基于DB2数据库PureScale双活设计要点梳理


在两地三中心建设过程中,我们发现采用传统的容灾技术碰到3个问题。
1. 切换时间太长,即使通过自动化实现,主切备和备切主都需要花费几十分钟时间。
2. 操作风险太大,比如核心系统切换涉及到20步以上的操作步骤和上百条命令,每条命令都有出错的可能。
3. 建设成本太高,同城机房按照1比2甚至1比1 的比例进行建设,服务器平时完全闲置,除了一次性投入,每年还要耗费大量的维护费用。
因此相对于传统容灾方式,我们希望建设一个双活平台,解决降低RTO时间、降低成本和降低切换风险等需求。
在双活平台的选型过程中,基于当前需求是传统型业务(非互联网类型)做迁移,当前数据库是DB2和Oracle,从平台角度发起而不想对业务开发进行改造,最终实现双机房对等双活等因素,我们最终发现Db2 pureScale GDPC方案最适合。
这个方案特点明显: 高可用性,可扩展性和对应用透明。那么选好型后,怎么落地成了最关心的问题。因为双活技术的复杂性,在方案设计的每个环节都需要慎重考虑,选择最合适的方式,最终形成自己需要的方案(以下为内容分享)。
1.为什么要基于Db2 pureScale做数据库双活?优势和意义是什么?
为了保证数据多中心部署0丢失,降低容灾切换时间,减少人为操作风险,降低成本。双活系统就是要将这几个方面做到极致。
在选型的过程中发现其实没有太多选择,能做到这一点的成熟软件和技术只有Db2pureScale集群技术和OracleRAC技术。这里说说我们为什么要用Db2pureScale而不是OracleRAC。
从业界经验来说,Oracle Extend RAC是面向同城双活的数据库产品,然而从各方了解都不推荐使用,即便是使用了这个技术的案例里面,灾备机房节点也只是作为热备,没有提供对等的服务,这个是与我们建设双活的应用目标有差距的。
而DB2 GDPC(地理位置上分开的PureScale集群)方案从设计之初就是为了做对等双活,国内也已经有上线案例。从厂商支持力度上来说,IBM主推这个技术并且支持好,Oracle相比差一点。从底层技术来说,IBM的pureScale在可扩展性,对应用透明等特点上是优于Oracle的。所以建议选择Db2GDPC方案来建设双活环境。
2. 基于Db2 pureScale的数据库双活方案设计,要遵循哪些重要原则?
如果将数据库双活平台作为未来的常规建设,应用越来越多的系统,那么在建设初期,我们就要设定好平台的目标:
1、通用性:基于LUW开放平台,支持部署在任何厂商的存储、服务器和操作系统上。不能选择一体机,大型机等不通用的设备。
2、无差别性: 双中心交易对等,同城之间同时处理业务请求,无主次之分。只有这样的系统才能面对失去单数据中心的风险。
3、高可用性:最下化降低同城切换时间,同城站点出问题不会影响全局业务。业务切换需要在最短时间内完成。
4、可维护性:基础设置重大变更不停机,可以通过滚动升级的方式完成维护操作。
5、可迁移性:平台对业务系统透明,开发无需改动代码,即可快速部署到该平台。同样该平台部署的系统也可平滑迁移出来。
6、安全稳定运行,该平台可以实现5个9的运行目标。
基于以上目标,在DB2 PureScale的数据库双活方案设计里面,我们遵循对等双活和对应用透明的原则,克服困难,最大化双活的高可用性优点,改善性能相关的缺点。
总体设计
3.如何选择双中心站点和仲裁站点的定位,仲裁站点需要什么条件?
首选需要说明DB2 GDPC方案逻辑上需要三个站点,其中两个站点作为双活的数据中心,第三个站点作为仲裁站点。
双站点的定位和条件:
1.双活站点之间需要可靠的 TCP/IP 链接相互通信,还需要RDMA(具有 RoCE 或 Infiniband)网络链接。具有成员和 CF 的两个站点是生产站点,它们处理数据库事务。这两个生产站点相距应该不超过 50 公里,通过 WAN 或暗光纤(必要时还使用距离范围扩展器)来连接这两个站点,并且在它们之间配置了单个 IP 子网。距离更短将获得更高性能。在工作负载相当少的情况下,可以接受更远的距离(最多可达 70 或 80 公里)。
2.双站点的CF和成员节点是对等的。每个生产站点都有一个 CF 以及相同数目的主机/LPAR 和成员。
3.每个生产站点都有它自己的专用本地 SAN 控制器。SAN 已分区,以便可从这两个生产站点直接访问用于 DB2 pureScale 实例的 LUN。在站点之间需要 LUN 之间的一对一映射,所以第一个站点上的每个 LUN 都在第二个站点上具有相同大小的对应 LUN。而GPFS同步复制用作存储器复制机制。
4.对于RDMA网络支持RoCE和infiniband。个人建议使用RoCE,通用性和可部署性强。如果使用 RoCE 进行成员/CF 通信:使用多个适配器端口进行成员和 CF 通信,以适应其他带宽和提供冗余。对于以完全冗余方式配置的总共四个交换机,在每个站点中使用双交换机。将每个成员和 CF 中的其他绑定的专用以太网网络接口设置为 GPFS 脉动信号网络。也就是我们说的私有TCP网络。
如果使用 Infiniband 进行成员/CF 通信:仅支持每个成员和 CF 具有单个适配器端口以及每个站点具有单个交换机。此接口用于成员和 CF 通信以及 GPFS 脉动信号网络。
第三个站点的定位和条件:
1. 单个主机(非成员主机,也非 CF 主机),专用于集群仲裁职责,与集群中的其他主机位于相同操作系统级别。可以使用虚拟机。
2. 不需要访问两个生产站点中的 SAN。
3.不需要RDMA通信,也不需要私有网络(RoCE的情况下使用到的TCP私网)。
需要为集群中的每个共享文件系统都需要仲裁盘,这个文件系统的仲裁盘就是从这个第三站点划分出来的。没有用户数据存储在这些设备上,因为这些设备仅用来存储文件系统配置数据以用于恢复,并且充当文件系统磁盘配额的仲裁磁盘。这些设备的大小需求为最小需求。通常,50 到 100 MB 的设备在大多数情况下能够满足需求。此设备可以是本地物理磁盘或逻辑卷 (LV)。
请遵循下列准则来配置 LV:
在同一卷组 (VG) 中创建逻辑卷。为卷组至少分配一个物理磁盘。实际数目取决于所需要的逻辑卷数,而逻辑卷数又取决于共享文件系统数。如果有可能,请使用两个物理卷以提供冗余。
有限的条件下,例如只有两个数据中心,仲裁站点可以放在所谓的主中心机房里,但是硬件上要和其他节点分开。这个主中心机房的定位就是可能于此关联的其他重要系统在这个机房,访问更直接和快速。在存在这种定位的情况下,主CF节点,跑批的成员节点建议放在这个机房里。
通信网络设计
4. 如何规划和设计集群内部通信网络?
在整个DB2GDPC的方案里面,仲裁站点仅仅需要TCPIP网络通即可,不需要SAN,RDMA,私网等,所以需要重点关注双活站点的CF和成员节点的网络设计。
1. 双站点DWDM通信硬件:建议冗余,租用不同运营商线路。
2. 以太网对外服务:以太网卡建议做冗余,采用双网卡绑定,建议是主备模式。每个以太网的交换机也建议冗余,使用类似VPC等虚拟绑定技术。交换机间互联线路要求冗余。

3. RoCE网络和私网:RoCE网卡自带两口,可以连接到不同的交换机上,但是这两个口对于网卡吞吐量没有影响。建议每个节点采用多网卡,每张网卡链接在不同的RoCE交换机上。RoCE网卡是不能做绑定的,都是实际的物理地址。所有的RoCE网络都划在一个VLAN里面。这里还要关注一个私网,专门给GPFS走心跳和数据的网络,是TCPIP协议。
这个私网建议做多口绑定,也是主备模式,每个口连接到不同的RoCE交换机上,与RoCE网络划分在同一个VLAN里面。交换机的建议和以太网交换机差不多,每个站点冗余绑定。

共享存储设计
5. 如何设计存储网络,仲裁站点需要存储吗? NSD server怎么配置?
通过一张图来了解多站点GPFS复制拓扑。GPFS复制通过建立文件系统的两个一致的副本来提供存储器级别的高可用性;每个副本在另一个副本发生故障时都可用于恢复。
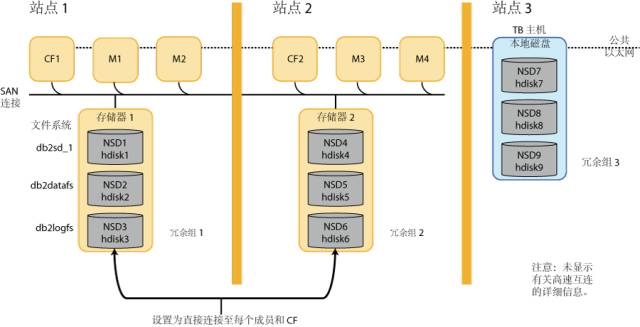
GPFS为文件系统的第一个副本和第二个副本提供了两个单独的存储控制器。这些存储控制器分别称为冗余组 1 和冗余组 2。GPFS将数据和文件系统元数据都存储在冗余组中。
RSCT 和GPFS集群使用多数节点配额而不是仲裁磁盘配额。对于具有三个地理位置分散的站点的 GDPC,主站点和辅助站点具有相同数目的成员,并且每个站点中都有一个 CF。第三个站点中存在单个仲裁主机。仲裁主机是包含所有文件系统仲裁磁盘的文件系统仲裁冗余组的所有者。这些磁盘仅包含文件系统描述符信息(例如,文件系统配置元数据)。
仲裁站点仲裁主机只需要通过 TCP/IP 访问同一集群中的其他主机。它不需要访问冗余组 1 和冗余组 2 中的数据。在仲裁主机上面,每个共享文件系统都需要独立的文件系统仲裁磁盘用于文件系统配额以及进行恢复。每个磁盘最少需要 50 MB。它可以是本地物理磁盘或逻辑卷 (LV)。
扩展: 因为GPFS复制时通过在本机直接通过SAN访问远程磁盘来写实现同步。当站点1和2之间网络出现问题的时候,数据复制需要停40秒(磁盘超时属性)。这个在很多时候是不能容忍的,尤其出现网络质量差的情况下。所以我在这个地方做了些改进并在生产验证。
如图中的db2logfs文件系统是用来放置数据库日志的,当数据库日志的io停止的时候数据库也是会hang住,所以我将db2logfs相关远程盘的主机映射都去掉,这样强制db2logfs在复制的使用tcp网络。
资源设计
6. 如何分配成员和CF节点的资源。在DB2 pureScale GDPC数据库双活技术方案设计的资源设计环节中,我们该如何划分及分配成员和CF节点的资源? 从哪些点方面进行入手考虑(例如并发访问量、数据量等),需要特别关注哪些什么(例如写读比例、写一致性、读一致性等)?
CF和成员节点的内存主要就是CPU和内存的分布,还有就是RDMA通信网卡资源。
我们至今还没有遇到网卡带宽瓶颈。即便是在双活环境出现CF和成员通信瓶颈也不是因为带宽,而是Db2集群内部通信的机制导致。所以对于RDMA网卡,冗余满足高可用即可。
成员CPU的估算是基于工作负载来的,直接比较的对象是单机的数据库资源配置。因为成员相对于传统单机数据库有更多的消耗,所以在同样一个节点的负载需求情况下,建议成员CPU要比单机更多一些。 CF的CPU需求和RDMA卡有关系。IBM官方推荐一个CF的RDMA卡口对应6-8个CPU核心。
成员节点的内存也是相对于同样工作负载下单机的数据库内存配置来比较的。因为成员和CF之间有了更多的锁,所以主要区别就在于成员节点的locklist需求变得更大,个人建议调整为单机数据库的两倍吧。CF的内存消耗主要是GBP和GLM这两大块。给大家一个公式:GBP大小是LOCAL BUFFERPOOL总页面数*1.25KB*MEMBER数量。GLM就是所有member节点locklist总和吧。解决这两大块的估算再加一些就是整个CF的内存配置需求量了。
访问设计
7. 客户端采用什么方式连接数据库节点?
在双活环境,怎么最大化负载均衡并不是最主要的考虑因素,最大化性能才是需要考虑的。因为跨站点的通信延时,所以要尽量避免跨中心访问。所以客户端应该采用偏好链接的方式来访问数据库节点。
每个应用服务器配置自己的数据源,通过Client Affinity的方式连接到数据库成员节点,有效避免跨站点访问。一旦成员节点出现故障,ACR可以自动将应用服务器连接到其他存活的成员节点。 在这个基础上,还有几点需要注意:
1、跑批节点放在主CF同机房member上。
2、启动数据库的时候第一个启动的成员节点要选择和主CF在同一机房。因为有些数据库的自动管理工作是在第一个启动的member上完成的。
8.基于Db2 pureScale做数据库双活,对于重要业务需求的实现程度如何?方案的优点有哪些?
基于Db2 pureScale的数据库双活平台在我行已经上线三年,期间陆续迁入了6套优先级比较高的系统。整个运行过程算是达到了预期。也经历过网络故障等实际考验,表现都如预期。所以这个高可用性和可维护性都得到了验证。
但是这个方案在满足数据0丢失,可用性非常高的情况下,还是牺牲了部分性能。因为距离的原因,写盘和通信都不可避免延长。所以迁入地系统在跑批的时候明显比以前长,这也是没办法的。
9.基于Db2 pureScale的数据库双活方案,有哪些局限?有什么可以继续改进的地方呢?
在这个方案里面,我觉得从技术上还有比较多的地方需要改进。一方面热点数据问题,虽然我们通过分区表随机索引等方式打散热点数据,但是还是需要从数据库技术层面给出更好的改进。
另一方面是节点之间的通信,因为延时的缘故,还需要从技术上继续减少交互。同时带宽不是问题,通信的并发性也需要从技术上去解决。相信如果上述几个方面能够得到改进,这个方案将会得到更大的运用空间。
分享专家: 孔再华 数据库架构师
文章来源: 转自talkwithtrend 公众号
具有丰富的数据库环境问题诊断和性能调优的经验,擅长DB2 PureScale 集群产品的项目咨询和实施。
分享先到这里,为了方便大家进一步理解双活相关技术,笔者把双活重点知识点做了梳理并整理成电子书“业界主流数据中心存储双活完全解析”,书籍目录如下所示:
第①章 双活技术和方案概述
第②章 数据中心双活该如何构建
2.1 构建数据中心互联网络
2.2 数据中心内部互联技术介绍
2.3 双活应用部署方式
2.4 双活仲裁部署方式
2.5 双活应用的外部访问
2.6 基于网关的双活技术
2.7 双活方案的基本技术条件
2.8 基于应用层的双活技术
2.9 基于NAS的双活技术
2.10 双活的限制和要求
第③章 剖析Clustered Metro Cluster双活方案
第④章 剖析SVC Stretch Cluster双活方案
第⑤章 剖析PowerHA/SVC HyperSwap双活方案
第⑥章 剖析HDS HAM/GAD双活方案
第⑦章 剖析华为VIS/HyperMetro双活存储方案
第⑧章 剖析EMC Vplex双活数据中心存储方案
第⑨章 剖析SRDF/Mtreo和MetroSync双活方案
第⑩章 剖析HPE、Dell和Fujitsu双活存储方案
第①①章 如何在应用层部署应用双活
11.1物理应用部署
11.2虚拟应用部署
第①②章 多路径ALUA如何优化双活方案I/O处理
12.1 什么是ALUA多路径机制
12.2 ALUA在双活中如何应用
12.3 ALUA的路径状态和相关概念
12.4 ALUA技术支持现状
12.5 ALUA主要功能和能力
第①③章 业界主流厂商双活架构和技术比较
13.1 存储网关双活
13.2 Active-Passive双活
13.3 Active-Active双活
更多架构师技术关知识请参考“架构师技术全店资料打包汇总(全)”电子书(32本技术资料打包汇总、详解目录和内容请通过“阅读原文”获取)。
温馨提示:
请识别二维码关注公众号,点击原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。

