Redis技能——Codis
- codis是选用了一系列已证明靠谱的方案来构建(如zk选主/存放元数据;采用无状态proxy,而不是smart client等)
- 为方便运维提供了一系列工具/接口
- 再加上公司内部的一定规模应用
所以大家用它更多。
链接:https://www.zhihu.com/question/30857837/answer/169207128
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
redis cluster的原理,是基于分片。一个 Redis cluster集群包含 16384 个哈希槽, 任意一个key都可以通过 CRC16(key) % 16384 这个公式计算出应当属于哪个槽。每个槽应当落在哪个节点上,也是事先定好。这样,进行任一操作时,首先会根据key计算出对应的节点,然后操作相应的节点就可以了。
所以说,其实cluster跟单点相比,只是多了一个给key计算sharding值的过程,并没有增加多少复杂度,个人认为完全可以放心使用。像增删节点、重启这些对redis本身的操作,和client端对数据的操作,是两套流程,可以做到互不干扰。关于节点故障,一是有slave,二是即便这一个节点完全挂掉,也只是落在这个节点上的数据不可用,不会有类似“雪崩”这样的问题影响整个集群。数据的恢复之类的逻辑,也与单点完全一致,是独立于集群其他部分的。
redis cluster的整个设计是比较简单的,并没有引入太多新问题,大部分操作都可以按照单点的操作流程进行操作。至于cluster最终的易用性,其实很大程度上取决client端的代码可靠性,而jedis现在的代码也已经很完善了,用起来也比较方便。
关于运维,可以看一下搜狐的cacheCloud, 对cluster的管理现在也比较完善了。
所以,个人觉得,目前cluster完全可以取代codis,tweemproxy在生产环境使用。
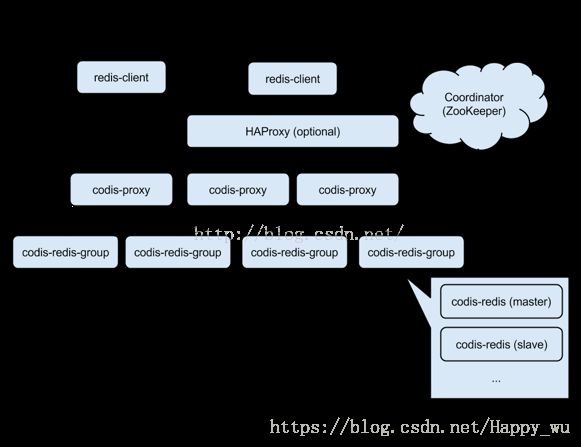
codis中的各个组件:
1. 先看 ServerGroup 和 Slot。
一个 Proxy 可以对应多个 ServerGroup;
ServerGroup 是一组 Codis Server,一个 ServerGroup 只有一个 Master(Codis Server),而且虽然有多个 Codis Server,Proxy 只访问 ServerGroup 中的 Master,Slave 可用作故障切换;
Slot 是一个逻辑概念,一共 1024 个,使用 crc32(key) % 1024 计算 Slot id,而且一个(或多个) Slot 属于一个 ServerGroup,1024 个 Slot 一起分用多个 ServerGroup 资源;
当 Slot 所在 ServerGroup 内存不够的时候可以把此 Slot 迁移到另一个内存使用少的 ServerGroup,实现扩容的目的,而当所有 ServerGroup 内存不够的时候增加新的 ServerGroup 即可。
ServerGroup 数据结构:
Slot 数据结构:
2. 再看看 Router,Router 用来转发 linstener 接收的 Codis 请求。
最核心的是 SharedBackendConn 的数据结构:
再看看这里 Slot 的数据结构:
每一个 ServerGroup 有一个 Master (Codis Server),bc 只能是 Master (的连接)。
Proxy 启动的时候,会去 fill Proxy 的 router,这部分代码读起来感觉怪怪的,其实就是对于 bc,首先建立到 bc.addr 的连接,然后先创建从 bc 读取结果的 chan *Request(读取之后会设置结果,以便发送给请求方),放入 goroutine 不断读取,最后循环从 input 中获取请求,经过路由转发之后写入 bc。
说说路由转发的逻辑,分为两部分:
1. Proxy 接收请求和返回数据,这个实现类似上面说的 Proxy 和 Master 的交互;
2. Proxy 收到请求方的数据之后需要 decode,如果是类似 MGET 指令的话会分拆成多个 GET 请求,然后向 Master 发送请求;根据 crc32(key) % 1024 计算出 Slot id,然后走 Proxy 和 Master 的交互流程(ps,如果此 Slot 处在迁移状态,那么会先调用 SLOTSMGRTTAGONE 把 key 迁移至新 ServerGroup)。
3. 看看 Proxy。
conf 是 Proxy 的配置数据;
topo 是 ZK 或 etcd 操作接口,里面保存了 ProductName,一个 Proxy 实例只有一个 ProductName(就是一个服务);
groups 是 ServerGroup 信息,key 是 Slot id,value 是 ServerGroup id;
lastActionSeq 用于保存 action seq,其中 evtbus 保存 watch proxy 和 action 的 事件信息;
router 下面再讲;
listener 是 Proxy 的 Listener;
kill、wait、stop 用来正确的处理退出逻辑。
proxy 的处理过程(不说 load 配置和如何处理退出的部分):
1). 先初始化 Router,主要是初始化 Router 中的 1024 个 Slot,只是把 Slot 的 id 标识出来 ;
2). 在 zk 中注册 proxy 的临时节点,节点路径:/zk/codis/db_{productName}/proxy/{proxyId},内容是以 ProxyInfo 数据结构报错的 proxy 信息;
3). 在 zk 中注册 proxy fence 的永久节点,节点路径:/zk/codis/db_{productName}/fence/{proxyAddr},内容为空。
为什么有了 proxy 节点还需要 fence 节点呢,是为了来判断 proxy 是否是正常退出的,比如使用 kill -9 杀 proxy 以后,proxy 节点会消失,fence 节点不会消失,对比下就知道是非正常退出。
proxy 在收到 kill 信号(os.Interrupt, syscall.SIGTERM, os.Kill)后会把 proxy fence 和 proxy 节点删除,proxy 也就下线了,但是如果 kill -9 就不会删除,需要手动删除。
4). 此时还要等待 proxy 是在线状态,这里的逻辑是 proxy 刚启动时候的状态是 PROXY_STATE_OFFLINE(main.go 会调用 dashboard api 设置自己为 PROXY_STATE_ONLINE,为了保证 proxy 信息已经注册到 zk,main.go 会等待一秒钟再设置),一旦 proxy 是在线状态之后,会开一个 goroutine rewatch proxy 状态(zk 节点是 /zk/codis/db_{productName}/proxy),如果 proxy 有变化会通知到 evtbus 这个 channel 里;
5). 开启一个 goroutine 来 watch action 节点 /zk/codis/db_{productName}/actions 的 children,如果有变化也通知给 evtbus;
6). 下一步,fill Router 的 Slot,有两部分,一部分是 fill Server 数据结构中的 groups,key 是 Slot id,value 是 Group id,另一部分是 fill Router 中的 Slot 中的 bc,Router 中的 pool 是连接池,Slot 从 pool 中取 bc;
7). 此时开始处理请求,使用 goroutine,拿到请求扔给 Router 部分来处理;
8). 开启一个 loopEvents,如果检查到有 kill 信号,删除 zk 中的 proxy 节点,下线;而且从 evtbus 里读取事件,做处理;额外的,定时器,每隔一段事件 PING 一次 proxy 后端的 Codis Server,以保持探活。
4. proxy 之间如何协调。
第 3 步说了,proxy 会监听 /zk/codis/db_{productName}/proxy 和 /zk/codis/db_{productName}/actions 的变化,codis 就是通过这两个监听机制保证 proxy 的信息一致。
/zk/codis/db_{productName}/proxy 主要是获取 proxy 的状态信息,如果状态变成 PROXY_STATE_MARK_OFFLINE,则删除 fence 节点和 proxy 节点,并在内存中标记状态为 PROXY_STATE_MARK_OFFLINE,此处 loopEvents 会停止,然后触发 serve() 的 s.close(),然后 handleConns 停止,serve() 停止,proxy 退出。
/zk/codis/db_{productName}/actions 则是监听 slot、group 等的变化,比如:
ACTION_TYPE_SLOT_MIGRATE
ACTION_TYPE_SLOT_CHANGED
ACTION_TYPE_SLOT_PREMIGRATE
ACTION_TYPE_SERVER_GROUP_CHANGED
ACTION_TYPE_MULTI_SLOT_CHANGED
收到这些变化之后,从 zk 中拿新的信息,来 fill 内存中 Slot 中的信息,然后会创建 /zk/codis/db_{productName}/ActionResponse/{seq}/proxyId 来确认 proxy 已经响应此 action。
还有一点,新建 action 的时候有个开关:needConfirm,如果为真,则会确认 proxy node 和 fence node 一致,而且会等待所有 proxy 回复了 action,如果有 proxy 没回复,则设置此 proxy 为 PROXY_STATE_MARK_OFFLINE,并报错。
5. 关于 Slot 迁移。
通过 dashboard api (/api/migrate) 来迁移,传入的数据结构如下:
然后把 From 到 To 的每个 slot 生成 MigrateTaskInfo。
然后把 MigrateTaskInfo 推到 globalMigrateManager,dashboard 启动的时候会初始化 globalMigrateManager,globalMigrateManager 数据结构如下:
MigrateTask 结构如下:
SlotMigrateProgress 结构如下:
初始化 globalMigrateManager 会创建 /zk/codis/db_{productName}/migrate_tasks,然后进入执行迁移的 loop,不断从 /zk/codis/db_{productName}/migrate_tasks 读取任务并迁移。
globalMigrateManager 收到 MigrateTaskInfo 后会创建任务 /zk/codis/db_{productName}/migrate_tasks/{seq},内容就是 MigrateTaskInfo 信息,然后迁移 api 返回。
主要的处理在 loop 里面:
1). 从 /zk/codis/db_{productName}/migrate_tasks/ 取出最早的 task,封装成 MigrateTask;
2). 做迁移 check,检查所有 slot,如果状态是 SLOT_STATUS_MIGRATE 或者 SLOT_STATUS_PRE_MIGRATE 的数量大于1,报错,如果等于1,判断是否是此 MigrateTask 中的 slot,如果不是则报错;
3). 修改 task 的状态为 MIGRATE_TASK_MIGRATING (migrating);
4). 迁移 slot,在迁移之前要把 slot 的状态改掉,如果原状态不是 SLOT_STATUS_MIGRATE,改成 SLOT_STATUS_PRE_MIGRATE,之后强制把状态改成 SLOT_STATUS_MIGRATE,而且修改 from group 和 to group。
5). 然后不断地把源 group master 的数据向 目标 group master 拷贝,完成之后修改 slot 状态为 SLOT_STATUS_ONLINE,from group 和 to group 为 INVALID_ID。
6). 迁移完之后会删除 task,也就是删除 zk /zk/codis/db_{productName}/migrate_tasks/{seq}。如果迁移失败而且 slot 状态为 SLOT_STATUS_PRE_MIGRATE(如果不是 SLOT_STATUS_PRE_MIGRATE,说明已经在迁移,需手动处理),会把 slot 状态改为 SLOT_STATUS_ONLINE。
7). 额外重要的一点,每次更新 slot 状态时,都会发起 slot 的 action,等待所有 proxy 回复才继续。而且 proxy 收到 slot 变化后,会更新 slot 状态,如果 slot 在迁移状态(根据 slot 的 migrate.bc 判断)有访问到达 proxy,会先把数据从 from group 拷到 to group,然后再从 to group 请求,这点衔接的挺好。