CTR预估 论文精读(三)--Factorization Machines
Abstract
In this paper, we introduce Factorization Machines (FM) which are a new model class that combines the advantages of Support Vector Machines (SVM) with factorization models. Like SVMs, FMs are a general predictor working with any real valued feature vector. In contrast to SVMs, FMs model all interactions between variables using factorized parameters. Thus they are able to estimate interactions even in problems with huge sparsity (like recommender systems) where SVMs fail. We show that the model equation of FMs can be calculated in linear time and thus FMs can be optimized directly. So unlike nonlinear SVMs, a transformation in the dual form is not necessary and the model parameters can be estimated directly without the need of any support vector in the solution. We show the relationship to SVMs and the advantages of FMs for parameter estimation in sparse settings.
On the other hand there are many different factorization models like matrix factorization, parallel factor analysis or specialized models like SVD++, PITF or FPMC. The drawback of these models is that they are not applicable for general prediction tasks but work only with special input data. Furthermore their model equations and optimization algorithms are derived individually for each task. We show that FMs can mimic these models just by specifying the input data (i.e. the feature vectors). This makes FMs easily applicable even for users without expert knowledge in factorization models.
1. FM vs SVM
1.1 SVM 缺陷:
-
支持向量机是机器学习和数据挖掘中最常用的预测模型之一。然而, 在协同过滤等设置中, 支持向量机没有发挥重要作用, 最好的模型要么是标准矩阵/张量分解模型的直接应用, 如 PARAFAC[1], 要么是使用分解参数的特定模型 [2], [3], [4].
本文表明, 标准支持向量机预测器在这些任务中不成功的唯一原因是, 它们在非常稀疏的数据下, 无法在复杂 (非线性) 内核空间中学习到可靠的参数 (“超平面”)。
1.2 Tensor factorization model缺陷
另一方面, 张量分解模型,甚至是特定的因子分解模型的通病则是:
- 不适用于标准预测数据 (例如 R n R^n Rn 中的实值特征向量) ;
- 特定模型通常是为特定任务单独推导出来的, 需要花费大量精力进行建模与学习算法设计。
1.3 Factorization Machine
Factorization Machine(FM) 是一个如SVM一般的通用预测器,但是却能在非常稀少的情况下学习到可靠参数。
因子分解机对所有嵌套变量的交互(nested variable interactions)进行建模 (可与支持向量机中的多项式内核相比较),但使用分解参数化(factorized parametrization),而不是像 svm 中那样密集的参数化。
1.4 FM, SVM 以及collaborative filter对比
FM:
- 结果表明, FM 的模型等式可以在线性时间内完成计算, 并且它只取决于线性数量的参数。
- 这样就可以直接优化和存储模型参数, 而不需要存储任何训练数据 (例如支持向量) 进行预测。
non-linear SVM
- 非线性支持向量机通常依赖部分训练数据 (支持向量)以双重形式(对偶计算)进行优化和计算预测 (模型方程)。
collaborative filter
结果表明,FM超过了很多对于协同过滤任务的成功算法,如带偏置的FM,SVD++,PITF以及FPMC。
1.5 FM优势
- FM 允许在非常稀疏的数据下进行参数估计,而SVM则不能;
- FM具有线型复杂度,可以在原始数据上进行优化,而无需依赖如SVM一般的支持向量;(论文展示了 FM 可扩展到具有1亿个训练实例的大型数据集 (如 Netflix)。)
- FM 是一个通用的预测器, 可以使用任何为真实值的特征矢量。而其他因子分解模型模型仅在非常受限的输入数据上工作。(论文展示, 只要定义输入数据的特征向量, FM 就可以拟合最新的模型, 如biased MF、SVD ++、PITF 或 FPMC。)
2. 多项式模型
2.1 多项式模型形式
考虑一个模型,它的输出由单特征( d d d 维)与组合特征的线性组合构成,如果不看二次项,这就是一个线性回归模型,现在引入了交叉项。
y ( x ) = w 0 + ∑ i = 1 n w i ⋅ x i + ∑ i = 1 n ∑ j = i + 1 n w i j ⋅ x i x j y(\mathbf{x}) = w_0+ \sum_{i=1}^n w_i · x_i + \sum_{i=1}^n \sum_{j=i+1}^n w_{ij}· x_i x_j y(x)=w0+i=1∑nwi⋅xi+i=1∑nj=i+1∑nwij⋅xixj
其中单特征的参数 w i w_i wi 有 d d d 个,组合特征的参数 w i j w_{ij} wij 有 d ( d − 1 ) 2 \frac{d(d-1)}{2} 2d(d−1) 个,且任意两个 w i j w_{ij} wij 之间相互独立。
2.2 交叉项参数训练问题
现在假设目标函数是 L ( y , f ( x ) ) L(y, f(x)) L(y,f(x)),为了使用梯度下降法训练交叉项参数,需要求导:
∂ L ∂ w i j = ∂ L ∂ f ( x ) ⋅ ∂ f ( x ) ∂ w i j = ∂ L ∂ f ( x ) x i x j \frac{\partial L}{\partial w_{ij}} = \frac{\partial L}{\partial f(x)} · \frac{\partial f(x)}{\partial w_{ij}} = \frac{\partial L}{\partial f(x)} x_i x_j ∂wij∂L=∂f(x)∂L⋅∂wij∂f(x)=∂f(x)∂Lxixj
也就是说,每个二次项参数 w i j w_{ij} wij 的训练需要 x i x_i xi 和 x j x_j xj 同时非零,若特征稀疏(例如Onehot过),则一整行中只有一个1,容易导致 w i j w_{ij} wij 训练无法进行。
3. FM
3.1 FM模型
将矩阵 W = w i , j W={w_{i,j}} W=wi,j 矩阵(这是一个对称方阵)分解成 W = V T V W=V^TV W=VTV 的形式,其中 V = ( v 1 , v 2 , ⋯ , v d ) V=(v_1,v_2,⋯,v_d) V=(v1,v2,⋯,vd) 是一个 k × d k \times d k×d 矩阵,且 k ≪ d k≪d k≪d,于是 W W W 矩阵的每一个元素都可以用 V V V 矩阵对应的两列做内积得到: w i j = v i ⋅ v j w_{ij} = v_i ⋅ v_j wij=vi⋅vj,同时多项式模型可以重写,这就是因子分解机模型。
y ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j y(\mathbf{x}) = w_0+ \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,vj⟩xixj
由于只需要用分解后产生的 V V V 就能表达 W W W,使得参数个数由 d 2 d^2 d2 变成了 k d kd kd。另一方面, V V V 矩阵的每一列 v i v_i vi 是第 i i i 维特征的隐向量,一个隐向量包含 k k k 个描述第 i i i 维特征的因子,故称因子分解。
3.2 FM能解决参数训练问题的原因
经过因子化之后,组合特征 x i x j x_ix_j xixj 和 x j x k x_jx_k xjxk 的系数 ( v i ⋅ v j ) (v_i ⋅ v_j) (vi⋅vj) 与 ( v j ⋅ v k ) (v_j ⋅ v_k) (vj⋅vk) 不再独立,他们共有了 v j v_j vj,因此所有包含 x j x_j xj 特征的非零组合特征的样本都能拿来训练。这是什么意思呢?现在,如果只看交叉项(不管用什么loss,根据链式法则我们总需要乘上 ∂ f ( x ) ∂ w i j \frac{\partial f(x)}{\partial w_{ij}} ∂wij∂f(x):
f ( x ) ∝ ∑ i ∑ j w i j x i x j → ∂ f ( x ) ∂ w i j = x i x j f(x) \propto \sum_i \sum_j w_{ij}x_i x_j \rightarrow \frac{\partial f(x)}{\partial w_{ij}} = x_i x_j f(x)∝i∑j∑wijxixj→∂wij∂f(x)=xixj
对于稀疏数据而言, x i x j = 0 x_i x_j=0 xixj=0 很常见,梯度为0,FM改一下变成:
f ( x ) ∝ ∑ i d ∑ j = i + 1 d ( v i ⋅ v j ) x i x j → ∂ y ∂ v i = ∑ j v j ⋅ x i x j f(x) \propto \sum_i^d \sum_{j=i+1}^d (v_i · v_j)x_i x_j \rightarrow \frac{\partial y}{\partial v_{i}} = \sum_j v_j · x_i x_j f(x)∝i∑dj=i+1∑d(vi⋅vj)xixj→∂vi∂y=j∑vj⋅xixj
原本的多项式模型,为了训练 w i j w_{ij} wij,要求 x i x_i xi 和 x j x_j xj 不能同时为0,现在我们假设 x i ≠ 0 x_i \neq 0 xi̸=0,则条件变为 “ x j x_j xj 绝对不可以为0”。另一方面,同样假设 x i ≠ 0 x_i \neq 0 xi̸=0,但是对 j j j 没有限制,在所有的特征中,任意不为0的 x j x_j xj 都可以参与训练,条件减弱为 “存在 x j ≠ 0 x_j \neq 0 xj̸=0 即可”。因此,FM缓解了交叉项参数难以训练的问题。
论文 Filed-aware Factorization Machines for CTR Prediction 中,例举了两个很好的示例显示出FM与多项式模型的差别。
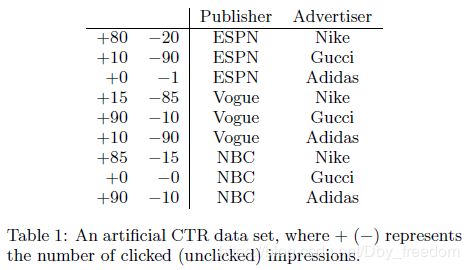
For Poly2, a very negative weight w E S P N , A d i d a s w_{ESPN,Adidas} wESPN,Adidas might be learned for this pair. For FMs, because the prediction of (ESPN, Adidas) is determined by w E S P N ⋅ w A d i d a s w_{ESPN} · w_{Adidas} wESPN⋅wAdidas, and because W E P S N W_{EPSN} WEPSN and w A d i d a s w_{Adidas} wAdidas are also learned from other pairs (e.g., (ESPN, Nike), (NBC, Adidas)), the prediction may be more accurate.
Another example is that there is no training data for the pair (NBC, Gucci). For Poly2, the prediction on this pair is trivial, but for FMs, because wNBC and wGucci can be learned from other pairs, it is still possible to do meaningful prediction.
注:这里的Ploy2的联结特征处理方式与多项式模型相同,都是需要联立特征同时非零才能得到准确训练值(而大规模稀疏条件下,同时非零对可能不存在或者很少);
总结:
而FM的提升点主要就是将 w i , j w_{i,j} wi,j 转换为 < v i , v j > <v_i, v_j> <vi,vj> 来计算,其中 v i , v j v_i, v_j vi,vj 是一个 k ∗ 1 k* 1 k∗1的矩阵,整个 V = ( v 1 , v 2 , ⋯ , v d ) V=(v_1,v_2,⋯,v_d) V=(v1,v2,⋯,vd) 是一个 k × d k \times d k×d 矩阵,即使不存在特征 i , j i, j i,j 同时非零的样本,依旧可以凭借其他包含组合项计算得到 v i , v j v_i, v_j vi,vj, 如组合项存在非零值的 < v i , v a > <v_i, v_a> <vi,va>, < v c , v j > <v_c, v_j> <vc,vj>等。这才是FM对于稀疏特征处理的最大优势所在,当然,相比于多项式模型,速度提升是第二大优势。
3.3 FM计算的复杂度
f ( x ) ∝ ∑ i d ∑ j = i + 1 d ( v i ⋅ v j ) x i x j f(x) \propto \sum_i^d \sum_{j=i+1}^d (v_i · v_j)x_i x_j f(x)∝i∑dj=i+1∑d(vi⋅vj)xixj
时间复杂度上,若只看交叉项,两层循环 O ( n 2 ) O(n^2) O(n2),内层k维内积 ( O ( k ) ) (O(k)) (O(k)),综合起来应该是 O ( k d 2 ) O(kd^2) O(kd2)。然而,交叉项是可以化简的,化简为下面的形式后,复杂度是 O ( k d ) O(kd) O(kd)。
∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ) \sum_{i=1}^n \sum_{j=i+1}^n \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j = \frac{1}{2} \sum_{f=1}^k \left(\left( \sum_{i=1}^n v_{i, f} x_i \right)^2 - \sum_{i=1}^n v_{i, f}^2 x_i^2 \right) i=1∑nj=i+1∑n⟨vi,vj⟩xixj=21f=1∑k⎝⎛(i=1∑nvi,fxi)2−i=1∑nvi,f2xi2⎠⎞
其推导过程如下:
∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j ( 1 ) = 1 2 ∑ i = 1 n ∑ j = 1 n ⟨ v i , v j ⟩ x i x j − 1 2 ∑ i = 1 n ⟨ v i , v i ⟩ x i x i ( 2 ) = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 k v i , f v j , f x i x j − ∑ i = 1 n ∑ f = 1 k v i , f v i , f x i x i ) ( 3 ) = 1 2 ∑ f = 1 k ⟮ ( ∑ i = 1 n v i , f x i ) ⋅ ( ∑ j = 1 n v j , f x j ) − ∑ i = 1 n v i , f 2 x i 2 ⟯ ( 4 ) = 1 2 ∑ f = 1 k ⟮ ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ⟯ \sum_{i=1}^{n} \sum_{j=i+1}^{n} {\langle \mathbf{v}_i, \mathbf{v}_j \rangle} x_i x_j \qquad\qquad\qquad\qquad\qquad\qquad(1)\\ = \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} {\langle \mathbf{v}_i, \mathbf{v}_j \rangle} x_i x_j - \frac{1}{2} \sum_{i=1}^{n} {\langle \mathbf{v}_i, \mathbf{v}_i \rangle} x_i x_i \qquad\qquad\;\;(2)\\ = \frac{1}{2} \left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i,f} v_{j,f} x_i x_j - \sum_{i=1}^{n} \sum_{f=1}^{k} v_{i,f} v_{i,f} x_i x_i \right) \qquad\,(3) \\ = \frac{1}{2} \sum_{f=1}^{k} {\left \lgroup \left(\sum_{i=1}^{n} v_{i,f} x_i \right) \cdot \left(\sum_{j=1}^{n} v_{j,f} x_j \right) - \sum_{i=1}^{n} v_{i,f}^2 x_i^2 \right \rgroup} \quad\;\;\,(4) \\ = \frac{1}{2} \sum_{f=1}^{k} {\left \lgroup \left(\sum_{i=1}^{n} v_{i,f} x_i \right)^2 - \sum_{i=1}^{n} v_{i,f}^2 x_i^2\right \rgroup} \qquad\qquad\qquad\;\; i=1∑nj=i+1∑n⟨vi,vj⟩xixj(1)=21i=1∑nj=1∑n⟨vi,vj⟩xixj−21i=1∑n⟨vi,vi⟩xixi(2)=21⎝⎛i=1∑nj=1∑nf=1∑kvi,fvj,fxixj−i=1∑nf=1∑kvi,fvi,fxixi⎠⎞(3)=21f=1∑k⎩⎪⎪⎪⎪⎧(i=1∑nvi,fxi)⋅(j=1∑nvj,fxj)−i=1∑nvi,f2xi2⎭⎪⎪⎪⎪⎫(4)=21f=1∑k⎩⎪⎪⎪⎪⎪⎧(i=1∑nvi,fxi)2−i=1∑nvi,f2xi2⎭⎪⎪⎪⎪⎪⎫
CSDN貌似不支持多行公式编辑,没办法,舍弃了样式,同志们将就着看。
3.4 FM的梯度下降求解
FM模型方程似乎是通用的,根据任务不同,使用不同的loss。比如,回归问题用MSE,分类问题先取sigmoid或者softmax,然后用cross-entropy,比较灵活。
f ( x ) = w 0 + ∑ i = 1 n w i ⋅ x i + 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ) f(x) = w_0 + \sum_{i=1}^{n} w_i·x_i + \frac{1}{2} \sum_{f=1}^k \left(\left( \sum_{i=1}^n v_{i, f} x_i \right)^2 - \sum_{i=1}^n v_{i, f}^2 x_i^2 \right) f(x)=w0+i=1∑nwi⋅xi+21f=1∑k⎝⎛(i=1∑nvi,fxi)2−i=1∑nvi,f2xi2⎠⎞
我们再来看一下FM的训练复杂度,利用SGD(Stochastic Gradient Descent)训练模型。模型各个参数的梯度如下:
∂ ∂ θ y ( x ) = { 1 , if θ is w 0 x i , if θ is w i x i ∑ j = 1 n v j , f x j − v i , f x i 2 , if θ is v i , f \frac{\partial}{\partial\theta} y (\mathbf{x}) = \left\{\begin{array}{ll} 1, & \text{if}\; \theta\; \text{is}\; w_0 \\ x_i, & \text{if}\; \theta\; \text{is}\; w_i \\ x_i \sum_{j=1}^n v_{j, f} x_j - v_{i, f} x_i^2, & \text{if}\; \theta\; \text{is}\; v_{i, f} \end{array}\right. ∂θ∂y(x)=⎩⎨⎧1,xi,xi∑j=1nvj,fxj−vi,fxi2,ifθisw0ifθiswiifθisvi,f
其中, v j , f v_{j, f} vj,f 是隐向量 v j v_j vj 的第 f f f 个元素。由于 ∑ j = 1 n v j , f x j \sum_{j=1}^n v_{j, f} x_j ∑j=1nvj,fxj 只与 f f f 有关,而与 i i i 无关,在每次迭代过程中,只需计算一次所有 f f f 的 ∑ j = 1 n v j , f x j \sum_{j=1}^n v_{j, f} x_j ∑j=1nvj,fxj 就能够方便地得到所有 v i , f v_{i,f} vi,f 的梯度。显然,计算所有 f f f的 ∑ j = 1 n v j , f x j \sum_{j=1}^n v_{j, f} x_j ∑j=1nvj,fxj 的复杂度是 O ( k n ) O(kn) O(kn);已知 ∑ j = 1 n v j , f x j \sum_{j=1}^n v_{j, f} x_j ∑j=1nvj,fxj 时,计算每个参数梯度的复杂度是 O ( 1 ) O(1) O(1);得到梯度后,更新每个参数的复杂度是 O ( 1 ) O(1) O(1) 模型参数一共有 n k + n + 1 nk + n + 1 nk+n+1 个。因此,FM参数训练的复杂度也是 O ( k n ) O(kn) O(kn)。综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
4. FM vs SVM
4.1 Linear kernel SVM Model
线性核:
K l ( x , z ) : = 1 + < x , z > K_l (x,z) := 1 + <x,z> Kl(x,z):=1+<x,z>
线性SVM模型等式可写为:
y ^ = w 0 + ∑ i = 1 n w i x i w 0 ∈ R , w ∈ R n \hat{y} = w_0 + \sum_{i=1}^{n}w_i x_i \quad w_0 \in R, w\in R^n y^=w0+i=1∑nwixiw0∈R,w∈Rn
线性SVM相当于 d = 1 d=1 d=1 的FM情况。
4.2 Polynomial kernel
多项式核允许SVM对变量之间高阶交叉项进行建模,被定义为:
ϕ ( x ) : = ( 1 , 2 x 1 , … , 2 x n , x 1 2 , … , x n 2 , 2 x 1 x 2 , … , 2 x 1 x n , 2 x 2 x 3 , … , 2 x n − 1 x n ) \phi (x) := (1, \sqrt{2}x_1, \dots, \sqrt{2}x_n, x_1^2, \dots, x_n^2, \\ \sqrt{2}x_1 x_2, \dots, \sqrt{2}x_1 x_n, \sqrt{2}x_2 x_3, \dots, \sqrt{2}x_{n-1} x_n) ϕ(x):=(1,2x1,…,2xn,x12,…,xn2,2x1x2,…,2x1xn,2x2x3,…,2xn−1xn)
因此多项式核的SVM可表示为:
y ^ = w 0 + 2 ∑ i = 1 n w i x i + ∑ i = 1 n w i , j ( 2 ) x i 2 + 2 ∑ i = 1 n ∑ j = i + 1 n w i , j ( 2 ) x i x j \hat{y} = w_0 + \sqrt{2}\sum_{i=1}^{n}w_i x_i + \sum_{i=1}^{n}w_{i,j}^{(2)}x_i^2 + \sqrt{2}\sum_{i=1}^{n}\sum_{j=i+1}^{n}w_{i,j}^{(2)}x_i x_j y^=w0+2i=1∑nwixi+i=1∑nwi,j(2)xi2+2i=1∑nj=i+1∑nwi,j(2)xixj
其中 w 0 ∈ R , w ∈ R n , W ( 2 ) ∈ R n × n \ w_0 \in R, w\in R^n, W^{(2)} \in R^{n\times n} w0∈R,w∈Rn,W(2)∈Rn×n (symmetric matrix)
4.3 多项式核SVM与FM的区别
多项式核SVM与FM的区别在于,多项式核SVM中的 w i , j w_{i,j} wi,j是完全独立的,如 w i , j w_{i,j} wi,j 和 w i , l w_{i,l} wi,l ,而FM的 w i j w_{ij} wij 被因子分解,因此 < v i , v j > <v_i, v_j> <vi,vj> 与 < v i , v l > <v_i, v_l> <vi,vl> 彼此依赖,因为他们重叠并且共享参数 v i v_i vi。
这也是为什么多项式核SVM为什么在高稀疏环境下不能学习到交叉项模型稀疏的原因,因为 w i j w_{ij} wij 与 w i , l w_{i,l} wi,l 彼此独立,若想进行参数 w i j w_{ij} wij 的学习,必须保证特性 i i i 项与特征 j j j 项同时不为0,这在协同过滤以及高稀疏环境下是难以保证的,更多时候两者甚至永远不能同时非零;
相比之下,FM的巧妙之处就是将 w i j w_{ij} wij 进行了因子分解,其 w i j w_{ij} wij 可以被分解为结构 < v i , v j > <v_i, v_j> <vi,vj> ,而 v i , v j v_i, v_j vi,vj 相对于 w i j w_{ij} wij 要容易训练的多,具体原因参考上文3.2 FM能解决参数训练问题的原因。
4.4 稀疏环境下的参数估计
这里作者以只有用户 user 以及 item 两个特征属性进行举例说明:
1) 线性核SVM:
y ^ = w 0 + w u + w i \hat{y} = w_0 + w_u + w_i y^=w0+wu+wi
只有 j = u j=u j=u 或者 j = i j=i j=i时, w j = 1 w_j = 1 wj=1

事实证明,线性核SVM可以在很稀疏的样本中进行训练,但是表现非常差,如上图2.
2) 多项式核SVM
对于只有两特征user与item, m ( x ) = 2 m(x) = 2 m(x)=2,则多项式核SVM如下:
y ^ = w 0 + 2 ( w u + w i ) + w u , u ( 2 ) + w i , i ( 2 ) + 2 w u , i ( 2 ) \hat{y} = w_0 + \sqrt{2}(w_u + w_i) + w_{u,u}^{(2)} + w_{i,i}^{(2)} + \sqrt{2}w_{u,i}^{(2)} y^=w0+2(wu+wi)+wu,u(2)+wi,i(2)+2wu,i(2)
其中 w u w_u wu 与 w u , u ( 2 ) w_{u,u}^{(2)} wu,u(2) 表示含义相同,可以去掉一个, w i w_i wi 与 w i , i ( 2 ) w_{i,i}^{(2)} wi,i(2)同理可去掉一个,此时只是相比线性核多了一个交叉项 w u , i ( 2 ) w_{u,i}^{(2)} wu,i(2),而若想要有效评估参数 w u , i ( 2 ) w_{u,i}^{(2)} wu,i(2),必须有足够多满足 x i ≠ 0 ∧ x j ≠ 0 x_i \neq 0 \wedge \ x_j \neq 0 xi̸=0∧ xj̸=0 的交叉项,因为一旦其中之一为0,则该对应样本就无法用于评估 w i , j ( 2 ) w_{i,j}^{(2)} wi,j(2)。
4.5 总结
-
svm 的密集参数需要同时存在的非零项对,这在稀疏样本中是难以实现的;而FM则可以在稀疏样本下很好地评估交叉项参数;(具体原因看3.2小节及4.4小节)
-
FM 可以直接以原始形式学习,而非线性SVM往往要借助对偶形式进行不等式优化求解;
-
FM独立与训练数据,而SVM则依赖部分数据(支持向量机)。
5. FM vs Other Factorization Models
FM在使用正确输入的情况下,可以拟合任何其他因子分解模型。
-
像 PARAFAC 或 MF 这样的标准分解模型不如FM这般通用,这些标准分解模型需要特征被分为 m 块,每块只有一个1,其余元素为0(one-hot编码)
-
对于单个任务设计的特性分解模型,作者证明FM通过特征提取,可以拟合任何分解模型(包括MF, PARAFAC, SVD++, PITF, FPMC),这也使得FM可以在现实中更通用。
6. 结论
FM 将 SVM 的通用性与分解模型的优点结合起来;
与SVM对比:
- FM能够在稀疏严重的情况下估计参数;
- 模型等式只依赖模型参数(SVM还需依赖部分数据——支持向量)
- 可以在原始形式下直接优化(对于SVM的对偶处理方式)
FM的拟合能力不弱于任何多项式核SVM。
与分解模型对比:
- FM是一个通用预测器,可以处理任何真实值向量;(对比分解模型往往只在特定输入数据形式下才能工作)
- 只需在输入特征向量中使用正确的指示(即某些特定组合方式),FM可以近似于任何为单任务设计的特性最新模型,这些模型包括MF, SVD++和FPMC。