【Python数据挖掘课程】三.Kmeans聚类代码实现、作业及优化
前文推荐:
【Python数据挖掘课程】一.安装Python及爬虫入门介绍
【Python数据挖掘课程】二.Kmeans聚类数据分析及Anaconda介绍
希望这篇文章对你有所帮助,尤其是刚刚接触数据挖掘以及大数据的同学,同时准备尝试以案例为主的方式进行讲解。如果文章中存在不足或错误的地方,还请海涵~
一. 案例实现
这里不再赘述,详见第二篇文章,直接上代码,这是我的学生完成的作业。
数据集:
下载地址:KEEL-dataset - Basketball data set
篮球运动员数据,每分钟助攻和每分钟得分数。通过该数据集判断一个篮球运动员属于什么位置(控位、分位、中锋等)。完整数据集包括5个特征,每分钟助攻数、运动员身高、运动员出场时间、运动员年龄和每分钟得分数。
assists_per_minute height time_played age points_per_minute
0 0.0888 201 36.02 28 0.5885
1 0.1399 198 39.32 30 0.8291
2 0.0747 198 38.80 26 0.4974
3 0.0983 191 40.71 30 0.5772
4 0.1276 196 38.40 28 0.5703
5 0.1671 201 34.10 31 0.5835
6 0.1906 193 36.20 30 0.5276
7 0.1061 191 36.75 27 0.5523
8 0.2446 185 38.43 29 0.4007
9 0.1670 203 33.54 24 0.4770
10 0.2485 188 35.01 27 0.4313
11 0.1227 198 36.67 29 0.4909
12 0.1240 185 33.88 24 0.5668
13 0.1461 191 35.59 30 0.5113
14 0.2315 191 38.01 28 0.3788
15 0.0494 193 32.38 32 0.5590
16 0.1107 196 35.22 25 0.4799
17 0.2521 183 31.73 29 0.5735
18 0.1007 193 28.81 34 0.6318
19 0.1067 196 35.60 23 0.4326
20 0.1956 188 35.28 32 0.4280 # -*- coding: utf-8 -*-
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
X = [[0.0888, 0.5885],
[0.1399, 0.8291],
[0.0747, 0.4974],
[0.0983, 0.5772],
[0.1276, 0.5703],
[0.1671, 0.5835],
[0.1906, 0.5276],
[0.1061, 0.5523],
[0.2446, 0.4007],
[0.1670, 0.4770],
[0.2485, 0.4313],
[0.1227, 0.4909],
[0.1240, 0.5668],
[0.1461, 0.5113],
[0.2315, 0.3788],
[0.0494, 0.5590],
[0.1107, 0.4799],
[0.2521, 0.5735],
[0.1007, 0.6318],
[0.1067, 0.4326],
[0.1956, 0.4280]
]
print X
# Kmeans聚类
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
import numpy as np
import matplotlib.pyplot as plt
x = [n[0] for n in X]
print x
y = [n[1] for n in X]
print y
# 可视化操作
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans-Basketball Data")
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
plt.legend(["Rank"])
plt.show()
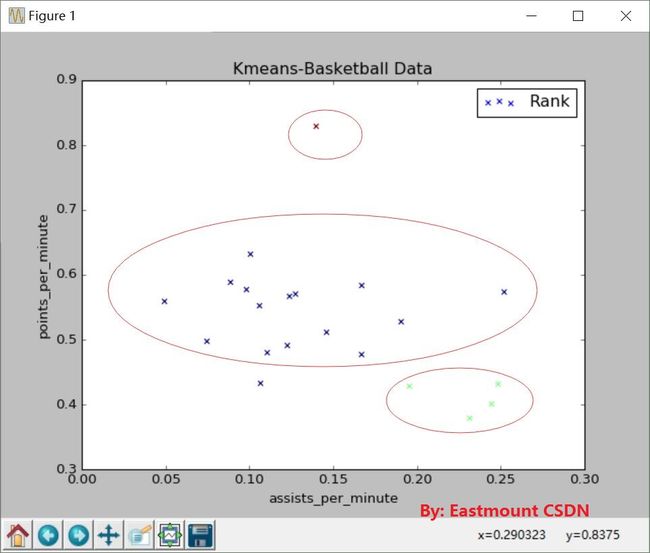
运行结果:
从图中可以看到聚集成三类,红色比较厉害,得分很高;中间蓝色是一类,普通球员;右小角绿色是一类,助攻高得分低,是控位。
代码分析:
from sklearn.cluster import KMeansX = [[164,62],[156,50],...]clf = KMeans(n_clusters=3)y_pred =clf.fit_predict(X)print(y_pred)import matplotlib.pyplot as pltx = [n[0] for n in X]
y = [n[1] for n in X]获取第2列的值,使用for循环获取 ,n[1]表示X第2列。
plt.scatter(x, y, c=y_pred, marker='o')plt.title("Kmeans-Basketball Data")plt.xlabel("assists_per_minute")plt.ylabel("points_per_minute")plt.legend(["Rank"])plt.show()二. 学生图例
下面简单展示学生做的作业及分析,感觉还是不错,毕竟才上几节课而且第一次作业,希望后面的作业更加精彩吧。因为学生的专业分布不同,所以尽量让学生设计他们专业的内容。
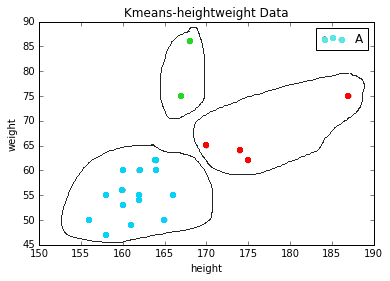
eg 遗传学身高体重数据
第一列表示孩子的身高,单位cm;第二列表示孩子的体重,单位kg。从上图可以看出,数据集被分为了三类。绿色为一类、蓝色为一类,红色为一类。

eg 微博数据集
第一列代表微博中某条信息的转发量,第二列代表微博中某条信息的评论数。从上图可以看出,总共分为3类,共三种颜色,绿色一层说明该信息转发量与评论数都很高。

eg 上市公司财务报表
第一列表示公司利润率;第二列表示公司资产规模。从上图可以看出,总共分为4类,共四种颜色。暗红色为资产规模最大,依次至蓝色资产规模减小。

eg 世界各国家人均面积与土地面积
第一列表示各国家的人均面积(人/ 平方公里);第二列表示各国家的土地面积(万平方公里)。从上图可以看出,总共分为3类,共三种颜色。红色表示的国家相对来说最拥挤,可能是孟加拉这样土地面积少且人口众多的国家;蓝色就是地广人稀的代表,比如俄罗斯、美国、、墨西哥、巴西;绿色表示人口密度分布比较平均的国家。

eg employee salaries数据集
第一列表示员工工资;第二列表示员工年龄数。从上图可以看出,总共分为5类,共5种颜色。总体呈现正相关性,年龄越大,工资越高;除个别外,总体正线性关系。

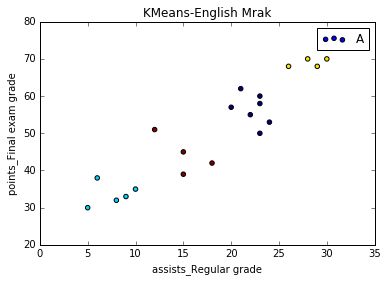
eg 学生英语成绩数据集
第一列表示学生英语平时成绩;第二列表示学生英语期末成绩。从上图可以看出,总共分为4类,共四种颜色。黄色一层,平时成绩和末考成绩都很高,属于“学霸”级别的人物;其次,蓝色一层和红色一层;最后,天蓝色一层,暂且称之为“学渣”。
三. Matplotlib绘图优化
Matplotlib代码的优化:
1.第一部分代码是定义X数组,实际中是读取文件进行的,如何实现读取文件中数据再转换为矩阵进行聚类呢?
2.第二部分是绘制图形,希望绘制不同的颜色及类型,使用legend()绘制图标。
假设存在数据集如下图所示:data.txt
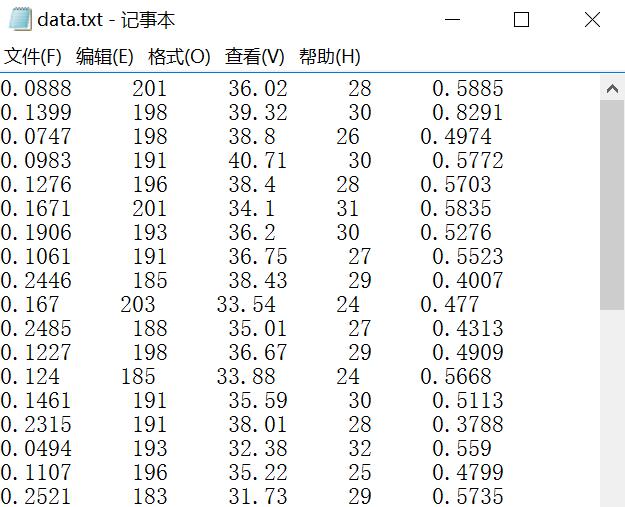
数据集包括96个运动员的数据,源自:KEEL-dataset - Basketball data set
现需要获取第一列每分钟助攻数、第五列每分钟得分数存于矩阵中。
0.0888 201 36.02 28 0.5885
0.1399 198 39.32 30 0.8291
0.0747 198 38.8 26 0.4974
0.0983 191 40.71 30 0.5772
0.1276 196 38.4 28 0.5703
0.1671 201 34.1 31 0.5835
0.1906 193 36.2 30 0.5276
0.1061 191 36.75 27 0.5523
0.2446 185 38.43 29 0.4007
0.167 203 33.54 24 0.477
0.2485 188 35.01 27 0.4313
0.1227 198 36.67 29 0.4909
0.124 185 33.88 24 0.5668
0.1461 191 35.59 30 0.5113
0.2315 191 38.01 28 0.3788
0.0494 193 32.38 32 0.559
0.1107 196 35.22 25 0.4799
0.2521 183 31.73 29 0.5735
0.1007 193 28.81 34 0.6318
0.1067 196 35.6 23 0.4326
0.1956 188 35.28 32 0.428
0.1828 191 29.54 28 0.4401
0.1627 196 31.35 28 0.5581
0.1403 198 33.5 23 0.4866
0.1563 193 34.56 32 0.5267
0.2681 183 39.53 27 0.5439
0.1236 196 26.7 34 0.4419
0.13 188 30.77 26 0.3998
0.0896 198 25.67 30 0.4325
0.2071 178 36.22 30 0.4086
0.2244 185 36.55 23 0.4624
0.3437 185 34.91 31 0.4325
0.1058 191 28.35 28 0.4903
0.2326 185 33.53 27 0.4802
0.1577 193 31.07 25 0.4345
0.2327 185 36.52 32 0.4819
0.1256 196 27.87 29 0.6244
0.107 198 24.31 34 0.3991
0.1343 193 31.26 28 0.4414
0.0586 196 22.18 23 0.4013
0.2383 185 35.25 26 0.3801
0.1006 198 22.87 30 0.3498
0.2164 193 24.49 32 0.3185
0.1485 198 23.57 27 0.3097
0.227 191 31.72 27 0.4319
0.1649 188 27.9 25 0.3799
0.1188 191 22.74 24 0.4091
0.194 193 20.62 27 0.3588
0.2495 185 30.46 25 0.4727
0.2378 185 32.38 27 0.3212
0.1592 191 25.75 31 0.3418
0.2069 170 33.84 30 0.4285
0.2084 185 27.83 25 0.3917
0.0877 193 21.67 26 0.5769
0.101 193 21.79 24 0.4773
0.0942 201 20.17 26 0.4512
0.055 193 29.07 31 0.3096
0.1071 196 24.28 24 0.3089
0.0728 193 19.24 27 0.4573
0.2771 180 27.07 28 0.3214
0.0528 196 18.95 22 0.5437
0.213 188 21.59 30 0.4121
0.1356 193 13.27 31 0.2185
0.1043 196 16.3 23 0.3313
0.113 191 23.01 25 0.3302
0.1477 196 20.31 31 0.4677
0.1317 188 17.46 33 0.2406
0.2187 191 21.95 28 0.3007
0.2127 188 14.57 37 0.2471
0.2547 160 34.55 28 0.2894
0.1591 191 22.0 24 0.3682
0.0898 196 13.37 34 0.389
0.2146 188 20.51 24 0.512
0.1871 183 19.78 28 0.4449
0.1528 191 16.36 33 0.4035
0.156 191 16.03 23 0.2683
0.2348 188 24.27 26 0.2719
0.1623 180 18.49 28 0.3408
0.1239 180 17.76 26 0.4393
0.2178 185 13.31 25 0.3004
0.1608 185 17.41 26 0.3503
0.0805 193 13.67 25 0.4388
0.1776 193 17.46 27 0.2578
0.1668 185 14.38 35 0.2989
0.1072 188 12.12 31 0.4455
0.1821 185 12.63 25 0.3087
0.188 180 12.24 30 0.3678
0.1167 196 12.0 24 0.3667
0.2617 185 24.46 27 0.3189
0.1994 188 20.06 27 0.4187
0.1706 170 17.0 25 0.5059
0.1554 183 11.58 24 0.3195
0.2282 185 10.08 24 0.2381
0.1778 185 18.56 23 0.2802
0.1863 185 11.81 23 0.381
0.1014 193 13.81 32 0.1593# -*- coding: utf-8 -*-
"""
By: Eastmount CSDN 2016-10-12
该部分讲数据集读取,然后赋值给X变量
读取文件data.txt 保存结果为X
"""
import os
data = []
for line in open("data.txt", "r").readlines():
line = line.rstrip() #删除换行
#删除多余空格,保存一个空格连接
result = ' '.join(line.split())
#获取每行五个值 '0 0.0888 201 36.02 28 0.5885' 注意:字符串转换为浮点型数
s = [float(x) for x in result.strip().split(' ')]
#输出结果:['0', '0.0888', '201', '36.02', '28', '0.5885']
print s
#数据存储至data
data.append(s)
#输出完整数据集
print u'完整数据集'
print data
print type(data)
'''
现在输出数据集:
['0 0.0888 201 36.02 28 0.5885',
'1 0.1399 198 39.32 30 0.8291',
'2 0.0747 198 38.80 26 0.4974',
'3 0.0983 191 40.71 30 0.5772',
'4 0.1276 196 38.40 28 0.5703'
]
'''
print u'第一列 第五列数据'
L2 = [n[0] for n in data]
print L2
L5 = [n[4] for n in data]
print L5
'''
X表示二维矩阵数据,篮球运动员比赛数据
总共96行,每行获取两列数据
第一列表示球员每分钟助攻数:assists_per_minute
第五列表示球员每分钟得分数:points_per_minute
'''
#两列数据生成二维数据
print u'两列数据合并成二维矩阵'
T = dict(zip(L2,L5))
type(T)
#dict类型转换为list
print u'List'
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
print X
print type(X)
"""
KMeans聚类
clf = KMeans(n_clusters=3) 表示类簇数为3,聚成3类数据,clf即赋值为KMeans
y_pred = clf.fit_predict(X) 载入数据集X,并且将聚类的结果赋值给y_pred
"""
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
#输出聚类预测结果,96行数据,每个y_pred对应X一行或一个球员,聚成3类,类标为0、1、2
print(y_pred)
"""
可视化绘图
Python导入Matplotlib包,专门用于绘图
import matplotlib.pyplot as plt 此处as相当于重命名,plt用于显示图像
"""
import numpy as np
import matplotlib.pyplot as plt
#获取第一列和第二列数据 使用for循环获取 n[0]表示X第一列
x = [n[0] for n in X]
print x
y = [n[1] for n in X]
print y
#绘制散点图 参数:x横轴 y纵轴 c=y_pred聚类预测结果 marker类型 o表示圆点 *表示星型 x表示点
#plt.scatter(x, y, c=y_pred, marker='x')
#坐标
x1 = []
y1 = []
x2 = []
y2 = []
x3 = []
y3 = []
#分布获取类标为0、1、2的数据 赋值给(x1,y1) (x2,y2) (x3,y3)
i = 0
while i < len(X):
if y_pred[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_pred[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_pred[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
#四种颜色 红 绿 蓝 黑
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
#绘制标题
plt.title("Kmeans-Basketball Data")
#绘制x轴和y轴坐标
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
#设置右上角图例
plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10)
plt.show() 
可视化部分强烈推荐资料:
数字的可视化:python画图之散点图sactter函数详解 - hefei_cyp
python 科学计算(一) - bovine
Matplotlib scatter plot with legend - stackoverflow
Python数据可视化——散点图 Rachel-Zhang(按评论修改代码)
关于Matlab作图的若干问题 - 张朋飞
四. Spyder常见问题
下面是常见遇到的几个问题:
1.Spyder软件如果Editor编辑框不在,如何调出来。
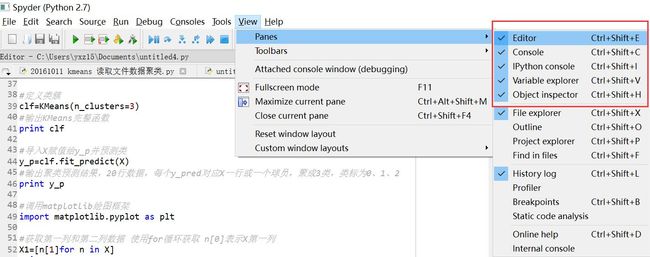
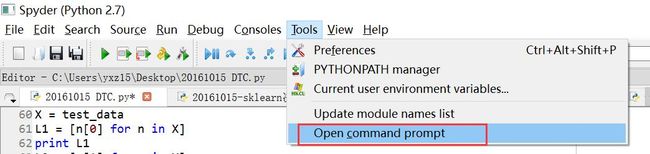
2.会缺少一些第三方包,如lda,如何导入。使用cd ..去到C盘根目录,cd去到Anaconda的Scripts目录下,输入"pip install selenium"安装selenium相应的包,"pip install lda"安装lda包。


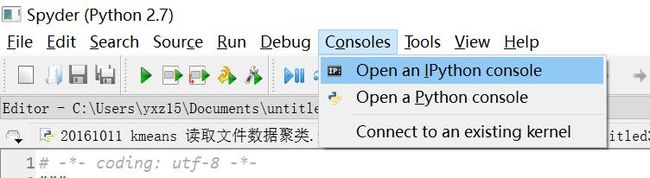
3.运行时报错,缺少Console,点击如下。
4.如果Spyder安装点击没有反应,重新安装也没有反应,建议在运行下试试。

实在不行卸载再重装:pip uninstall spyder
pip install spyder

5.Spyder如何显示绘制Matplotlib中文。
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="C:\Windows\Fonts/msyh.ttf", size=10)
#绘制标题 fontproperties表示字体类型,用于显示中文字符,下同
plt.title(u'世界各国家人均面积与土地面积',fontproperties=font)
#绘制x轴和y轴坐标
plt.ylabel(u'人均面积(人/ 平方公里)',fontproperties=font)
plt.xlabel(u'面积(万平方公里)',fontproperties=font)
(By:Eastmount 2016-10-12 深夜3点半 http://blog.csdn.net/eastmount/ )