Go 语言进阶——函数-变量-类型-并发 基础
Go gc
时下流行的语言大都是运行在虚拟机上,如:Java 和 Scala 使用的 JVM,C# 和 VB.NET 使用的 .NET CLR。而go同样通过虚拟机,采用标记-清除回收器管理内存,尽管虚拟机的性能已经有了很大的提升,但任何使用 JIT 编译器和脚本语言解释器的编程语言(Ruby、Python、Perl 和 JavaScript)在 C 和 C++ 的绝对优势下甚至都无法在性能上望其项背
函数
func functionName(parameter_list) (return_value_list) { … }
parameter_list 的形式为 (param1 type1, param2 type2, …)
return_value_list 的形式为 (ret1 type1, ret2 type2, …)只有当某个函数需要被外部包调用的时候才使用大写字母开头,并遵循 Pascal 命名法;类内部调用均首字母小写
特殊函数
- 每个源文件都只能包含一个 init 函数。初始化总是以单线程执行,并且按照包的依赖关系顺序执行。
- 如果当前包是 main 包,则定义 main 函数。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。包名都应该使用小写字母
- 变参函数
func F1(s ...string) {
F2(s...) F3(s)
}- defer 类似java finally 作用,它一般用于释放某些已分配的资源
func function1() {
fmt.Printf("In function1 at the top\n")
defer function2()
fmt.Printf("In function1 at the bottom!\n")
}- go 内置函数
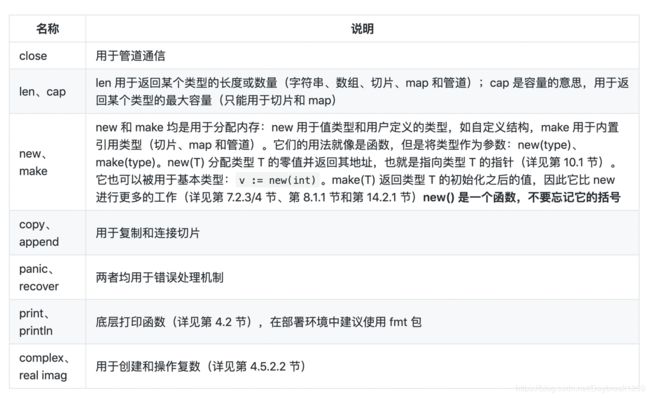
- 函数作为参数
函数可以作为其它函数的参数进行传递,然后在其它函数内调用执行
func main() {
callback(1, Add)
}
func Add(a, b int) {
fmt.Printf("The sum of %d and %d is: %d\n", a, b, a+b)
}
//函数func作为参数传入callback 方法
func callback(y int, f func(int, int)) {
f(y, 2) // this becomes Add(1, 2)
}类型
基本类型,如:int、float、bool、string;
结构化的(复合的),如:struct、array、slice、map、channel;复合,go不存在继承
只描述类型的行为的,如:interface。
int 和 uint 在 32 位操作系统上,它们均使用 32 位(4 个字节),在 64 位操作系统上,它们均使用 64 位(8 个字节)
Go 语言中没有 float和double 类型。只有 float32 和 float64。
类型转换:
Go 语言不存在隐式类型转换,因此所有的转换都必须显式说明,就像调用一个函数一样。注意:
valueOfTypeB = typeB(valueOfTypeA)
小范围转大范围ok,反之,丢失精度。只能在定义正确的情况下转换成功,例如从一个取值范围较小的类型转换到一个取值范围较大的类型(例如将 int16 转换为 int32)。当从一个取值范围较大的转换到取值范围较小的类型时(例如将 int32 转换为 int16 或将 float32 转换为 int),会发生精度丢失(截断)的情况。当编译器捕捉到非法的类型转换时会引发编译时错误,否则将引发运行时错误。
字符串 string
string 工具类:strings 包和strconv包
strconv 与字符串相关的类型转换都是通过 strconv 包实现的
strconv.Itoa(i int) string //数字转string
strconv.Atoi(s string) (i int, err error) //string 转int
strconv.ParseFloat(s string, bitSize int) //string 转float64变量
所有像 int、float、bool 和 string 这些基本类型都属于值类型,使用这些类型的变量直接指向存在内存中的值

一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址(数字),或内存地址中第一个字所在的位置。当使用赋值语句 r2 = r1 时,只有引用(地址)被复制
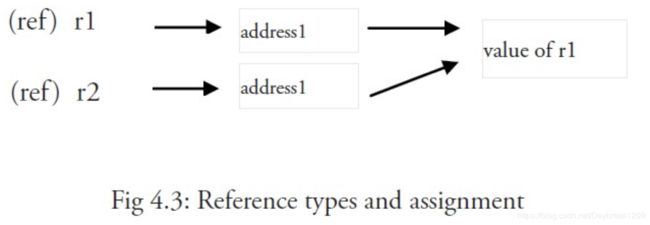
如果 r1 的值被改变了,那么这个值的所有引用都会指向被修改后的内容,在这个例子中,r2 也会受到影响。
被引用的变量会存储在堆中,以便进行垃圾回收,且比栈拥有更大的内存空间。
空白标识符 _
_ 用于表示抛弃值,如值 5 在:_, b = 5, 7 中被抛弃。用于你并不需要使用从一个函数得到的所有返回值,import也同样。
time包
time.Now()
t.Day()、t.Minute() //等等来获取时间的一部分
time.After 或者 time.Ticker 定时执行
time.Sleep(Duration d) //可以实现对某个进程(实质上是 goroutine)时长为 d 的暂停
结构
- if-else 结构
- switch 结构
- select 结构,用于 channel 的选择(第 14.4 节)
- for (range) 结构 break continue
switch result := calculate() {
case result < 0:
...
case result > 0:
...
default: // 0
}
for i := 0; i < 5; i++ {
fmt.Printf("This is the %d iteration\n", i)
}
for index, value := range str {
...
}regexp 包
pattern := "[0-9]+.[0-9]+" //正则
ok, _ := regexp.Match(pattern, []byte(searchIn))
//MatchStringsync并发包
当不同线程要使用同一个变量时,经常会出现一个问题:无法预知变量被不同线程修改的顺序!(资源竞争)
在 Go 语言中这种锁的机制是通过 sync 包来实现的,sync 来源于 "synchronized" 一词,这意味着线程将有序的对同一变量进行访问。
sync.Mutex 是一个互斥锁 ,假设 info是一个需要上锁的放在共享内存中的变量
import "sync"
type Info struct {
sync sync.Mutex
// ... other fields, e.g.: Str string
}
//update更新info结构
func Update(info *Info) {
info.sync.Lock()
// critical section:
info.Str = // new value
// end critical section
info.sync.Unlock()
}sync.RWMutex 锁 :读写锁,多线程同时读,只能一个线程进行写。写法与mutex一样。
sync包中还有一个方便的 Once 类型变量的方法 once.Do(call),这个方法确保被调用函数只能被调用一次,使用如下:
once := sync.Once{}
once.Do(func() {
doInit()
})对于简单多线程操作下,可以使用sync包解决。但如果这种方式导致程序明显变慢或者引起其他问题,我们要重新思考来通过 goroutines 和 channels 来解决问题,这是在 Go 语言中所提倡用来实现并发的技术。