大数据开发利器:Hadoop(1)
1.1 Hadoop 简介
Hadoop是Apache软件基金会旗下的一个开源分布计算平台,为用户提供底层细节透明的分布式基础架构。
Hadoop是基于JAVA语言开发的,由于JAVA语言的特性,所以具有很好的跨平台,并且可以部署在廉价的计算机集群中。
Hadoop目前有三个版本:hadoop1,Hadoop2.0和Hadoop3.0Alpha1。本文将主要介绍前两个版本的核心组件及工作流程。
1.2 Hadoop1.0和YARN
1.2.1 Hadoop1.0
1.2.1.1 Hadoop1.0的核心组件
Hadoop1.0的核心组件含有:分布式文件系统(Hadoop Distributed FileSystem,HDFS)和分布式并行编程模型(MapReduce)。
① HDFS
首先介绍一下计算机集群结构和分布式文件系统。
图1为计算机集群的基本架构。分布式文件系统把文件分布存储在多个计算机节点上,若干个计算机节点构成计算机集群。
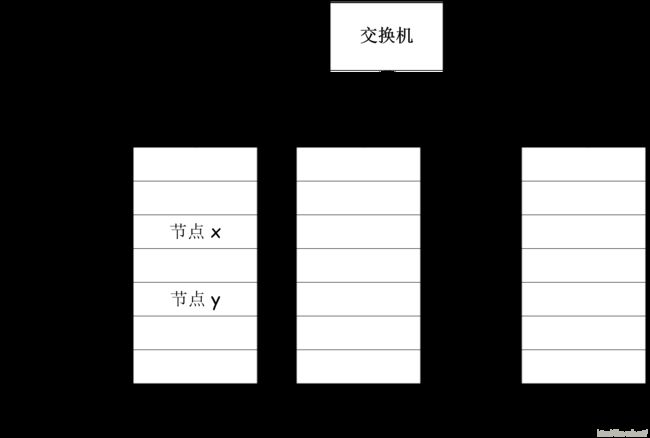
图1 计算机集群的基本架构
分布式文件系统在物理结构上是由计算机集群中的多个节点构成。这些节点分为两类,一类叫做“主节点”(Master Node)或称为NameNode,另一类叫“从节点”(Slave Node)或称为DataNode。
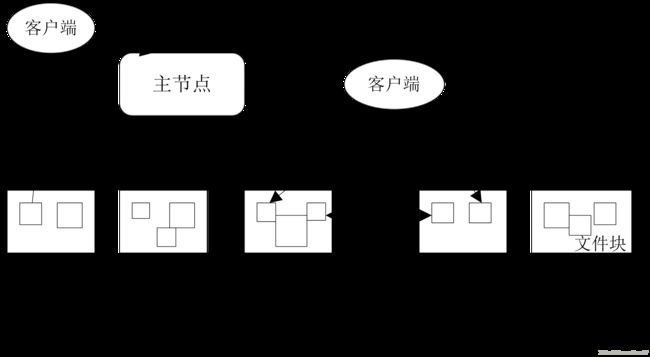
图2 文件系统的整体结构
HDFS是一个分布式文件系统,具有高容错(fault-tolerant)的特点。可以部署在廉价的通用硬件上,提供高吞吐率的数据访问,适合那些需要处理海量数据集的应用程序。
主要有以下特性:
· 支持超大数据(GB和TB级别)
· 故障检测和快速恢复(数据量大所以每一部分都很有可能出现故障)
· 流式数据访问
· 简化一致性模型(一次写入,多次读取)
因此,HDFS不适合在以下场景进行工作:
· 需要低延迟的数据访问
· 高效存储大量的小文件(增加了负载)
· 多用户写入、修改文件
HDFS类似于Linux文件系统,保存文件在DataNode上。以块为存储单位,将一个文件分成多个块。Hadoop1.0的HDFS默认一个块为64MB(Hadoop2.0为128MB)。显然,快的大小远远大于普通文件系统,可以最小化寻址开销。
由于HDFS是一种分布式文件系统。所以它存在名称节点和数据节点。功能如下图所示:

图3 HDFS主要组件的功能
由于名称节点运行期间,HDFS所有更新操作直接写入HDFS的数据结构中。长此以往,HDFS将会变得很大。在运行期间没有明显影响。但名称节点重启时候,会导致名称节点启动操作非常慢,这期间HDFS将处于安全模式(safe mode),无法提供写操作。
在这个基础上,HDFS提供了第二名称节点(SecondaryNameNode)。这部分用来保存HDFS元数据信息的备份,以减少名称节点重启的时间。
(其他的待更新)
② MapReduce
MapReduce是分布式编程的一个编程模型。可以通过集群上的一个分布式算法处理大量的数据。
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数Map和Reduce。
MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的切片(split),这些切片可以被多个Map任务并行处理。
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave Master上运行JobTracker,Slaver运行TaskTrakcer。
MapReduce体系结构主要由四个部分组成。分别是:Client、JobTracker、TaskTracer和Task。如下图所示:

图4 MapReduce体系结构
暂时介绍那么多,后面博客以实例继续。
1.2.2 Hadoop2.0
1.2.2.1 Hadoop1.0的缺陷和不足
从上面我们可以发现,Hadoop1.0主要存在以下不足:
· 抽象层次低,需要人工编码
· 需要开发者自己管理作业(job)之间的依赖关系
· 执行迭代操作效率低
· 资源浪费(Map和Reduce分两阶段执行)
· 实时性差(适合批处理,不支持实时交互式)
所以Hadoop2.0进行优化,主要体现两个方面:
· Hadoop自身核心组件MapReduce和HDFS的架构设计改进
· Hadoop生态系统其他组件的不断丰富,假如Pig、Tez、Spark等新组件

图5 Hadoop2.0的优化
表1 Hadoop框架自身的改进
| 组件 |
Hadoop1.0的问题 |
Hadoop2.0的改进 |
| HDFS |
单一名称节点,存在单点失效问题 |
设计了HDFS HA,提供名称节点热备机制 |
| HDFS |
单一命名空间,无法实现资源隔离 |
设计了HDFS Federation,管理多个命名空间 |
| MapReduce |
资源管理效率低 |
设计了新的资源管理框架YARN |
1.2.2.2 YARN(Yet AnotherResource Negotiator)
① 定义
YARN是Hadoop资源管理和调度器。它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
② 体系结构
YARN体系结构如下图所示:

图6 YARN体系结构图
它的主要组件由ResourceManager、ApplicationMaster、NodeManager和Container。
ResourceManager是一个调度器。不从事与应用程序相关的工作。它将系统中的资源分配给各个正在运行的应用程序。它不负责监控、跟踪应用的状态,也不负责重新启动应用因应用程序错误或者硬件故障而产生的失败任务。这些都由应用程序对应的Application Master完成。调度器是一个可插拔的组件。
ApplicationMaster主要负责系统中所有应用程序。包括:应用程序提交、与调度器协商资源,监控ApplicationMaster,并在失败时候重启它。
用户提交的每个应用程序都包含一个ApplicationMaster。它主要与ResourceManager协调、协商来获取资源。它将得到的作业(job)分配给内部的任务。ApplicationMaster与NodeManager通信,启动或停止任务,并监控该应用程序的运行状态,当任务运行失败时候,重新为任务申请资源,并重启任务。
NodeManager是任务、资源管理器。它会定时想ResourceManager汇报本节点上资源使用情况和各个Container(动态资源单位)运行状态。它接收并处理来自Application Master的Container启动、停止等请求。
Container资源抽象,封装了某个节点(可理解为NodeManager)的多维度资源,封装了内存、CPU、磁盘、网络等。当NodeManager向ResourceManager申请资源时候,ResourceManager返回的资源是一个Container。得到资源的任务只能使用Congtainer中描述的资源,它是个动态划分的单位,是根据应用需求动态生成的。
③ 工作流程
那么,各个组件如何配合工作呢?工作流程图如下图所示:

图7 工作流程图
分为以下四个步骤:
· 用户向YARN中提交应用程序,包括ApplicationManager程序,启动ApplicationManager的命令或用户程序等。
· REcourceManager会为应用程序分配一个Container,并与Node Manager通信,要求它在Container中启动应用程序的Application Manager。
· Application Manager一旦生成,它首先会向Resource Manager注册,这样,用户可以直接通过Resource Manager查看应用程序的运行状态。然后它将会向各个任务申请资源并监控任务的运行状态直到运行结束。它会以轮询的方式通过RPC协议向Resource Manager申请和领取资源,一旦Application Manager申请到资源后,会与Node Manager通信,要求它启动任务。
· Node Manager为任务设置好运行环境(一些环境变量,架包、二进制程序),将任务启动命令写在脚本中,并通过运行该脚本启动任务。各个任务通过RPC协议向Application Manager汇报自己的运行状态和进度。一旦任务失败,Application Manager将会重新申请资源,重启该任务。
应用程序运行完成之后,Application Manager将会向Recourse Manager注销并关闭自己。用户在任务运行过程中可以用RPC查询任务当前的运行状态。
1.3 总结
本博文用于记录Hadoop2.0学习过程。本节主要介绍了Hadoop1.0和Hadoop2.0的核心组件和工作流程。接下来一周更新VM安装Centos和Centos伪分布式安装Hadoop2.0。
1.4 参考资料
百度百科、维基百科(Hadoop、HDFS、MapReduce)、Hadoop文档、林子雨编著《大数据技术原理与应用——概念、存储、处理、分析与应用》 课件、网易云课堂大数据微专业课件
编辑时间:2016年10月9日