Java基本概念
目录
1、Java程序初始化顺序
2、反射
4、注解
5、泛型
6、字节与字符的区别
7、访问修饰符
8、深克隆与浅克隆
1、Java程序初始化顺序
初始化一般遵循3个原则:
- 静态对象(变量)优先非静态变量,静态变量只初始化一次,而非静态变量可能会多次初始化;
- 父类优先于子类进行初始化;
- 按照成员变量的定义顺序进行初始化。即使变量定义散布于方法定义之中,他们依然在任何方法被调用之前先初始化。
加载顺序
- 父类(静态变量,静态语句块)
- 子类(静态变量,静态语句块)
- 父类(实例变量,普通语句块)
- 父类(构造函数)
- 子类(实例变量,普通语句块)
- 子类(构造函数)
/**
* @author King Chen
* @Date: 2019/3/1 16:02
*/
public class Derived extends Base {
// 2.子类静态代码块
static {
System.out.println("Derived static block!");
}
// 5.子类非静态代码块
{
System.out.println("Derived block!");
}
// 6.子类构造器
public Derived() {
System.out.println("Derived constructor!");
}
public static void main(String[] args) {
new Derived();
}
}
class Base {
// 1.父类静态代码块
static {
System.out.println("Base static block!");
}
// 3.父类非静态代码块
{
System.out.println("Base block");
}
// 4.父类构造器
public Base() {
System.out.println("Base constructor!");
}
}输出结果:
Base static block!
Derived static block!
Base block
Base constructor!
Derived block!
Derived constructor!2、反射
这里我就不多说了,相信大家看了之前发过的帖子就了解啦。Java——反射
4、注解
什么是注解
Annotation是java5开始引入的新特征。提供了一种安全的类似注释的机制,用来将任何信息或元数据与程序元素(类、方法、成员变量等)进行关联。为程序的元素......加上更直观更明了的说明,这些说明信息与程序的业务逻辑无关,而是供给制定的工具或者框架使用。Annotation像一种修饰符一样,应用于包、类型、构造方法、方法、成员变量、参数以及本地变量的生命语句中。
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。包含在 java.lang.annotation 包中。
简单来说:注解其实就是代码中的特殊标记,这些标记可以在编译、类加载、运行时被读取,并执行相对应的处理。
为什么要使用注解
传统的方式,我们是通过配置文件 .xml 来告诉类是如何运行的。
有了注解技术以后,我们就可以通过注解告诉类如何运行
例如:我们以前编写 Servlet 的时候,需要在 web.xml 文件配置具体的信息。我们使用了注解以后,可以直接在 Servlet 源代码上,增加注解...Servlet 就被配置到 Tomcat 上了。也就是说,注解可以给类、方法上注入信息。
明显地可以看出,这样是非常直观的,并且 Servlet 规范是推崇这种配置方式的。
如何使用注解
看看这篇文章吧
JDK1.8之Annotation注解一基础篇
工作总结——Aspect注解式切面
5、泛型
泛型类
/**
* @author King Chen
* @Date: 2019/3/1 16:52
*/
public class Box {
private T t;
public static void main(String[] args) {
Box integerBox = new Box();
Box stringBox = new Box();
integerBox.add(new Integer(10));
stringBox.add(new String("菜鸟教程"));
System.out.printf("整型值为 :%d\n\n", integerBox.get());
System.out.printf("字符串为 :%s\n", stringBox.get());
}
public void add(T t) {
this.t = t;
}
public T get() {
return t;
}
} 泛型方法
/**
* @author King Chen
* @Date: 2019/3/1 16:53
*/
public class GenericMethodTest {
// 泛型方法 printArray
public static void printArray(E[] inputArray) {
// 输出数组元素
for (E element : inputArray) {
System.out.printf("%s ", element);
}
System.out.println();
}
public static void main(String args[]) {
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = {1, 2, 3, 4, 5};
Double[] doubleArray = {1.1, 2.2, 3.3, 4.4};
Character[] charArray = {'H', 'E', 'L', 'L', 'O'};
System.out.println("整型数组元素为:");
printArray(intArray); // 传递一个整型数组
System.out.println("\n双精度型数组元素为:");
printArray(doubleArray); // 传递一个双精度型数组
System.out.println("\n字符型数组元素为:");
printArray(charArray); // 传递一个字符型数组
}
} 类型通配符
- 类型通配符一般是使用
?代替具体的类型参数。例如List在逻辑上是List,List等所有 List<具体类型实参> 的父类。 - 类型通配符上限通过形如 List 来定义,如此定义就是通配符泛型值接受 Number 及其下层子类类型。
- 类型通配符下限通过形如 List 来定义,表示类型只能接受 Number 及其三层父类类型,如 Objec 类型的实例。
6、字节与字符的区别
总是在说,字节流,字符流,InputStream,reader。。。。。。到底什么是字节,什么是字符?这两个容易混淆的概念,就来准确区分:
| 类型 | 概念描述 | 举例 |
| 字符 | 人们使用的几号,抽象意义上的一个符号 | '1','a','%',...... |
| 字节 | 计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间 | 0x01,0x45,0xFA,...... |
| ANSI字符串 | 在内存中,如果”字符“是以ANSI编码格式存在,一个字符可能使用一个字节或多个字节来表示,那么我们称这种字符串位ANSI字符串 | ”中文222“(7个字节) |
| UNICODE字符串 | 在内存中,如果”字符”是以在UNICODE中的序号存在的,那么我们成这种字符串位UNICODE字符串 | L”中文222“(10个字节) |
字节与字符区别
它们完全不是一个位面的概念,所以两者之间没有“区别”这个说法。不同编码里,字符和字节的对应关系不同:
| 类型 | 概念描述 |
| ASCII | 一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为 8 位二进制数,换算为十进制。最小值 0,最大值 255 |
| UTF-8 | 一个英文字符等于一个字节,一个中文(含繁体)等于三个字节 |
| Unicode | 一个英文等于两个字节,一个中文(含繁体)等于两个字节。符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占 1 个字节的大小,中文句号“。”占 2 个字节的大小 |
| UTF-16 | 一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode扩展区的一些汉字存储需要4个字节) |
| UTF-32 | 世界上任何字符的存储都需要 4 个字节 |
7、访问修饰符
| 修饰符 | 当前类 | 同 包 | 子 类 | 其他包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
8、深克隆与浅克隆
- 浅克隆:被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅拷贝仅仅复制所拷贝的对象,而不复制它所引用的对象。
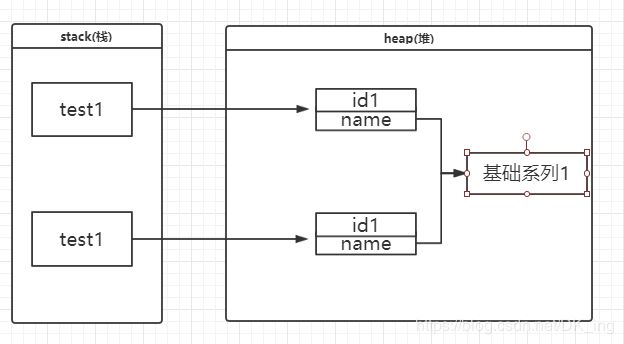
- 深克隆:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
