使用WebCollector爬虫框架进行微信公众号文章爬取并持久化
〇、Java爬虫框架有哪些?
1.nutch:Apache下开源爬虫项目,适合做搜索引擎,分布式爬虫只是其中一个功能,功能丰富,文档完整。
2.heritrix:比较成熟,用的人较多,有自己的web管理控制台,包含了一个HTTP服务器。
3.crowler4j:只具有爬虫的核心功能,上手简单。
4.webmagic:一个可伸缩的爬虫框架,涵盖爬虫整个生命周期:下载、URL管理、内容提取和持久化。
5.gecco:轻量集网络爬虫,整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架。
6.webcollector:一个无需配置、便于二次开发的爬虫框架,参考了crawler4j。
4、5、6皆为国人所写。
一、网络爬虫基本概念
基本的网络爬虫框架如图所示:
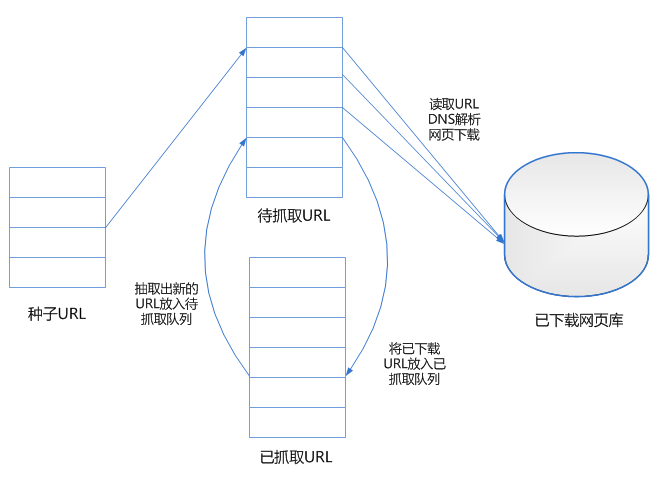
基本的网络爬虫工作流程如下:
1.精心挑选一部分种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出URL,解析DNS得到主机ip地址,将网页内容下载下来,解析有用的内容存储到库中,将这些URL放入已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中包含的其他URL,抽取新的URL放入待抓取队列,重复循环。
基本的抓取策略:
1.深度优先遍历策略:一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
2.宽度优先遍历策略:将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
二、WebCollector框架介绍
作为我的第一款入门爬虫框架,先不论其好坏,重点是需要借助该框架理解爬虫的原理、流程和关键技术,故下面进行详细梳理。
WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
其内核架构如图所示:
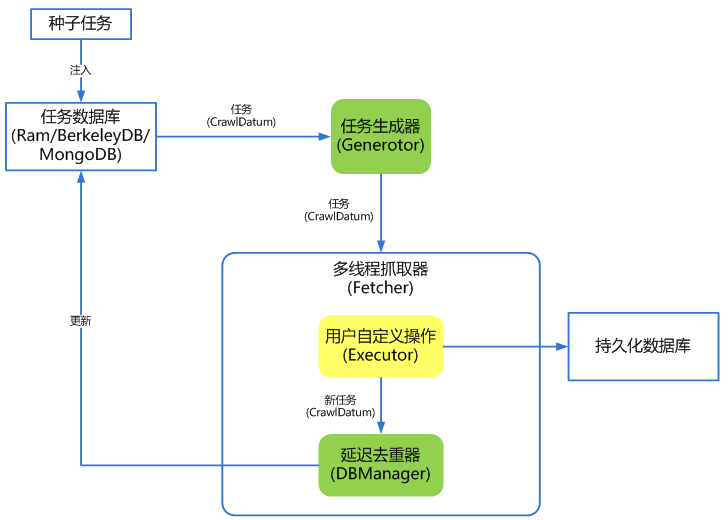
WebCollector 2.X版本特性
1.自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX。
2.可以为每个URL设置附加信息(MetaData),利用附加信息可以完成深度获取、锚文本获取、引用页面获取、POST参数传递、增量更新等。
3.使用插件机制,用户可定制自己的Http请求、过滤器、执行器等插件。
4.内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
5.内置一套基于Berkeley DB的插件(BreadthCrawler),适合处理长期和大量级的任务,具有断点爬取功能。
6.集成selenium,可以对JavaScript生成信息进行抽取。
7.可轻松自定义http请求,并内置多代理随机切换功能,可通过定义http请求实现模拟登录。
8.使用slf4j作为日志门面,可对接多种日志。
9.使用类似Hadoop的Configuration机制,可为每个爬虫定制配置信息。
WebCollector与HttpClient、Jsoup的区别
WebCollector是爬虫框架,HttpClient是Http请求组件,JSoup是网页解析器,在自己手动编写爬虫时需要调用HttpClient和JSoup进行数据采集。而框架的好处是将底层公共的实现包装好,WebCollector框架自带多线程和URL维护,在编写爬虫时无需考虑线程池、URL去重和断电爬取的问题。
WebCollector的遍历
采用一种粗略的广度遍历,网络爬虫在访问页面时,从页面中探索新的URL,继续爬取。WebCollector为探索新的URL提供了两种机制,自动解析和手动解析。
三、功能实现
整体功能可以拆分为两部分,一是通过搜狗微信搜索接口获取微信公众号文章内容,二是将解析出来的内容持久化到MySQL数据库。
1.爬取微信公众号
通过搜狗微信搜索可以得到微信公众号的网页入口,在这里可以搜索公众号的任何信息,相当于搜狗也是一个爬虫爬取微信的数据并显示出来。这样获取到的文章URL是一个带时间戳的临时链接,也就是说该链接一段时间后就会失效无法访问,因此不能存储该链接,如图所示。(这里有一个问题,经常会出现“请输入验证码”页面,还没有解决。)
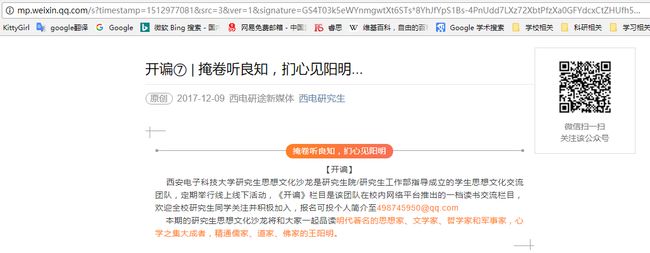
在visit()函数里处理三种页面:公众号搜索页面、公众号文章列表页和文章详情页。相关代码如下,讲解参见注释,这里主要是参考这篇文章,改用Alibaba的fastjson解析JSON数据,并修改了原文中的一些小bug。
/**
* 自定义的WxAccountCrawler继承框架中的BreathCrawler插件,实现功能自定制
*/
public class WxAccountCrawler extends BreadthCrawler {
public static final Logger LOG = LoggerFactory.getLogger(WxAccountCrawler.class);
protected String historyKeysPath;//历史值存放路径,一个txt文件
protected BufferedWriter historyKeysWriter;
//类的构造函数
public WxAccountCrawler(String crawlPath, String historyKeysPath) throws Exception {
//自动解析为false,也就是手动解析探索新的URL
super(crawlPath, false);
this.historyKeysPath = historyKeysPath;
LOG.info("initializing history-keys-filter ......");
//设置URL过滤器
this.setNextFilter(new HistoryKeysFilter(historyKeysPath));
LOG.info("creating history-keys-writer");
//历史值文件写入
historyKeysWriter = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(historyKeysPath, true), "utf-8"));
}
@Override
public void visit(Page page, CrawlDatums next) {
String account = page.meta("account");
if (page.matchType("account_search")) {
//对于账号搜索页面,手动解析,抽取公众号文章列表页URL
Element accountLinkEle = page.select("p.tit>a").first();
//防止搜索结果为空
if (accountLinkEle == null) {
LOG.info("公众号\"" + account + "\"不存在,请给出准确的公众号名");
return;
}
//防止公众号名错误
String detectedAccount = accountLinkEle.text().trim();
if (!account.equals(detectedAccount)) {
LOG.info("公众号\"" + account + "\"与搜索结果\"" + detectedAccount + "\"名称不符,请给出准确的公众号名");
return;
}
//解析出公众号搜索结果页面中的URL
String accountUrl = accountLinkEle.attr("abs:href");
//添加到待抓取URL队列中
next.add(new CrawlDatum(accountUrl, "article_list").meta("account", account));
} else if (page.matchType("article_list")) {
//对于公众号文章列表页,只显示最近的10篇文章
String prefix = "msgList = ";
String suffix = "seajs.use";
int startIndex = page.html().indexOf(prefix) + prefix.length();
int endIndex = page.html().indexOf(suffix);
//trim()函数去除首尾空格
String jsonStr = page.html().substring(startIndex, endIndex).trim();
int len = jsonStr.length();
//去掉最后一个分号,否则无法解析为jsonobject
jsonStr = jsonStr.substring(0,len-1);
//System.out.println(jsonStr);
//将字符串转换为jsonobject
JSONObject json = JSONObject.parseObject(jsonStr);
JSONArray articleJSONArray = JSONArray.parseArray(json.getString("list"));
for (int i = 0; i < articleJSONArray.size(); i++) {
JSONObject articleJSON = articleJSONArray.getJSONObject(i).getJSONObject("app_msg_ext_info");
String title = articleJSON.getString("title").trim();
String key = account + "_" + title;
//原来问题在这里!!!replace("&", "&")
//这里是文章的临时链接
String articleUrl = "http://mp.weixin.qq.com" + articleJSON.getString("content_url").replace("&", "&");
//添加到待抓取URL队列中
next.add(new CrawlDatum(articleUrl, "article").key(key).meta("account", account));
}
} else if (page.matchType("article")) {
try {
//对于文章详情页,抽取标题、内容等信息
String title = page.select("h2.rich_media_title").first().text().trim();
//String date = page.select("em#post-date").first().text().trim();
String content = page.select("div.rich_media_content").first().text().trim();
//适应数据库中content大小
content = content.substring(0,255);
//将页面key写入文件中用来去重
writeHistoryKey(page.key());
//持久化到数据库
writeNewstoDB(title,content);
//JSONObject articleJSON = new JSONObject();
//articleJSON.fluentPut("account", account)
// .fluentPut("title", title)
// .fluentPut("content", content);
//System.out.println(articleJSON);
} catch (Exception ex) {
LOG.info("writer exception", ex);
}
}
}
@Override
public void start(int depth) throws Exception {
super.start(depth);
//关闭文件,保存history keys
historyKeysWriter.close();
LOG.info("save history keys");
}
public void addAccount(String account) throws UnsupportedEncodingException {
//根据公众号名称设置种子URL
String seedUrl = "http://weixin.sogou.com/weixin?type=1&"
+ "s_from=input&ie=utf8&query=" + URLEncoder.encode(account, "utf-8");
CrawlDatum seed = new CrawlDatum(seedUrl, "account_search").meta("account", account);
addSeed(seed);
}
public class HistoryKeysFilter extends HashSetNextFilter {
//读取历史文章标题,用于去重
public HistoryKeysFilter(String historyKeysPath) throws Exception {
File historyFile = new File(historyKeysPath);
if (historyFile.exists()) {
FileInputStream fis = new FileInputStream(historyKeysPath);
BufferedReader reader = new BufferedReader(new InputStreamReader(fis, "utf-8"));
String line;
while ((line = reader.readLine()) != null) {
this.add(line);
}
reader.close();
}
}
}
public static void main(String[] args) throws Exception {//主函数
WxAccountCrawler crawler = new WxAccountCrawler("crawl_weixin", "wx_history.txt");
crawler.addAccount("西电研究生");
crawler.setThreads(5);
crawler.start(10);
}
}
2.持久化数据到MySQL
这里遇到的问题详见上一篇文章。按照这篇文章的思路创建一个JDBCHelper类,在爬虫程序visit()中的writeNewstoDB中调用JDBCHelper的getJdbcTemplate方法来获取一个JdbcTemplate。相关代码如下。
public class JDBCHelper {
public static HashMap templateMap
= new HashMap();
public static JdbcTemplate createMysqlTemplate(String templateName,
String url, String username, String password,
int initialSize) {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setInitialSize(initialSize);
JdbcTemplate template = new JdbcTemplate(dataSource);
templateMap.put(templateName, template);
return template;
}
public static JdbcTemplate getJdbcTemplate(String templateName){
return templateMap.get(templateName);
}
} public synchronized void writeNewstoDB(String title, String content) throws Exception {
JdbcTemplate jdbcTemplate = null;
try {
jdbcTemplate = JDBCHelper.createMysqlTemplate("mysql1",
"jdbc:mysql://localhost:3306/toutiao?useUnicode=true&characterEncoding=utf8&useSSL=false",
"username", "password", 5);
//如果数据库中没有相关的表这里需要添加建表操作
} catch (Exception ex) {
jdbcTemplate = null;
System.out.println("mysql未开启或JDBCHelper.createMysqlTemplate中参数配置不正确!");
}
if (jdbcTemplate != null) {
int updates=jdbcTemplate.update("insert into news"
+" (title, link, image, like_count, comment_count, created_date, user_id) value(?,?,?,?,?,?,?)",
title, content, "http://images.nowcoder.com/head/23m.png", 0, 0, new Date(), 3);
if(updates==1){
System.out.println("mysql插入成功");
}
}
}四、项目地址
本文中参考的WebCollector项目源代码和示例程序见本文第一部分。
本文完整Maven项目地址:https://github.com/IrisChenXiaoyan/weChatCrawler,欢迎star&fork
参考文献:
https://www.zhihu.com/question/31427895
http://www.cnblogs.com/wawlian/archive/2012/06/18/2553061.html
https://oschina.net/p/webcollector
http://www.jianshu.com/p/7e310e848480