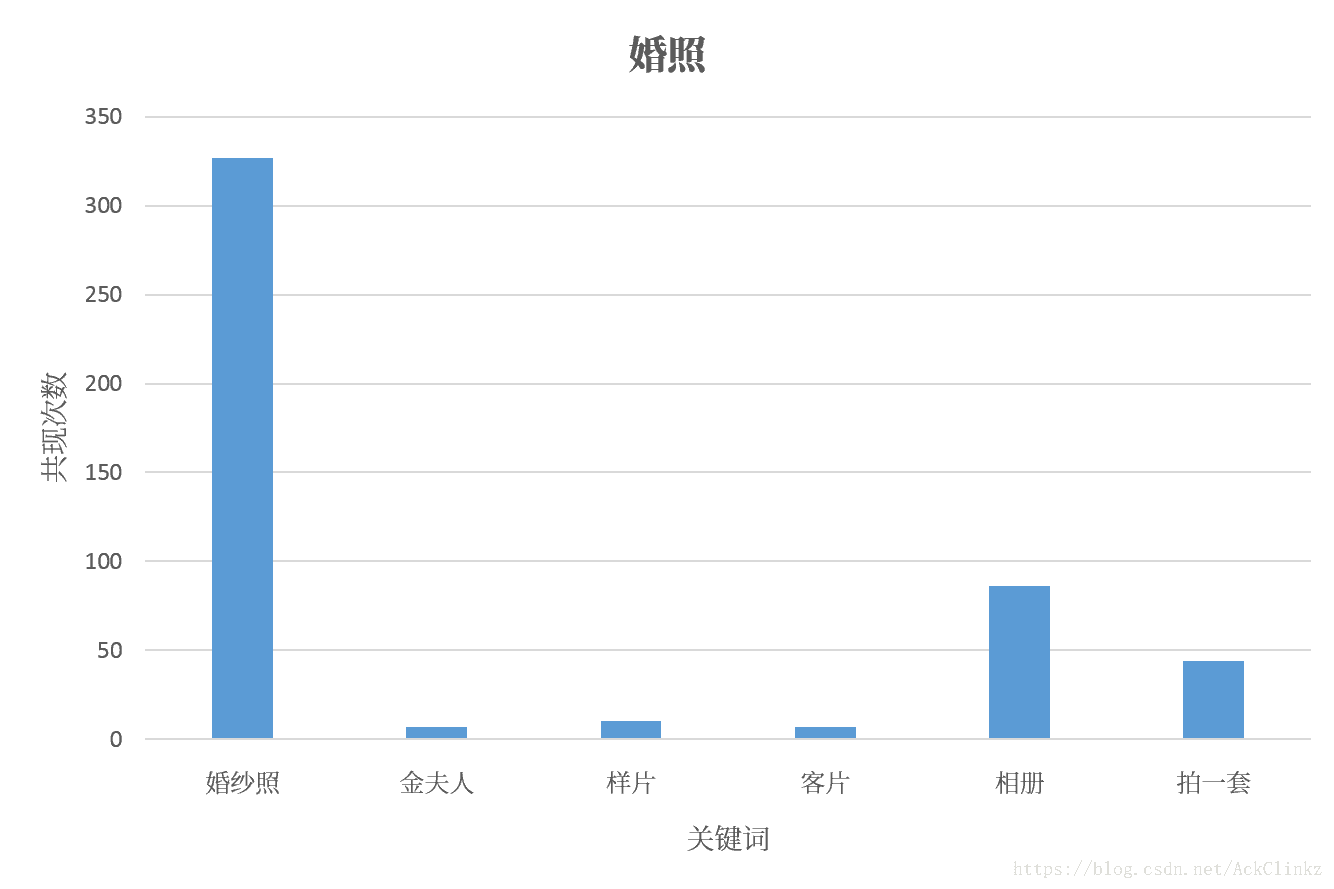
实际统计结果符合理论分析,确定了余弦相似度效果好的理论依据。那么,为什么最终的分类效果差呢?通过上一节的介绍可知,fastText采用了线性分类器(假设使用softmax)
不同于余弦相似度考虑向量间的夹角,线性分类器受到词向量不同维度权重的影响。这里可以近似理解为,词向量的每一维度都代表一类信息,一类信息越强,其对最终分类结果影响越大。下图是上述关键词的词向量分布:
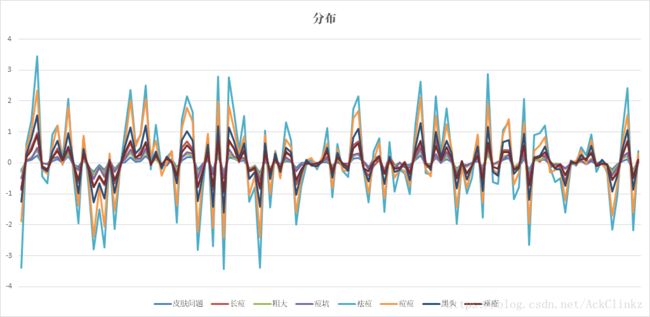
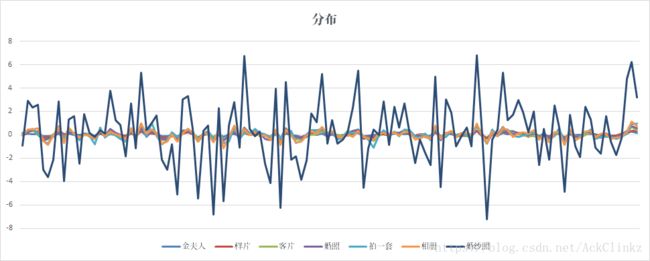
其中横轴代表不同维度,纵轴代表权重。为了更加直观表征词向量在不同维度的分布,这里使用了折线图。通过上述两图可以看出,近义词的词向量随维度的变化趋势基本一致,区别在于权重大小。那么这些近义词的分类效果如何呢?
| 关键词 | 分类 |
|---|---|
| 祛痘 | label祛痘 1.00001 label邮政业务 1e-05 |
| 痘痘 | label祛痘 1.00001 label邮政业务 1e-05 |
| 黑头 | label祛痘 0.899334 label丰胸 0.0984305 label国内游 0.00187405 |
| 长痘 | label丰胸 0.912702 label五金电工 0.0872995 label清洁用品 2.30091e-05 |
| 痤疮 | label丰胸 0.994396 label五金电工 0.00547735 label国内游 0.000156227 |
| 痘坑 | label丰胸 0.999394 label五金电工 0.000625976 label游戏设备 1.01868e-05 |
| 皮肤问题 | label丰胸 0.995997 label五金电工 0.00400344 label游戏设备 2.38029e-05 |
| 关键词 | 分类 |
|---|---|
| 婚纱照 | label婚纱摄影 1.00001 label邮政业务 1e-05 label买点卡 1e-05 |
| 相册 | label丰胸 0.995544 label五金电工 0.00436158 label游戏设备 0.000107164 |
| 拍一套 | label丰胸 0.996777 label游戏设备 0.00243306 label五金电工 0.000790049 |
| 婚照 | label游戏设备 0.755574 label丰胸 0.244059 label五金电工 0.000393285 |
| 样片 | label丰胸 0.854614 label五金电工 0.0832258 label游戏设备 0.0618847 |
| 金夫人 | label丰胸 0.940839 label五金电工 0.0574496 label游戏设备 0.00169886 |
| 客片 | label丰胸 0.99946 label五金电工 0.000471862 label游戏设备 7.20562e-05 |
从分类效果可知,不同维度的权重大小对关键词的分类效果至关重要。为了便于描述,这里简单使用向量的2-范数 ∥w∥ ‖ w ‖ 来衡量词向量的大小。在进一步分析之前,这里引入类别覆盖率 r r 的概念。假设在类别 a a 中有 n n 个样本,词 l l 在 p p 个样本中出现,则类别覆盖率为
以此为基础,类别纯度表示类别覆盖率的最大值
类别纯度主要用于衡量某个词是否是某个类的强特征。例如,“婚纱照”在“婚纱摄影”中类别覆盖率为90%,在“游戏”和“祛痘”中覆盖率为1%,那么“婚纱照”就是“婚纱摄影”类的强特征,此时类别纯度为90%。根据fastText更新词向量的方式可知,类别纯度越高,它的词向量范数越大。为了确定这种对应关系,统计了训练结果
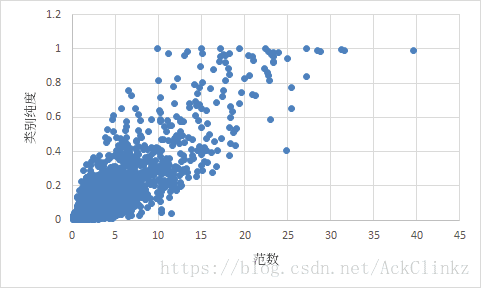
通过统计结果可知,范数与类别纯度是正相关的。值得注意的是,上面提到的“婚纱照”、“祛痘”和“痘痘”等分类准确的词,它们都是类别纯度极高的词(这与使用规则产出标注数据有直接的关系),因此它们的范数也会非常大。上文提到,fastText使用 1n∑ni=1wi 1 n ∑ i = 1 n w i 来表示文档向量。当一个句子含有上述高纯度的词,它会直接统治整个文档向量。此时,反向传导不再受到文档中其他词的影响。那么当高纯度词分类准确时,代价函数会变得很小,看似效果很好,其实对很多有效关键词置之不理。
总结
通过上面的分析可知,强特征(关键词)的存在是造成上述问题的根源。但是在真实场景中,语言具有随意性,无法控制每个人按照既定的规则来叙述一件事情。了解机器学习的人会知道,此类问题属于模型泛化问题,即从现有的数据,尽可能学到更多的知识。关于模型泛化的问题,我将在下一节进一步介绍。