WEBKIT/CEF DOM树创建过程分析
一、DOM简介:
DOM是Document Object Model的缩写,及文档对象模型。DOM定义了一组与语言、平台无关的接口,该接口能让编程语言访问修改文档。在CEF内部,html文档会被解释成一种树状结构,及DOM树。下图是html文档和其对应的DOM树。

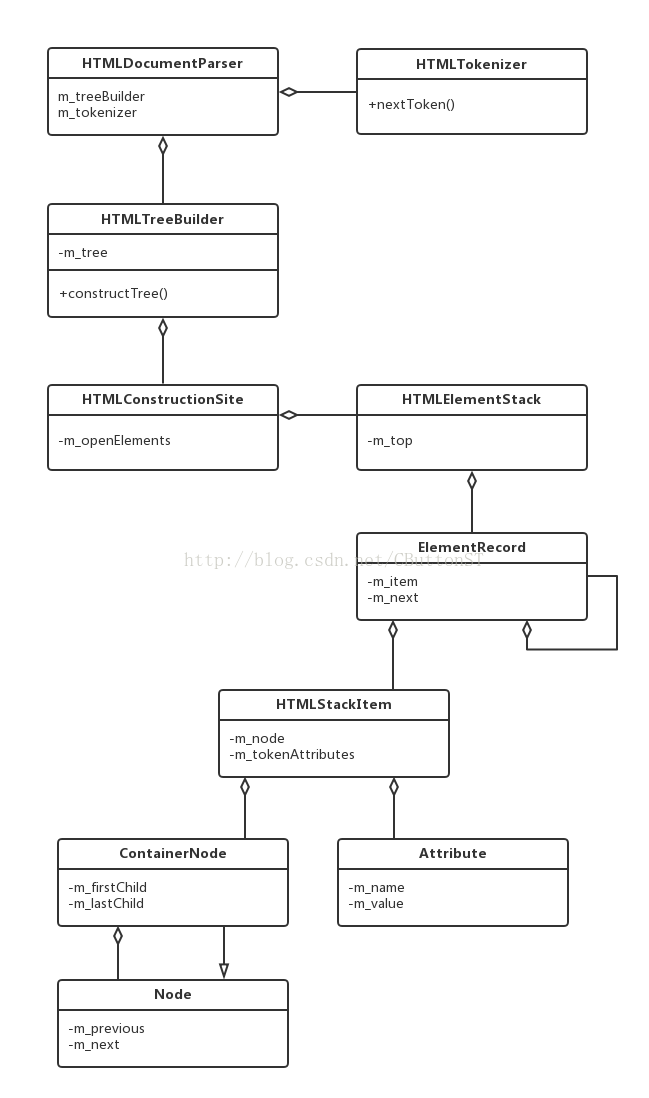
二、生成DOM树的主要类及其关系图:
三、DOM树创建过程:
首先HTMLDocumentParser将接收到html格式的字符串,交由HTMLTokenizer进行分割,然后将分割好的HTMLToken对象交给HTMLTreeBuilder构建DOM树。
1、token分割
HTMLTokenizer其内部是通过一组复杂的状态机来进行HTMLToken分割的,其中状态多达70个,详细参考HTMLTokenizer.h中enum State的定义。
分割html的主要接口:
bool HTMLTokenizer::nextToken(SegmentedString& source, HTMLToken& token); //source为传入的html字符串 token为当次分割得到的HTMLToken以下面html字符串为例,分析nextToken分割过程:
nextToken的第一个参数source及为上述html,HTMLDocumentParser内的pumpTokenizer会通过一个while循环不断调用nextToken,直到整段html字符串被分割完成,每执行一次nextToken后,source内的字符串指针会移动到当前token的下一个字符的地址,之后再次执行nextToken便可以解析下一条token了。
下图是第一个token被分割出来的详细流程,后续token的分割与此类似。m_state为状态机,cc为当前解析的字符。进入nextToken函数后,此时source对应字符串为:...,m_state的初始状态被置为DataState,当遇到'<'字符时,m_state变为TagOpenState,表明当前正在解析html标,同时source内的字符串指针++,指向下一个字符,cc='h'。标签解析完成后进入属性名解析(m_state=BeforeAttributeNameState),之后再进行属性值的解析(m_state=BeforeAttributeValueState),解析完成所有的属性之后,遇到‘>’,当前标签解析结束,退出nextToken函数,第一个token解析完成,此时source对应的字符串为:
<...。图中红色部分是解析标签名,标签名会存入HTMLToken对象token的m_data成员中;橙色部分是属性名解析,蓝色部分是属性值解析,解析结果会存入HTMLToken::Attribute对象中,HTMLToken中有个Attribute列表(m_attributes),存放所有的HTMLToken::Attribute对象。

2、token处理
有了HTMLToken对象后,紧接着HTMLDocumentParser调用constructTreeFromHTMLToken创建DOM树,通过几层函数调用后,来到HTMLTreeBuilder::processToken函数,这个是处理token的核心函数。processToken会根据token的类型调用其对应的processXXX函数(processDoctypeToken、processStartTag、processEndTag、processComment、processEndOfFile)来处理对应token,token的类型有如下几种:
enum Type {
Uninitialized, //未初始化
DOCTYPE, //文档解析类型
StartTag, //开始标签
EndTag, //结束标签
Comment, //注释
Character, //字符
EndOfFile, //文件结束
};enum InsertionMode {
InitialMode,
BeforeHTMLMode,
BeforeHeadMode,
InHeadMode,
InHeadNoscriptMode,
AfterHeadMode,
TemplateContentsMode,
InBodyMode,
TextMode,
InTableMode,
InTableTextMode,
InCaptionMode,
InColumnGroupMode,
InTableBodyMode,
InRowMode,
InCellMode,
InSelectMode,
InSelectInTableMode,
AfterBodyMode,
InFramesetMode,
AfterFramesetMode,
AfterAfterBodyMode,
AfterAfterFramesetMode,
};- 这里将m_insertionMode简称state,首先第一个token(type=StartTag, name=html)传入processToken,执行的是state等于InitialMode的处理过程,state被设置为BeforeHTMLMode,接着执行state等于BeforeHTMLMode的处理过程,token被解析成HTMLHtmlElement对象,同时state变为BeforeHeadMode,函数结束。
- 接着再次调用processToken处理处理第二个token(type=StartTag, name=head),此时执行state等于BeforeHeadMode的出里过程,创建HTMLHeadElement对象,state变为InHeadMode,函数结束。
- 接着处理token(type=EndTag, name=head),执行state等于InHeadMode的出里过程,state变为AfterHeadMode。
- 接着处理token(type=StartTag, name=body),执行state等于AfterHeadMode的处理过程,创建HTMLBodyElement对象,state变为InBodyMode。
- 接着处理token(type=StartTag, name=a),执行state等于InBodyMode的处理过程,创建HTMLDivElement对象,state不变。
- 接着处理token(type=EndTag, name=a),执行state等于InBodyMode的处理过程,state不变。
- 接着处理token(type=EndTag, name=body),执行state等于InBodyMode的处理过程,state变为AfterBodyMode。
- 接着处理token(type=EndTag, name=head),执行state等于AfterBodyMode的处理过程,state变为AfterAfterBodyMode。
- 接着处理token(type=EndTag, name=html),执行state等于AfterAfterBodyMode的处理过程,state变为InBodyMode,执行state等于InBodyMode的处理过程。
至此,整个状态机的处理过程结束。
3、DOM树构建
在上述的整个状态变化中伴随着token转化HTMLXXXElement对象,整个DOM树就是通过这些element对象组合而成的,而组合过程则是用栈(后进先出)这种数据结构来实施的,html文档存在嵌套且对称性高,这和栈的特点相当契合。HTMLElementStack对象便是这个栈,m_top是其成员,指向栈顶,类型是ElementRecord。ElementRecord中包含两个成员,一个是m_item(类型:HTMLStackItem),存放element;另一个m_next(类型:ElementRecord),指向栈里面的下一个元素,将整个栈里的元素串起来。上述内容在第二节的类图中也有说明。
前面说过processToken会根据token的type调用不同的processXXX函数,当type=StartTag时,调用processStartTag函数,根据token的name生成对应HTMLXXXElement对象,接着调用attachLater创建一个延迟任务task,task的type是Insert(插入节点),task.parent(父节点)被赋值为栈顶元素所存储的node,task.child为当前待插入DOM树的element;接着用该element对象生成ElementRecord对象并压入栈中。当type=EndTag时,调用processEndTag函数,将token的name对应的ElementRecord对象从栈中移除。
执行processToken之后,调用executeQueuedTasks处理上一步生成的task,经过几层调用后最终调用task.parent->appendChildCommon将element插入DOM树,其函数定义如下:
void ContainerNode::appendChildCommon(Node& child)
{
child.setParentOrShadowHostNode(this);
if (m_lastChild) {
child.setPreviousSibling(m_lastChild);
m_lastChild->setNextSibling(&child);
} else {
setFirstChild(&child);
}
setLastChild(&child);
}- 当m_lastChild==NULL时(及父节点第一次插入节点时),则将m_firstChild赋值为child,同时将m_lastChild赋值为child。
- 当m_lastChild!=NULL时,将child.m_previous赋值为m_lastChild,同时将m_lastChild.m_next赋值为child,并更新m_lastChild值为child。
DOM树构建过程图解:
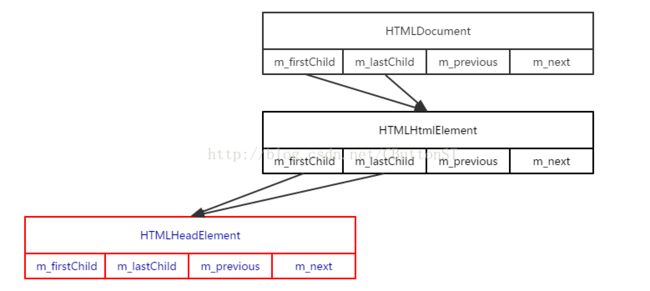
- 插入第一个节点(HTMLHtmlElement对象)后,DOM树如下,其中HTMLDocument是整个文档的根节点:

- 插入第二个节点(HTMLHeadElement对象)后,DOM树如下:
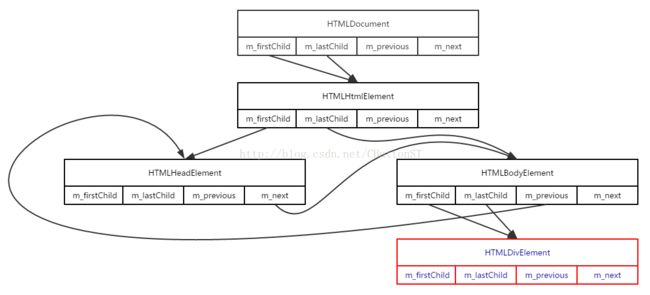
- 插入第三个节点(HTMLBodyElement)后,DOM树如下:

- 插入第四个节点(HTMLDivElement对象)后DOM树如下:
以上就是整个DOM树的创建过程。