Kafka 安装部署及使用(单节点/集群)
导读:
本篇博客,笔者会介绍三种安装Kafka的方式,分别为:单节点单Broker部署、单节点多Broker部署、集群部署(多节点多Broker)。实际生产环境中使用的是第三种方式,以集群的方式来部署Kafka。
Kafka强依赖ZK,如果想要使用Kafka,就必须安装ZK,Kafka中的消费偏置信息、kafka集群、topic信息会被存储在ZK中。有人可能会说我在使用Kafka的时候就没有安装ZK,那是因为Kafka内置了一个ZK,一般我们不使用它。
一、Kafka 单节点部署
Kafka中单节点部署又分为两种,一种为单节点单Broker部署,一种为单节点多Broker部署。因为是单节点的Kafka,所以在安装ZK时也只需要单节点即可。
ZooKeeper官网:http://zookeeper.apache.org/
下载Zookeeper并解压到指定目录
$ wget http://www-eu.apache.org/dist/zookeeper/zookeeper-3.5.1-alpha/zookeeper-3.5.1-alpha.tar.gz
$ tar -zxvf zookeeper-3.5.1-alpha.tar.gz -c /opt/zookeeper进入Zookeeper的config目录下
$ cd /opt/zookeeper/conf拷贝zoo_sample.cfg文件重命名为zoo.cfg,然后修改dataDir属性
# 数据的存放目录
dataDir=/home/hadoop/zkdata
# 端口,默认就是2181
clientPort=2181配置环境变量
# Zookeeper Environment Variable
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/binZookeeper 启动停止命令
$ zkServer.sh start
$ zkServer.sh stop笔者在安装完Zookeeper后,输入命令启动后,jps中并没有查看到QuorumPeerMain进程,说明没有启动成功,进入Zookeeper的log目录下查看日志,发现报了一个错误,如下
AdminServer$AdminServerException: Problem starting AdminServer on address 0.0.0.0, port 8080 and command URL /commands
原因:zookeeper的管理员端口被占用
解决:笔者使用的zookeeper的版本为3.5.1,该版本中有个内嵌的管理控制台是通过jetty启动,会占用8080 端口,需要修改配置里的“admin.serverPort=8080”,默认8080没有写出来,只要改为一个没使用的端口即可,例如:admin.serverPort=8181
1.Kafka 单节点单Broker部署及使用
部署架构
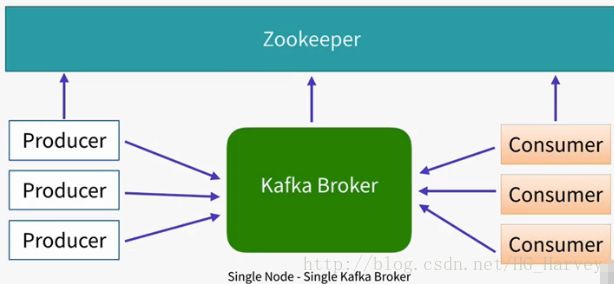
配置Kafka
参考官网:http://kafka.apache.org/quickstart
进入kafka的config目录下,有一个server.properties,添加如下配置
# broker的全局唯一编号,不能重复
broker.id=0
# 监听
listeners=PLAINTEXT://:9092
# 日志目录
log.dirs=/home/hadoop/kafka-logs
# 配置zookeeper的连接(如果不是本机,需要该为ip或主机名)
zookeeper.connect=localhost:2181启动Zookeeper
[hadoop@Master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED启动Kafka
$ kafka-server-start.sh $KAFKA_HOME/config/server.properties打印的日志信息没有报错,可以看到如下信息
[Kafka Server 0], started (kafka.server.KafkaServer)但是并不能保证Kafka已经启动成功,输入jps查看进程,如果可以看到Kafka进程,表示启动成功
[hadoop@Master ~]$ jps
9173 Kafka
9462 Jps
8589 QuorumPeerMain
[hadoop@Master ~]$ jps -m
9472 Jps -m
9173 Kafka /opt/kafka/config/server.properties
8589 QuorumPeerMain /opt/zookeeper/bin/../conf/zoo.cfg创建topic
[hadoop@Master ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test参数说明:
–zookeeper:指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
–replication-factor:指定副本数量
–partitions:指定分区数量
–topic:主题名称
查看所有的topic信息
[hadoop@Master ~]$ kafka-topics.sh --list --zookeeper localhost:2181
test启动生产者
[hadoop@Master ~]$ kafka-console-producer.sh --broker-list localhost:9092 --topic test启动消费者
[hadoop@Master ~]$ kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning测试
- 生产者生产数据

- 消费者消费数据

我们在启动一个消费者,去掉后面的参数–from-beginning,看有什么区别
- 生产者消费数据

- 消费者1消费数据(含有–from-beginning参数)

- 消费者2消费数据(没有–from-beginning参数)

总结:–from-beginning参数如果有表示从最开始消费数据,旧的和新的数据都会被消费,而没有该参数表示只会消费新产生的数据
2.Kafka 单节点多Broker部署及使用
部署架构

配置Kafka
参考官网:http://kafka.apache.org/quickstart
拷贝server.properties三份
[hadoop@Master ~]$ cd /opt/kafka/config
[hadoop@Master config]$ cp server.properties server-1.properties
[hadoop@Master config]$ cp server.properties server-2.properties
[hadoop@Master config]$ cp server.properties server-3.properties 修改server-1.properties文件
# broker的全局唯一编号,不能重复
broker.id=1
# 监听
listeners=PLAINTEXT://:9093
# 日志目录
log.dirs=/home/hadoop/kafka-logs-1修改server-2.properties文件
# broker的全局唯一编号,不能重复
broker.id=2
# 监听
listeners=PLAINTEXT://:9094
# 日志目录
log.dirs=/home/hadoop/kafka-logs-2修改server-3.properties文件
# broker的全局唯一编号,不能重复
broker.id=3
# 监听
listeners=PLAINTEXT://:9094
# 日志目录
log.dirs=/home/hadoop/kafka-logs-3启动Zookeeper
[hadoop@Master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED启动Kafka(分别启动server1、2、3)
$ kafka-server-start.sh $KAFKA_HOME/config/server-1.properties
$ kafka-server-start.sh $KAFKA_HOME/config/server-2.properties
$ kafka-server-start.sh $KAFKA_HOME/config/server-3.properties查看进程
[hadoop@Master ~]$ jps
11905 Kafka
11619 Kafka
8589 QuorumPeerMain
12478 Jps
12191 Kafka
[hadoop@Master ~]$ jps -m
11905 Kafka /opt/kafka/config/server-2.properties
11619 Kafka /opt/kafka/config/server-1.properties
12488 Jps -m
8589 QuorumPeerMain /opt/zookeeper/bin/../conf/zoo.cfg
12191 Kafka /opt/kafka/config/server-3.properties创建topic(指定副本数量为3)
[hadoop@Master ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Created topic "my-replicated-topic".查看所有的topic信息
[hadoop@Master ~]$ kafka-topics.sh --list --zookeeper localhost:2181
my-replicated-topic
test查看某个topic的详细信息
[hadoop@Master ~]$ kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1启动生产者
$ kafka-console-producer.sh --broker-list localhost:9093,localhost:9094,localhost:9095 --topic my-replicated-topic启动消费者
$ kafka-console-consumer.sh --zookeeper localhost:2181 --topic my-replicated-topic --from-beginning测试
- 生产者生产数据

- 消费者消费数据

单节点多borker容错性测试
Kafka是支持容错的,上面我们已经完成了Kafka单节点多Blocker的部署,下面我们来对Kafka的容错性进行测试,测试步骤如下
(1).查看topic的详细信息,观察那个blocker的角色是leader,那些blocker的角色是follower
[hadoop@Master ~]$ kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1(2).手工kill掉任意一个状态是follower的borker,测试生成和消费信息是否正确
步骤1中可以看到 2 为leader,1 和 3为 follower,将follower为1的进程kill掉

启动生产和消费者测试信息是否正确


结论:kill掉任意一个状态是follower的broker,生成和消费信息正确,不受任何影响
(3).手工kill掉状态是leader的borker,测试生产和消费的信息是否正确
borker2的角色为leader,将它kill掉,borker 3变成了leader

启动生产和消费者测试信息是否正确


结论:kill掉状态是leader的borker,生产和消费的信息正确
总结:不管当前状态的borker是leader还是follower,当我们kill掉后,只要有一个borker能够正常使用,则消息仍然能够正常的生产和发送。即Kafka的容错性是有保证的!
2.Kafka 集群搭建(多节点多Broker)
Kafka 集群方式部署,需要先安装ZK集群,笔者是三个节点组成的集群,具体安装配置请参考Hadoop HA 高可用集群搭建 中的ZK集群安装,在这笔者主要介绍Kafka的集群安装配置。
下载安装包
wget http://mirror.bit.edu.cn/apache/kafka/0.9.0.0/kafka_2.10-0.9.0.0.tgz解压安装包
tar -zxvf kafka_2.10-0.9.0.0.tgz -C ~/export/servers/创建软连接
ln -s kafka_2.10-0.9.0.0/ kafka修改配置文件server.properties
############################# Server Basics #############################
# broker 的全局唯一编号,不能重复
broker.id=0
############################# Socket Server Settings #############################
# 配置监听,,默认
listeners=PLAINTEXT://:9092
# 用来监听连接的端口,producer和consumer将在此端口建立连接,,默认
port=9092
# 处理网络请求的线程数量,默认
num.network.threads=3
# 用来处理磁盘IO的线程数量,默认
num.io.threads=8
# 发送套接字的缓冲区大小,默认
socket.send.buffer.bytes=102400
# 接收套接字的缓冲区大小,默认
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区大小,默认
socket.request.max.bytes=104857600
############################# Log Basics #############################
# kafka 运行日志存放路径
log.dirs=/root/export/servers/logs/kafka
# topic 在当前broker上的分片个数,默认为1
num.partitions=2
# 用来恢复和清理data下数据的线程数量,默认
num.recovery.threads.per.data.dir=1
############################# Log Retention Policy #############################
# segment文件保留的最长时间,超时将被删除,默认
log.retention.hours=168
# 滚动生成新的segment文件的最大时间,默认
log.roll.hours=168配置环境变量
# Kafka Environment Variable
export KAFKA_HOME=/root/export/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin分发安装包
注意:分发安装包,也要创建软连接,配置环境变量
scp -r ~/export/servers/kafka_2.10-0.9.0.0/ storm02:~/export/servers
scp -r ~/export/servers/kafka_2.10-0.9.0.0/ storm03:~/export/servers再次修改配置文件
笔者的ZK集群,使用的节点的主机名分别为storm01、storm02、storm03
依次修改各服务器上配置文件server.properties 的 broker.id,分别是0,1,2不得重复
修改host.name分别为storm01,storm02,storm03
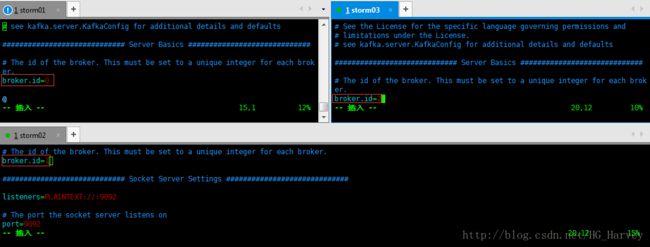
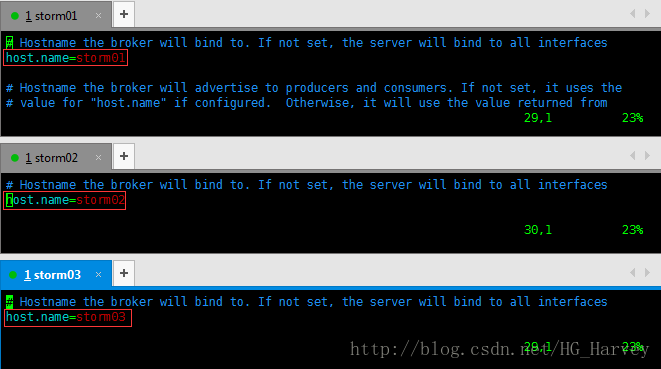
启动Kafka集群
注意:在启动Kafka集群前,确保ZK集群已经启动且能够正常运行

测试
- 创建topic
[root@storm01 ~]# kafka-topics.sh --create --zookeeper storm01:2181 --replication-factor 3 --partitions 2 --topic test
Created topic "test".
[root@storm01 ~]# kafka-topics.sh --describe --zookeeper storm01:2181 --topic test
Topic:test PartitionCount:2 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0- 启动生产者
[root@storm01 ~]# kafka-console-producer.sh --broker-list storm01:9092,storm02:9092,storm03:9092 --topic test
hello
hello kafka cluster
test
hello storm- 启动两个消费者,消费消息
[root@storm02 ~]# kafka-console-consumer.sh --zookeeper storm02:2181 --topic test --from-beginning
hello
hello kafka cluster
test
hello storm[root@storm03 ~]# kafka-console-consumer.sh --zookeeper storm03:2181 --topic test --from-beginning
hello
hello kafka cluster
test
hello stormKafka集群模式(多节点多Broker)下Broker容错性测试
Kafka 单节点多Broker中笔者已经做了Broker的容错性测试,得出的结论是:不管当前状态的borker是leader还是follower,当我们kill掉后,只要有一个borker能够正常使用,则消息仍然能够正常的生产和发送。即Kafka的容错性是有保证的!
Kafka 集群中和单节点多Broker的测试相同,结果相同,请参考Kafka 单节点多Broker容错性测试