推荐系统-基于模型协同过滤理论基础与业务实
推荐系统-基于模型协同过滤理论基础与业务实践
1.SparkMllib库框架详解
- Spark机器学习库
- 五个组件
- ML Algratham算法 : 分类 , 聚类 , 降维 , 协同过滤
- Pipelines管道 ----
- Featurization 特征化---- 特征抽取 , 特征转换 , 特征降维 , 特征选择
- Persistence 持久化---- 模型的保存 , 读取 , 管道操作
- Utilities ---- 提供了线性代数 , 统计学以及数据处理工具
- Sparkml和Sparkmllib
ml基于DatafrmaeAPI- MLlib仍将支持基于RDD的API
spark.mllib以及错误修复。 - MLlib不会为基于RDD的API添加新功能。
- 在Spark 2.x版本中,MLlib将为基于DataFrames的API添加功能,以实现与基于RDD的API的功能奇偶校验。
- 在达到功能奇偶校验(粗略估计Spark 2.3)之后,将弃用基于RDD的API。
- 预计将在Spark 3.0中删除基于RDD的API。
- MLlib仍将支持基于RDD的API
- 为什么会从MLlib切换到DataFrame的API
- DataFrames提供比RDD更加用户友好的API。DataFrame的许多好处包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
- 基于DataFrame的MLlib API跨ML算法和多种语言提供统一的API。
- DataFrames有助于实用的ML管道,特别是功能转换
- mllib基于rdd的API
- 五个组件
2.SparkMllib基本数据类型
-
向量
-
Local vector本地向量,主要向Spark提供一组可进行操作的数据集合
- 创建方式上
- dense稠密性向量----会存储0值和非0值
- sparse稀疏性向量—仅可以存储非0值元素
- sparse(n,seq((x,y),(p,q)))结构数据
- 元素个数,(下标,元素的值),(下标,元素的值)…
- 在MLlib的数据支持格式中 , 目前仅支持整数和浮点型数
- 创建方式上
-
Labled Point标签向量,让用户能够分类不同的数据集合
-
通过指定Vectors给定dense或sparse等向量
-
从mllib.regression.LabeledPoint中获取lablepoint通过该方法给特征进行标签赋值
-
Spark读取libsvm格式数据
-
https://www.csie.ntu.edu.tw/~cjlin/libsvm/
-
鸢尾花-----花瓣的长度和宽度、花萼的长度和宽度
-
鸢尾花几种类别—三种类别—setosa、versicolor、vernica
1 1:-0.555556 4:-0.916667 1 1:-0.666667 2:-0.166667 3:-0.864407 4:-0.916667 1 1:-0.777778 3:-0.898305 4:-0.916667 1 1:-0.833333 2:-0.0833334 3:-0.830508 4:-0.916667 1 1:-0.611111 2:0.333333 3:-0.864407 4:-0.916667 1 1:-0.388889 2:0.583333 3:-0.762712 4:-0.75 1 1:-0.833333 2:0.166667 3:-0.864407 4:-0.833333 1 1:-0.611111 2:0.166667 3:-0.830508 4:-0.916667 1 1:-0.944444 2:-0.25 3:-0.864407 4:-0.916667 1 1:-0.666667 2:-0.0833334 3:-0.830508 4:-1 1 1:-0.388889 2:0.416667 3:-0.830508 4:-0.916667 1 1:-0.722222 2:0.166667 3:-0.79661 4:-0.916667 1 1:-0.722222 2:-0.166667 3:-0.864407 4:-1 1 1:-1 2:-0.166667 3:-0.966102 4:-1 1 1:-0.166667 2:0.666667 3:-0.932203 4:-0.916667 1 1:-0.222222 2:1 3:-0.830508 4:-0.75 1 1:-0.388889 2:0.583333 3:-0.898305 4:-0.75-
libsvm格式非常适合于稀疏性数据(0值元素较多非0元素较少的情况)
-
SparkMLlib读取LibSvm数据,libsvm数据格式为:Label index1:value1 index2:value2 …
-
2 1:5 2:8 3:9(索引从1开始,从0开始会报错) 1 1:7 2:6 3:7 1 1:3 2:2 3:1
-
-
(2.0列别标签,(9元素个数,[0,1,2]下标,[5.0,8.0,9.0]值)) (1.0,(9,[0,1,2],[7.0,6.0,7.0])) (1.0,(9,[0,1,2],[3.0,2.0,1.0])) (2.0,(9,[0,1,2],[5.0,8.0,9.0]))
-
-
矩阵
-
LocalMatrix–本地矩阵
- MLlib中的局部矩阵以列主要顺序存储
val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0)) //dense(行数 , 列数 , 数组()) println(dm(2,0)) // Create a sparse matrix ((9.0, 0.0), (0.0, 8.0), (0.0, 6.0)) val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8)) println(sm(2,1))//6 println(sm(2,0))//0 //sparse(行数,列数,数组1--列索引(),数组2--行索引(),数组3--数值()) //没有的为0- 分布式矩阵(了解)
- 在MLlib实现了三类分布式矩阵存储格式,分别是**行矩阵(RowMatrix)、行索引矩阵(IndexedRowMatrix)、三元组矩阵(CoordinateMatrix)和分块矩阵(BlockMatrix)**等四种。
-
-
3.统计量的MLLIB实现
- 基于均值、方差、极差、分层抽样、假设检验等方面
4.Mllib抽取-转换-选择之特征提取器
-
提取(抽取) : 从"原始"数据中提取要素
-
转换 : 缩放 , 转换或修改功能
-
选择 : 从更大的功能集中选择子集
-
TF-IDF–适用于文本分析----自然语言的文本处理之中 ---- 常用与基于内容的推荐
-
TF-IDF可以筛选掉不是非常常用的关键词
-
Word2Vec词向量工具----一个词能够使用不同词向量表示
-
[[0.03173386193811894,0.009443491697311401,0.024377789348363876]]
-
建议自学word2vec原理
-
word2vec缺陷
-
1是词语数量较大时,向量维度高且稀疏,向量矩阵巨大而难以存储
-
2是向量并不包含单词的语义内容,只是基于数量统计。
-
3是当有新的词加入语料库后,整个向量矩阵需要更新
-
利用skip-gram算法克服上述三个缺陷
-
隐藏层 : 根据最终需要获取的词向量维数决定隐藏神经元就是多少个
-
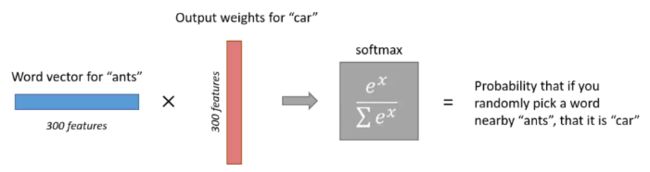
-
skip-gram算法构造的神经网络神经元太多了,导致权重矩阵非常大 , 导致数据难以训练
-
负抽样 : 主要解决模型难以训练
-
使用SGD(最速下降法)训练神经网络的过程就是抽取一条样本数据 , 然后据此去调整神经网络的
所有权重==>所有权重导致数据难以训练 -
负抽样解决方法就是使得对每一条样本的每一次训练 , 只更新很小的一部分的权重, 而不是全部更新
-
让我们用一个例子来具体感受一下。假设我们负抽样的维度数为5,我们的词表中有10000个单词,词向量的维度为300,也即是隐藏层有300个神经元。 那么,在输出层,权重矩阵的大小将是300*10000。现在我们抽取了5个负的维度(输出应当为0的维度),加上输出为1的维度,只更新这6个维度所对应的神经元。那么需要更新的权重系数是300*6=1800个。这只占输出层中所有权重系数的0.06%!! 为什么是300*6????? -
如何抽样?
- 根据单词在语料库中出现的次数多少来的 , 出现的次数越多 , 抽到的可能性越大
-
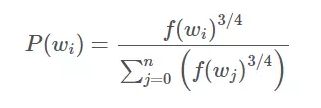 * P(w_i)就是w_i这个单词被负抽样抽中的概率。f(w_i)即是w_i在语料库中出现的次数。
* P(w_i)就是w_i这个单词被负抽样抽中的概率。f(w_i)即是w_i在语料库中出现的次数。
* 至于为什么要取一次3/4次方,据说是基于经验,这样效果会更好。
-
CountVector–处理文本中的词频,按照词频进行原文本的排序(按照原文本顺序?次数排序?)
CountVectorizer并CountVectorizerModel旨在帮助将一组文本文档转换为令牌计数的向量。当apriori字典不可用时,CountVectorizer可以用作Estimator提取词汇表,并生成一个CountVectorizerModel。该模型为词汇表上的文档生成稀疏表示,然后可以将其传递给其他算法,如LDA。- 在拟合过程中,
CountVectorizer将选择vocabSize按语料库中的术语频率排序的顶部单词。可选参数minDF还通过指定术语必须出现在文档中的最小数量(或<1.0)来影响拟合过程。另一个可选的二进制切换参数控制输出向量。如果设置为true,则所有非零计数都设置为1.这对于模拟二进制而非整数计数的离散概率模型特别有用。
5.Mllib抽取-转换-选择之特征转换
-
n-gram中的n就是选取出现频率较多的n个词来进行匹配
-
二值化
-
import org.apache.spark.ml.feature.Binarizer import org.apache.spark.sql.SparkSession object Binaziner_3 { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val data = Array((0, 0.1), (1, 0.8), (2, 0.2)) val dataFrame = spark.createDataFrame(data).toDF("label", "feature") val binarizer: Binarizer = new Binarizer() .setInputCol("feature") .setOutputCol("binarized_feature") .setThreshold(0.5) //小于0.5为0 , 大于0.5为1 val binarizedDataFrame = binarizer.transform(dataFrame) val binarizedFeatures = binarizedDataFrame.select("binarized_feature") binarizedFeatures.collect().foreach(println) } } //输出 //[0.0] //[1.0] //[0.0]
-
-
stringtoindexer : 将标签的字符串列编码为标签索引项 . 索引
[0, numLabels)按标签频率排序,因此最常用的标签获得索引0。-
import org.apache.spark.ml.feature.StringIndexer import org.apache.spark.sql.SparkSession object StringIndex { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val df = spark.createDataFrame( Seq((0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")) ).toDF("id", "category") val indexer = new StringIndexer() .setInputCol("category") .setOutputCol("categoryIndex") val indexed = indexer.fit(df).transform(df) indexed.show() //输出 // +---+--------+-------------+ // | id|category|categoryIndex| // +---+--------+-------------+ // | 0| a| 0.0| // | 1| b| 2.0| // | 2| c| 1.0| // | 3| a| 0.0| // | 4| a| 0.0| // | 5| c| 1.0| // +---+--------+-------------+ } }
-
-
indextoString : 一列标签索引映射回包含原始标签作为字符串的列。一个常见的用例是从标签生成索引
StringIndexer,使用这些索引训练模型,并从预测索引列中检索原始标签IndexToString。但是,可以自由提供自己的标签。 -
StandardScaler :
StandardScaler转换Vector行的数据集,将每个要素标准化以具有单位标准差和/或零均值。-
需要的参数 :
withStd:默认为True。将数据缩放到单位标准偏差。withMean:默认为False。在缩放之前使用均值将数据居中。它将构建一个密集的输出,因此这不适用于稀疏输入并将引发异常。
-
import org.apache.spark.sql.SparkSession object StandScater { def main(args: Array[String]): Unit = { import org.apache.spark.ml.feature.StandardScaler val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val dataFrame = spark.read.format("libsvm").load("I:\\ideaworkspace\\Saprk_Test_ML\\src\\main\\scala\\cn\\apple\\BigDataMachineLearningPro\\sample_libsvm_data.txt") val scaler = new StandardScaler() .setInputCol("features") .setOutputCol("scaledFeatures") .setWithStd(true) .setWithMean(false) // Compute summary statistics by fitting the StandardScaler. val scalerModel = scaler.fit(dataFrame) // Normalize each feature to have unit standard deviation. val scaledData = scalerModel.transform(dataFrame) scaledData.show() // +-----+--------------------+--------------------+ // |label| features| scaledFeatures| // +-----+--------------------+--------------------+ // | 0.0|(692,[127,128,129...|(692,[127,128,129...| // | 1.0|(692,[158,159,160...|(692,[158,159,160...| // | 1.0|(692,[124,125,126...|(692,[124,125,126...| // | 1.0|(692,[152,153,154...|(692,[152,153,154...| // | 1.0|(692,[151,152,153...|(692,[151,152,153...| // | 0.0|(692,[129,130,131...|(692,[129,130,131...| // | 1.0|(692,[158,159,160...|(692,[158,159,160...| // | 1.0|(692,[99,100,101,...|(692,[99,100,101,...| // | 0.0|(692,[154,155,156...|(692,[154,155,156...| // | 0.0|(692,[127,128,129...|(692,[127,128,129...| // | 1.0|(692,[154,155,156...|(692,[154,155,156...| // | 0.0|(692,[153,154,155...|(692,[153,154,155...| // | 0.0|(692,[151,152,153...|(692,[151,152,153...| // | 1.0|(692,[129,130,131...|(692,[129,130,131...| // | 0.0|(692,[154,155,156...|(692,[154,155,156...| // | 1.0|(692,[150,151,152...|(692,[150,151,152...| // | 0.0|(692,[124,125,126...|(692,[124,125,126...| // | 0.0|(692,[152,153,154...|(692,[152,153,154...| // | 1.0|(692,[97,98,99,12...|(692,[97,98,99,12...| // | 1.0|(692,[124,125,126...|(692,[124,125,126...| // +-----+--------------------+--------------------+ // only showing top 20 rows } }
-
-
Bucketizer 分箱 , 分桶 :
Bucketizer将一列连续特征转换为一列要素存储区,其中存储区由用户指定。它需要一个参数:-
splits:用于将连续要素映射到存储桶的参数。对于n +1个分裂,有n个桶。由splits x,y定义的存储区包含除最后一个存储区之外的[x,y]范围内的值,该存储区还包括y。 -
import org.apache.spark.sql.SparkSession object Bucketizer { def main(args: Array[String]): Unit = { import org.apache.spark.ml.feature.Bucketizer val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val splits = Array(Double.NegativeInfinity, -0.5, 0.0, 0.5, Double.PositiveInfinity) val data = Array(-0.5, -0.3, 0.0, 0.2) val dataFrame = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features") val bucketizer = new Bucketizer() .setInputCol("features") .setOutputCol("bucketedFeatures") .setSplits(splits) // Transform original data into its bucket index. val bucketedData = bucketizer.transform(dataFrame) bucketedData.show() // +--------+----------------+ // |features|bucketedFeatures| // +--------+----------------+ // | -0.5| 1.0| // | -0.3| 1.0| // | 0.0| 2.0| // | 0.2| 2.0| // +--------+----------------+ } } //结果解释 : -0.5和-0.3都在1号桶 , 0和0.2在2号桶 //桶的编号从0开始???
-
-
SQLTransformer
-
import org.apache.spark.ml.feature.SQLTransformer import org.apache.spark.sql.SparkSession object SqlTransformer { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val df = spark.createDataFrame( Seq((0, 1.0, 3.0), (2, 2.0, 5.0))).toDF("id", "v1", "v2") df.show() // +---+---+---+ // | id| v1| v2| // +---+---+---+ // | 0|1.0|3.0| // | 2|2.0|5.0| // +---+---+---+ val sqlTrans = new SQLTransformer().setStatement( "SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__") sqlTrans.transform(df).show() // +---+---+---+---+----+ // | id| v1| v2| v3| v4| // +---+---+---+---+----+ // | 0|1.0|3.0|4.0| 3.0| // | 2|2.0|5.0|7.0|10.0| // +---+---+---+---+----+ } } //结果解读 : 将低维的数据进行增加维度 , 是对原来维度的整合 , 特征融合
-
-
QuantileDiscretizer : 连续属性离散化 —分位数
-
QuantileDiscretizer采用具有连续特征的列,并输出具有分箱分类特征的列。箱数由numBuckets参数设定。 -
import org.apache.spark.sql.SparkSession object QuantileDiscreator { def main(args: Array[String]): Unit = { import org.apache.spark.ml.feature.QuantileDiscretizer val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val data = Array((0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2)) var df = spark.createDataFrame(data).toDF("id", "hour") val discretizer = new QuantileDiscretizer() .setInputCol("hour") .setOutputCol("result") .setNumBuckets(3) val result = discretizer.fit(df).transform(df) result.show() // +---+----+------+ // | id|hour|result| // +---+----+------+ // | 0|18.0| 2.0| // | 1|19.0| 2.0| // | 2| 8.0| 1.0| // | 3| 5.0| 1.0| // | 4| 2.2| 0.0| // +---+----+------+ } }
-
6.Mllib抽取-转换-选择之特征选择器
-
特征选择VectorSlicer是一个变换器 , 它采用一个特征向量 ,并输出一个带有原始特征子阵列的新特征向量。
-
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute} import org.apache.spark.ml.feature.VectorSlicer import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.{Row, SparkSession} import org.apache.spark.sql.types.StructType object VectorSlicer_4 { def main(args: Array[String]): Unit = { import java.util.Arrays val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val data = Arrays.asList(Row(Vectors.dense(-2.0, 2.3, 0.0))) val defaultAttr = NumericAttribute.defaultAttr val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName) val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]]) val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField()))) val slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") slicer.setIndices(Array(1)).setNames(Array("f3")) //or slicer.setIndices(Array(1, 2)), or slicer.setNames(Array("f2", "f3")) val output = slicer.transform(dataset) println(output.select("userFeatures", "features").first()) //[[-2.0,2.3,0.0],[2.3,0.0]] } }
-
-
RFormula根据R公式
-
RFormula选择由R模型公式指定的列。目前,我们支持R运算符的有限子集,包括'〜','。',':','+'和' - '。基本的运营商是: • ~ 单独的目标和条款 • + concat术语,“+ 0”表示删除拦截 • - 删除一个术语,“ - 1”表示删除拦截 • : 交互(数值乘法或二进制分类值) • . 除目标之外的所有列 -
import org.apache.spark.ml.feature.RFormula import org.apache.spark.sql.SparkSession object RSelectElement { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val dataset = spark.createDataFrame(Seq( (7, "US", 18, 1.0), (8, "CA", 12, 0.0), (9, "NZ", 15, 0.0) )).toDF("id", "country", "hour", "clicked") val formula = new RFormula() .setFormula("clicked ~ country + hour") .setFeaturesCol("features") .setLabelCol("label") val output = formula.fit(dataset).transform(dataset) output.select("features", "label").show() // +--------------+-----+ // | features|label| // +--------------+-----+ // |[0.0,0.0,18.0]| 1.0| // |[1.0,0.0,12.0]| 0.0| // |[0.0,1.0,15.0]| 0.0| // +--------------+-----+ } }
-
-
卡方验证Chisquare
-
ChiSqSelector代表Chi-Squared特征选择。它使用具有分类特征的标记数据进行操作。ChiSqSelector根据 类的独立性Chi-Squared测试来命令特征 ,然后过滤(选择)类标签最依赖的顶级特征。这类似于产生具有最强预测能力的特征。-
import org.apache.spark.ml.feature.ChiSqSelector import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession object chiSquare { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName("SparkMlilb") .master("local[2]") .getOrCreate() spark.sparkContext.setLogLevel("WARN") val data = Seq( (7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0), (8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0), (9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0) ) val df = spark.createDataset(data).toDF("id", "features", "clicked") val selector = new ChiSqSelector() .setNumTopFeatures(1) .setFeaturesCol("features") .setLabelCol("clicked") .setOutputCol("selectedFeatures") val result = selector.fit(df).transform(df) result.show() } }
-
6-1.最小二乘法
- 最小二乘法–数学上重要方法 — 不一定能得到最优解
- f(x)预测值 ---- y真实值
- 构建平方损失Loss=sum{(y-f(x))**2}
- 求解Loss的导数,关于参数求导
- 令导数为0,得到参数求解的公式,利用公式迭代求解参数
- 最终得到参数最优解
- 和梯度下降法结合理解
7.ALS 实战从行为数据到评分再到预测-API简介
- ALS—交替最小二乘法算法学习潜在因素
- 几个参数:
- numblocks分块个数----默认为10
- rank隐因子个数----默认为10
- maxiterator迭代次数----默认10
- regparrm正则化参数----默认1.0
- implictPref显式反馈----默认false
- alpha隐式反馈的参数—置信参数----默认1.0
- nonnegative非负最小二乘法----默认false
- 显式反馈和隐式反馈
- 用户有明确的喜好,如打分,显式反馈
- 用户没有明确打分,但是有点击、浏览、收藏等行为,构成隐式反馈,通过alpha参数控制隐式反馈的参数
- 正则化参数
- 主要通过正则化参数达到控制参数的复杂度,防止模型的过拟合
- 冷启动策略
- 设置nan方式,但是会因为设置了nan评价参数业务nan —默认方式
- 设置drop方式,进一步在构建模型的时候不处理新加入的用户或商品
- SparkMl上调用Spark的ALS包
- 基于dataframe
- new ALS()添加参数
- SparkMLLIB上调用Spark的ALS包
- 基于rdd的
- ALS.train()
8.ALS 实战从行为数据到评分再到预测-需求分析与说明
- ALS实战电商数据
- 数据来源:从大数据工程师处理好的结构化的数据给到算法工程师
- 数据格式:[user,itemid,type,timestamp,times]
- 对userid列来讲拿到的数据是需要处理的,采用stringIndexer将string类型的user转换为数值类型供计算
9.ALS 实战从行为数据到评分再到预测-实战
@Since("0.8.0")
case class Rating @Since("0.8.0") (
@Since("0.8.0") user: Int,
@Since("0.8.0") product: Int,
@Since("0.8.0") rating: Double)
- 通过Spark处理数据成为Rating接受的类型—userid(int)+itemid(int)+rating(double)
- [user,itemid,type,timestamp,times]
- 处理user---->usercode---->userid----使用的方法是StringIndex(转化为datafrmame进行fit和transform)
- 处理type设置不同分数
- pv浏览=1分
- fav收藏=3分
- buy购买=10分
- 设置rating打分规则
- type数值化*times=得到得分
- 处理数据完毕
- 引入算法+数据=>模型
- SparkMllib中的ALS算法
- Als.train(numblocks,rank,regparam,iteration)
- predictions=als.predict
- rmse进行预测
- 输出推荐结果—uid+itemid+rating排序
10-ALS算法入门与LFM区别和联系
- LFM-Latent Factor machine隐因子分析模型
- Y=A*B
- Y矩阵分解为两个矩阵的乘积的形式,通过随机初始化A矩阵和B矩阵,构建损失函数,利用梯度下降法,近似求解A和B矩阵的最优解
- ALS是在LFM基础上使用的交替的最小二乘法的方式进行参数的求解
- 固定U矩阵求解V矩阵
- 固定V矩阵求解U矩阵
11-ALS算法实战基础推荐
- 使用Scala完成协同过滤算法或余弦相似度的推荐(参考)
- ALS算法实战userid-itemid-rating得到模型的结果(理解)
- 参考文档中代码https://github.com/ljcan/Spark-Scala/blob/MLlib/CollaborativeFilter.scala
- 余弦相似度
package com.itck.als
import org.apache.spark.metrics.source
import org.apache.spark.{SparkConf, SparkContext}
/**
* 余弦相似度
*/
object ConsineSimilar {
val conf = new SparkConf()
.setAppName("ConsineSimilar")
.setMaster("local")
val sc = new SparkContext(conf)
//实例化环境
val users = sc.parallelize(Array("aaa", "bbb", "ccc", "ddd", "eee"))
//设置电影名
val films = sc.parallelize(Array("smzdm", "yixb", "znh", "nhsc", "fcwr"))
//使用一个 source 嵌套 map 作为姓名电影名和分值的存储
var source = Map[String, Map[String, Int]]()
//设置一个用以存放电影分的 map
val filmSource = Map[String, Int]()
/**
* 设置电影评分
*
* @return
*/
def getSource(): Map[String, Map[String, Int]] = {
val user1FilmSource = Map("smzdm" -> 2, "yixb" -> 3, "znh" -> 1, "nhsc" -> 0, "fcwr" -> 1)
val user2FilmSource = Map("smzdm" -> 1, "yixb" -> 2, "znh" -> 2, "nhsc" -> 1, "fcwr" -> 4)
val user3FilmSource = Map("smzdm" -> 2, "yixb" -> 1, "znh" -> 0, "nhsc" -> 1, "fcwr" -> 4)
val user4FilmSource = Map("smzdm" -> 3, "yixb" -> 2, "znh" -> 0, "nhsc" -> 5, "fcwr" -> 3)
val user5FilmSource = Map("smzdm" -> 5, "yixb" -> 3, "znh" -> 1, "nhsc" -> 1, "fcwr" -> 2)
source += ("aaa" -> user1FilmSource) //对人名进行存储
source += ("bbb" -> user2FilmSource) //对人名进行存储
source += ("ccc" -> user3FilmSource) //对人名进行存储
source += ("ddd" -> user4FilmSource) //对人名进行存储
source += ("eee" -> user5FilmSource) //对人名进行存储
source //返回 map
}
/**
* 计算余弦相似性
*
* @param user1
* @param user2
* @return
*/
def getCollaborateSource(user1: String, user2: String): Double = {
//获得第一个用户的评分
val user1FilmSource = source.get(user1).get.values.toVector
//获得第二个用户的评分
val user2FileSource = source.get(user2).get.values.toVector
//对欧几里得公式分子部分进行计算
val member =
user1FilmSource.zip(user2FileSource).map(num => num._1 * num._2).reduce(_ + _).toDouble
//求出分母第一个变量的值
val temp1 = math.sqrt(user1FilmSource.map(num => {
math.pow(num, 2)
}).reduce(_ + _)).toDouble
//求出分母第二个变量的值
val temp2 = math.sqrt(user2FileSource.map(num => {
math.pow(num, 2)
}).reduce(_ + _)).toDouble
//求出分母
val denominator = temp1 * temp2
//返回结果
member / denominator
}
def main(args: Array[String]): Unit = {
//初始化分数
getSource()
//设定目标对象
val name = "bbb"
//迭代进行计算
users.foreach(user => {
println(name + " 相对于 " + user + "的相似性分数为: " + getCollaborateSource(name, user))
})
val frist = users.sortBy((user => getCollaborateSource(name, user)), false, 1).first()
println("-----------------------------------------------------------")
println("相似度最高的用户为:" + frist)
/**
* 计算结果如下:
* bbb 相对于 aaa 的相似性分数为: 0.7089175569585667
* bbb 相对于 bbb 的相似性分数为: 1.0000000000000002
* bbb 相对于 ccc 的相似性分数为: 0.8780541105074453
* bbb 相对于 ddd 的相似性分数为: 0.6865554812287477
* bbb 相对于 eee 的相似性分数为: 0.6821910402406466
*/
}
}
- 建模
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.{SparkConf, SparkContext}
object CollaborativeFilter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("CollaborativeFilter")
.setMaster("local")
val sc = new SparkContext(conf)
//设置数据集
val data = sc.textFile("..\\d.txt")
//处理数据
val ratings = data.map(_.split(" ") match {
case Array(user, item, rate) => //转化数据集
Rating(user.toInt, item.toInt, rate.toDouble) //将数据集转化为专用的 Rating
})
val rank = 2 //设置隐藏因子
val numIterations = 2 //设置迭代次数
val model = ALS.train(ratings, rank, numIterations, 0.01) //进行模型训练
val rs = model.recommendProducts(2, 1) //为用户 2 推荐一个商品
rs.foreach(println) //打印推荐结果
val result: Double = rs(0).rating //预测的评分结果
val realilty = data.map(_.split(" ") match {
case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
}).map(num => {
if (num.user == 2 && num.product == 15)
num.rating //返回实际评分结果
else
0
}).foreach(num => {
if (num != 0)
println("对 15 号商品预测的准确率为:" + (1 - (math.abs(result - num) / 1)))
})
}
}
12-ALS算法原理详解
- ALS算法利用交替最小二乘法最优解算法结合LFM的矩阵分解方式进行学习其中参数
- SVD将一个大的评分矩阵分解为了三个矩阵SVD(X)=U*Sigma*VT
- 注 : 在使用SVD方法前 , 大的评分矩阵需要被补全
- 算法的时间复杂度较高的
- SVD算法要求矩阵的数值是填充的
- Sigma存放奇异值
- A*Y(Y.T*Y).inv=X
13-ALS算法步骤详解
交替最小二乘法是对最小二乘法处理多个变量时的扩展- 算法推导图解

- 推导过程

- ALS算法思路:固定一个矩阵求解另外一个矩阵的导数,固定一个矩阵求解另外一个矩阵的导数
- ALS算法步骤:
- 构建损失函数,Loss=(r-r_pred)**2+lambda1*u+lambda2*v
- 固定U矩阵求解V矩阵
- v=M1.inv*M2 其中M1和M2是关于U的矩阵的运算
- 固定V矩阵求解U矩阵
- u=M1.inv*M2 其中M1和M2是关于V的矩阵的运算
- 满足迭代次数停止
14-ALS算法显示反馈与隐式反馈
- 显式反馈直接通过显式打分进行矩阵分解
- 隐式反馈从数学层面讲,引入alpha置信参数,R是交互次数
- 隐式反馈特点
- 没有负反馈
- 隐式反馈是内在的噪音
- 显示反馈的数值表示偏好 , 隐式反馈数值表示信任 ; 一个较大的值并不能表明更多的偏爱 。 但是这个值是有用的 , 它描述了在一个特定观察中的信任度。
- 评价隐式反馈推荐系统需要合适的手段。
- 隐式反馈特点
- 定义隐式反馈的损失函数的参数:C=1+R*alpha ====R表示信任度 , alpha表示置信参数
- Loss=C*(r-r_pred)**2+lambda1*u+lambda2*v
15-ALS算法源码简介
-
了解ALS算法源码部分
-
ALS算法并行化
- partitionRatings—将原始评分数据分片成块
- numblocks—控制通信的复杂度和计算复杂度
- makeblocks—inblock存储评分数据和outblock存储因子关联数据
- inblock存储的格式[u1,u2,u3,u4]----[v1,v2,v3,v4]----[r1,r2,r3,r4]
- outblock-----srtblock和Dstblockid映射关联数据
https://issues.apache.org/jira/browse/SPARK-3066
http://www.csdn.net/article/2015-05-07/2824641
https://blog.csdn.net/buptfanrq/article/details/73299116
16.ALS推荐算法在Spark上的优化
- 参考https://blog.csdn.net/butterluo/article/details/48271361
- Spark+Kafka流优化https://blog.csdn.net/butterluo/article/details/47083773
- ALS优化场景
- ALS加载数据
- 使用Hadoop的 CombineFileInputFormat类进行小文件合并成split在加载到spark中,加快了加载数据速度
- ALS预测计算
- 优化JVM中参数,效果不明显
- 通过源码查看—看到了源码部分中ALS使用了笛卡尔积操作=====>复杂度是指数级别(复杂度极高)
- 在笛卡尔积的之前进行预处理分block块----420000块
- 在预分块之前做一个预分区----加快数据分不到不同分区和block块下面进行处理的速度
- ALS加载数据
17.SVD推荐算法简介
- 参考课件图示理解
18.PySpark基础环境搭建(了解)
- PySpark环境搭建
- 准备好大数据环境
- jdk
- hadoop2.7.4
- spark2.3.3
- 缺少组件
- 准备好Python环境
- Anaconda
- Python原生环境
- 结合形成Pyspark
- 复制spark源码包中的python目录下面的pyspark目录到Lib下面的site-packages
19.构建PySpark简单推荐系统(了解)
- 通过pyspark构建推荐系统
- 使用python数据科学包有一个pandas的包进行数据科学开发
- 使用pyspark完成简单推荐系统
- 使用pandas处理数据格式为-userid+itemid+rating打分
- 使用pyspark中als算法进行训练模型
- 使用模型预测5个喜欢的歌手
- 将喜欢的歌手id和歌手名字进行关联进行输出
20.总结
SparkMLlib&ALS
