Bulk Load——Spark 批量导入多列数据到HBase(scala/Java)
文章目录
- 一、最终流程
- 二、使用Put写入
- 三、批量写入,BulkLoad
- 四、Java BulkLoad 多列KeyValue(未成功-not Cell)
- 五、Scala BulkLoad 多列KeyValue(未成功-相同RowKey)
- 六、Scala BulkLoad Put 预分区
- 七、补充
- 八、优化
- 九、Scala BulkLoad 错误记录
- 参考
一、最终流程
数据量预估,预分裂 ——> 准备HBase表 ——> Spark加载HDFS上的数据 ——> 数据清洗及排序 ——> 数据以HFile的形式写入HDFS ——> BulkLoad ——> 优化
未优化时,大概1200万条数据/h (10G数据)
二、使用Put写入
参考了很多资料后,猜测使用Put写入,也是Bulk Load,并不只是KeyValue才能批量加载
参考连接
只是Put是以行为单位,KeyValue以列为单位,按理说,应该是KeyValue更快
补充:该问题与我想法相似,追溯源码,到底层仍未看出究竟
import util.HdfsUtils
import org.apache.log4j.Logger
import org.slf4j.LoggerFactory
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.mapreduce.Job
import org.apache.log4j.Level
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.matching.Regex
/**
* write data to HBase by 'Put'
* Date: 2019-04-29
* Time: 17:13
* Author: wh
* Version: V1.0.0
*/
class HBaseTest {
}
object CleanToHBase {
private val PARTTERN: Regex = """。。。。。。""".r
private val LOG = LoggerFactory.getLogger(classOf[HBaseTest])
private val HdfsFilePath = HdfsUtils.HDFS_SCHEME + "。。。。。。"
private final val NULL_FIELDS = Array("-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-")
private val NUM_FIELDS: Int = 17
/**
* 解析输入的日志数据
*
* @param line logline
* @return
*/
def logLineSplit(line: String): Array[String] = {
val options = PARTTERN.findFirstMatchIn(line)
var fileds = new Array[String](NUM_FIELDS)
// 。。。。。。清洗逻辑
fileds
}
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
LOG.info("Start.")
val startTime: Long = System.currentTimeMillis()
// 1. Spark清洗
val sparkConf = new SparkConf().setAppName("Put to HBase test").setMaster("local")
val sc = new SparkContext(sparkConf)
var logRDD = sc.textFile(HdfsFilePath, 12)
val splitRDD = logRDD.map(line => logLineSplit(line))
// 2. HBase 信息
val tableName = "bdTest2"
val familyName = Bytes.toBytes("infos")
// 3. HBase MapReduce Bulk Job
sc.hadoopConfiguration.set("hbase.zookeeper.quorum", "cluster")
sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort", "2181")
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tableName)
val hbaseBulkJob = Job.getInstance(sc.hadoopConfiguration)
hbaseBulkJob.setOutputKeyClass(classOf[ImmutableBytesWritable])
hbaseBulkJob.setOutputValueClass(classOf[Result])
hbaseBulkJob.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
var i = 0
// 4. write data to HBase
val hbasePuts = splitRDD.map{ line =>
val put = new Put(Bytes.toBytes("row-" + System.nanoTime())) // 测试用
put.addColumn(familyName, Bytes.toBytes("column name"), Bytes.toBytes(line(1)))
put.addColumn(familyName, Bytes.toBytes("column name"), Bytes.toBytes(line(2)))
// 。。。。。。other column
(new ImmutableBytesWritable(), put)
}
hbasePuts.saveAsNewAPIHadoopDataset(hbaseBulkJob.getConfiguration)
LOG.info("Done.")
LOG.info("Time elapsed {} seconds.", (System.currentTimeMillis() - startTime) / 1000)
sc.stop()
}
}
注意以下区别,网上很多人,set了class又在save的时候传class,想想就知道,肯定有多余的啊:

三、批量写入,BulkLoad
找了大量资料,看了国内外很多文章,几乎都是KeyValue一个Cell写来写去
批量写入的优势:
- 数据可立即供HBase使用
- 不使用预写日志(WAL),不会出现flush和split(未验证)
- 更少的垃圾回收
- The bulk load feature uses a MapReduce job to output table data in HBase’s internal data format, and then directly loads the generated StoreFiles into a running cluster. Using bulk load will use less CPU and network resources than simply using the HBase API.
BulkLoad操作则是在外部以MapReduce作业的方式写HFile格式的文件,然后放入HDFS,再通知“HBase”来管理这些数据**
参考1
参考2
参考3
参考4
一般过程包括:
- 估计数据的总大小,并确定HBase中的最佳region数
- 创建于的空表,预分裂,为避免冷热数据,考虑对行键加盐
- 在Spark中使用简单的自定义分区程序来拆分RDD,以匹配目标region拆分
- 使用Spark和标准Hadoop库生成HFile
- 使用标准HBase命令行批量加载工具(或代码)将数据加载到HBase中
四、Java BulkLoad 多列KeyValue(未成功-not Cell)
package core;
/*
* It's not work, for List to Cell, see {@code BulkLoadToHBase.scala}
* Date: 2019-04-30
* Time: 下午3:38
* Author: wh
* Version: V1.0.0
*/
import util.HdfsUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapred.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.tool.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import org.slf4j.LoggerFactory;
import scala.Tuple2;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class CleanToHBase {
private static final org.slf4j.Logger LOG = LoggerFactory.getLogger(CleanToHBase.class);
public static final int NUM_FIELDS = 17;
// public static long CURSOR = 0; TODO 累加器
private static final String LOG_ENTRY_PATTERN = "。。。。。。";
private static final Pattern PATTERN = Pattern.compile(LOG_ENTRY_PATTERN);
private static final String HdfsFilePath = HdfsUtils.HDFS_SCHEME + "。。。。。。";
private static final String TABLE_NAME = "tableName";
public static String[] logLineSplit(String line) {
Matcher matcher = PATTERN.matcher(line);
String[] fileds = new String[NUM_FIELDS];
int i = 0;
if (!matcher.matches() || NUM_FIELDS != matcher.groupCount()) {
LOG.error("Bad options or bad length =============》");
LOG.info(line);
for (String s : fileds) fileds[i++] = "-";
return fileds;
}
for (; i < NUM_FIELDS; i++) {
fileds[i] = matcher.group(i);
}
return fileds;
}
public static void main(String[] args) throws IOException {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN);
Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
LOG.info("Start.");
long startTime = System.currentTimeMillis();
System.setProperty("HADOOP_USER_NAME", "hdfs");
// 1. Spark清洗
SparkConf conf = new SparkConf().setAppName("Log clean to HBase").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile(HdfsFilePath);
JavaRDD<String[]> filedsRDD = lines.map(CleanToHBase::logLineSplit);
// 2. HBase 信息
TableName tableName = TableName.valueOf(TABLE_NAME);
byte[] familyName = Bytes.toBytes("infos");
// 3. HBase MapReduce Bulk Load Job
Configuration hbConf = HBaseConfiguration.create();
hbConf.set("hbase.zookeeper.quorum", "cluster");
hbConf.set("hbase.zookeeper.property.clientPort", "2181");
hbConf.set(TableOutputFormat.OUTPUT_TABLE, TABLE_NAME);
Connection connection = ConnectionFactory.createConnection(hbConf);
Table table = connection.getTable(tableName);
Job hbaseBulkJob = Job.getInstance(hbConf);
// hbaseBulkJob.setMapOutputKeyClass(ImmutableBytesWritable.class);
// hbaseBulkJob.setMapOutputValueClass(Put.class);
// hbaseBulkJob.setOutputFormatClass(HFileOutputFormat2.class);
hbaseBulkJob.setJarByClass(CleanToHBase.class);
// HFile 设置
RegionLocator regionLocator = connection.getRegionLocator(tableName);
HFileOutputFormat2.configureIncrementalLoad(hbaseBulkJob, table, regionLocator);
// 4. Prepare for HFile Put
JavaPairRDD<ImmutableBytesWritable, List<Tuple2<ImmutableBytesWritable, KeyValue>>> hbasePutsRDD = filedsRDD.mapToPair((PairFunction<String[], ImmutableBytesWritable, List<Tuple2<ImmutableBytesWritable, KeyValue>>>) line -> {
// row key: TODO 优化
List<Tuple2<ImmutableBytesWritable, KeyValue>> keyValueList = new ArrayList<>();
byte[] rowkey = Bytes.toBytes(line[0].hashCode() + String.valueOf(System.currentTimeMillis()));
ImmutableBytesWritable writable = new ImmutableBytesWritable(rowkey);
keyValueList.add(new Tuple2<>(writable, new KeyValue(rowkey, familyName, Bytes.toBytes("column name"), Bytes.toBytes(line[0]))));
keyValueList.add(new Tuple2<>(writable, new KeyValue(rowkey, familyName, Bytes.toBytes("column name"), Bytes.toBytes(line[1]))));
// other column
// TODO List to Cell and sort
return new Tuple2<>(writable, keyValueList);
});
// 5. store HFile
String temp = "/tmp/hbase/" + TABLE_NAME + "_" + System.currentTimeMillis();
hbasePutsRDD.saveAsNewAPIHadoopFile(temp, ImmutableBytesWritable.class, List.class, HFileOutputFormat2.class, hbaseBulkJob.getConfiguration());
LoadIncrementalHFiles bulkLoader = new LoadIncrementalHFiles(hbConf);
Admin admin = connection.getAdmin();
// 6. Bulk load to HBase
bulkLoader.doBulkLoad(new Path(temp), admin, table, regionLocator);
LOG.info("Done. Time elapsed {} seconds.", (System.currentTimeMillis() - startTime) / 1000);
sc.stop();
}
}
五、Scala BulkLoad 多列KeyValue(未成功-相同RowKey)
package core
import org.apache.hadoop.fs.Path
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2
import org.apache.hadoop.hbase.tool.LoadIncrementalHFiles
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, KeyValue, TableName}
import org.apache.hadoop.mapreduce.Job
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.slf4j.LoggerFactory
import util.HdfsUtils
import scala.util.matching.Regex
/**
* Date: 2019-05-05
* Time: 10:54
* Author: wh
* Version: V1.0.0
*/
class BulkLoadToHBase {
}
object BulkLoad {
private val PARTTERN: Regex = """......""".r
private val LOG = LoggerFactory.getLogger(classOf[BulkLoadToHBase])
private val NUM_FIELDS: Int = 17
private val MODULUS: Int = 5
private final val NULL_FIELDS = ("-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-")
private final val COL_NAME = Array(......)
private val HdfsFilePath = HdfsUtils.HDFS_SCHEME + "......"
private val TABLE_NAME = "table name"
private val FAMILY_NAME = "infos".getBytes()
/**
* 正则拆解输入的日志数据
*
* @param line logline
* @return
*/
def logLineSplit(line: String): (String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String) = {
val options = PARTTERN.findFirstMatchIn(line)
// 匹配失败
if (options.isEmpty) {
LOG.error("Bad log, no options =============》")
LOG.info(line)
NULL_FIELDS
}
else {
val m = options.get
if (NUM_FIELDS != m.groupCount) {
LOG.error("Bad length {} =============》", m.groupCount)
LOG.info(line)
NULL_FIELDS
}
else {
(m.group(1), m.group(2), m.group(3), m.group(4), m.group(5), m.group(6), m.group(7), m.group(8), m.group(9), m.group(10), m.group(11), m.group(12), m.group(13), m.group(14), m.group(15), m.group(16), m.group(17))
}
}
}
def salt(key: String, modulus: Int): String = {
val saltAsInt = Math.abs(key.hashCode) % modulus
// left pad with 0's (for readability of keys)
val charsInSalt = digitsRequired(modulus)
("%0" + charsInSalt + "d").format(saltAsInt) + ":" + key
}
// number of characters required to encode the modulus in chars (01,02.. etc)
def digitsRequired(modulus: Int): Int = {
(Math.log10(modulus - 1) + 1).asInstanceOf[Int]
}
// A partitioner that puts data destined for the same HBase region together
class SaltPrefixPartitioner[K, V](modulus: Int) extends Partitioner {
val charsInSalt: Int = digitsRequired(modulus)
override def getPartition(key: Any): Int = {
key.toString.substring(0, charsInSalt).toInt
}
override def numPartitions: Int = modulus
}
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
System.setProperty("user.name", "hdfs")
System.setProperty("HADOOP_USER_NAME", "hdfs")
LOG.info("Start.")
val startTime: Long = System.currentTimeMillis()
// 1. data clean by Spark
val sparkConf = new SparkConf().setAppName("Log clean to HBase").setMaster("local")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable]))
val sc = new SparkContext(sparkConf)
var logRDD = sc.textFile(HdfsFilePath, 24)
val splitRDD = logRDD.map(line => logLineSplit(line))
// prepare for KeyValue
val beforeCellsRDD = splitRDD.flatMap(x => {
val rowKey = salt(x._1, MODULUS)
for (i <- 0 until NUM_FIELDS) yield {
val colName = COL_NAME(i)
val colValue = x.productElement(i)
(rowKey, (colName, colValue))
}
})
// cells of data for HBase
val cellsRDD = beforeCellsRDD.map(x => {
val rowKey = x._1.getBytes()
val kv = new KeyValue(
rowKey,
FAMILY_NAME,
x._2._1.toString.getBytes(),
x._2._2.toString.getBytes()
)
(new ImmutableBytesWritable(rowKey), kv)
})
// repartition and sort the data - HFiles want sorted data
val partitionedRDD = cellsRDD.repartitionAndSortWithinPartitions(new SaltPrefixPartitioner(MODULUS))
// 2. HBase MapReduce Bulk Load Job
val hbConf = HBaseConfiguration.create()
hbConf.set("hbase.zookeeper.quorum", "node5,node6,node7,node8")
hbConf.set("hbase.zookeeper.property.clientPort", "2181")
hbConf.set("hbase.mapreduce.hfileoutputformat.table.name", TABLE_NAME)
val connection = ConnectionFactory.createConnection(hbConf)
val tableName = TableName.valueOf(TABLE_NAME)
val table = connection.getTable(tableName)
val hbaseBulkJob = Job.getInstance(hbConf, "HFile Bulk Load Job")
// 3. HFile config, Bulk load to HBase directly
val regionLocator = connection.getRegionLocator(tableName)
HFileOutputFormat2.configureIncrementalLoad(hbaseBulkJob, table.getDescriptor, regionLocator)
hbaseBulkJob.setMapOutputKeyClass(classOf[ImmutableBytesWritable])
hbaseBulkJob.setMapOutputValueClass(classOf[KeyValue])
hbaseBulkJob.setOutputFormatClass(classOf[HFileOutputFormat2])
// hbaseBulkJob.setJarByClass(classOf[JavaCleanToHBase])
val hfileOutPath = "/tmp/hbase/" + TABLE_NAME + "_" + System.currentTimeMillis()
hbaseBulkJob.getConfiguration.set("mapred.output.dir", hfileOutPath)
partitionedRDD.saveAsNewAPIHadoopDataset(hbaseBulkJob.getConfiguration)
// partitionedRDD.saveAsNewAPIHadoopFile(
// hfileOutPath,
// classOf[ImmutableBytesWritable],
// classOf[Put],
// classOf[HFileOutputFormat2],
// hbaseBulkJob.getConfiguration)
// 4. Bulk load to HBase
// val bulkLoader = new LoadIncrementalHFiles(hbConf)
// val admin = connection.getAdmin
// bulkLoader.doBulkLoad(new Path(hfileOutPath), admin, table, regionLocator)
LOG.info("Done. Time elapsed {} seconds.", (System.currentTimeMillis - startTime) / 1000)
sc.stop()
}
}
六、Scala BulkLoad Put 预分区
package core
import org.apache.hadoop.hbase.{HBaseConfiguration, KeyValue, TableName}
import org.apache.hadoop.hbase.client.{ConnectionFactory, Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{HFileOutputFormat2, TableOutputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.slf4j.LoggerFactory
import util.HdfsUtils
import scala.util.matching.Regex
/**
* Date: 2019-05-06
* Time: 15:33
* Author: wh
* Version: V1.0.0
*/
class BulkLoadToHBasePut {
}
object BulkLoadPut {
private val PARTTERN: Regex = """......""".r
private val LOG = LoggerFactory.getLogger(classOf[BulkLoadToHBase])
private val NUM_FIELDS: Int = 17
private val MODULUS: Int = 5
private final val NULL_FIELDS = ("-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-", "-")
private final val COL_NAME = Array(......)
private val HdfsFilePath = HdfsUtils.HDFS_SCHEME + "......"
private val TABLE_NAME = "table name"
private val FAMILY_NAME = "infos".getBytes()
/**
* 正则拆解输入的日志数据
*
* @param line logline
* @return
*/
def logLineSplit(line: String): (String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String) = {
val options = PARTTERN.findFirstMatchIn(line)
// 匹配失败
if (options.isEmpty) {
LOG.error("Bad log, no options =============》")
LOG.info(line)
NULL_FIELDS
}
else {
val m = options.get
if (NUM_FIELDS != m.groupCount) {
LOG.error("Bad length {} =============》", m.groupCount)
LOG.info(line)
NULL_FIELDS
}
else {
(m.group(1), m.group(2), m.group(3), m.group(4), m.group(5), m.group(6), m.group(7), m.group(8), m.group(9), m.group(10), m.group(11), m.group(12), m.group(13), m.group(14), m.group(15), m.group(16), m.group(17))
}
}
}
def salt(key: String, modulus: Int): String = {
val saltAsInt = Math.abs(key.hashCode) % modulus
// left pad with 0's (for readability of keys)
val charsInSalt = digitsRequired(modulus)
("%0" + charsInSalt + "d").format(saltAsInt) + ":" + key + ":" + System.nanoTime().toString.substring(8, 13)
}
// number of characters required to encode the modulus in chars (01,02.. etc)
def digitsRequired(modulus: Int): Int = {
(Math.log10(modulus - 1) + 1).asInstanceOf[Int]
}
// A partitioner that puts data destined for the same HBase region together
class SaltPrefixPartitioner[K, V](modulus: Int) extends Partitioner {
val charsInSalt: Int = digitsRequired(modulus)
override def getPartition(key: Any): Int = {
key.toString.substring(0, charsInSalt).toInt
}
override def numPartitions: Int = modulus
}
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
System.setProperty("user.name", "hdfs")
System.setProperty("HADOOP_USER_NAME", "hdfs")
LOG.info("Start.")
val startTime: Long = System.currentTimeMillis()
// 1. data clean by Spark
val sparkConf = new SparkConf().setAppName("Log clean to HBase").setMaster("local")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable]))
val sc = new SparkContext(sparkConf)
var logRDD = sc.textFile(HdfsFilePath, 24)
val splitRDD = logRDD.map(line => logLineSplit(line))
val putsRDD = splitRDD.map{ line =>
val rowKey = salt(line._1, MODULUS).getBytes()
val put = new Put(rowKey)
for (i <- 0 until NUM_FIELDS) {
val colName = COL_NAME(i).getBytes()
val colValue = line.productElement(i).toString.getBytes()
put.addColumn(FAMILY_NAME, colName, colValue)
}
(new ImmutableBytesWritable(rowKey), put)
}
val partitionedRDD = putsRDD.repartitionAndSortWithinPartitions(new SaltPrefixPartitioner(MODULUS))
// 2. HBase MapReduce Bulk Load Job
sc.hadoopConfiguration.set("hbase.zookeeper.quorum", "node5,node6,node7,node8")
sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort", "2181")
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, TABLE_NAME)
val hbaseBulkJob = Job.getInstance(sc.hadoopConfiguration)
hbaseBulkJob.setOutputKeyClass(classOf[ImmutableBytesWritable])
hbaseBulkJob.setOutputValueClass(classOf[Result])
hbaseBulkJob.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val hfileOutPath = "/tmp/hbase/" + TABLE_NAME + "_" + System.currentTimeMillis()
hbaseBulkJob.getConfiguration.set("mapred.output.dir", hfileOutPath)
partitionedRDD.saveAsNewAPIHadoopDataset(hbaseBulkJob.getConfiguration)
// partitionedRDD.saveAsNewAPIHadoopFile(
// hfileOutPath,
// classOf[ImmutableBytesWritable],
// classOf[Put],
// classOf[HFileOutputFormat2],
// hbaseBulkJob.getConfiguration)
// 4. Bulk load to HBase
// val bulkLoader = new LoadIncrementalHFiles(hbConf)
// val admin = connection.getAdmin
// bulkLoader.doBulkLoad(new Path(hfileOutPath), admin, table, regionLocator)
LOG.info("Done. Time elapsed {} seconds.", (System.currentTimeMillis - startTime) / 1000)
sc.stop()
}
}
七、补充
- 预分区
- HBase默认建表时有一个region,这个region的rowkey是没有边界的,即没有startkey和endkey.
- 数据会先写入内存,达到
MemStore阈值后落磁盘为HFile(StoreFile),HFile数量达到阈值又会触发compact操作,HFile越来越大,超过阈值后split,频繁的region split会消耗宝贵的集群I/O资源 - 基于此,我们可以控制在建表的时候,创建多个空region,并确定每个region的起始和终止rowky,剩下的就是良好的rowkey设计了
-
估算分区数量
-
重写分区器
// A partitioner that puts data destined for the same HBase region together
class SaltPrefixPartitioner[K,V](modulus: Int) extends Partitioner {
val charsInSalt: Int = digitsRequired(modulus)
override def getPartition(key: Any): Int = {
key.toString.substring(0,charsInSalt).toInt
}
override def numPartitions: Int = modulus
}
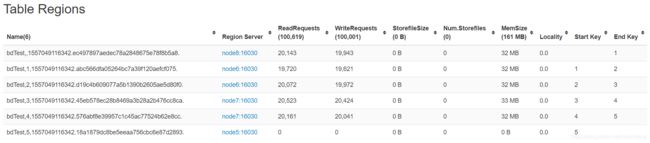
hmaster的10610端口可查看regin信息
八、优化
九、Scala BulkLoad 错误记录
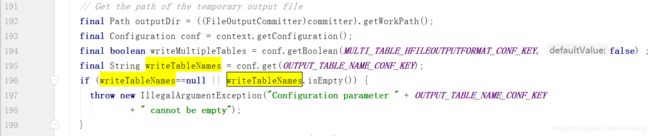
- 问题:
hbase.mapreduce.hfileoutputformat.table.name cannot be empty:
查看源码得知:
解决:
hbConf.set(TableOutputFormat.OUTPUT_TABLE, TABLE_NAME)
-
问题:
Added a key not lexically larger than previous
排序的问题
**解决:**重写分区器并调用repartitionAndSortWithinPartitions(somePartitions) -
问题:
object not serializable (class: org.apache.hadoop.hbase.io.ImmutableBytesWritable
解决:
val sparkConf = new SparkConf().setAppName("Log clean to HBase").setMaster("local")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable]))
val sc = new SparkContext(sparkConf)
- 问题:
Added a key not lexically larger than previous,查看日志,发觉重复写入数据
解决: 使用一条数据进行测试,依然出现该问题,debug发现:
正则的group(0)是字符串本身,下标从1开始,才是我们想要的
问题依然存在: 貌似一行拆分成多列后,每次写入的RowKey相同导致了错误
参考
Put也是BulkLoad吧?
BulkLoad 1
BulkLoad 2
BulkLoad 3
BulkLoad 4
3 Steps for Bulk Loading 1M Records in 20 Seconds Into Apache Phoenix
Efficient bulk load of HBase using Spark
BulkLoad 代码借鉴
HBase clientAPI基本操作
Spark通过bulkLoad对HBase快速导入
object not serializable (class: org.apache.hadoop.hbase.io.ImmutableBytesWritable)