一文了解布隆过滤器
目录
一、问题引入
二、诞生背景
三、BF 简介及原理
四、BF 常用操作
五、BF 优缺点及应用场景
六、应用场景
七、特殊情况
八、Python实现简单的布隆过滤器算法
九、总结
十、参考链接
一、问题引入
一个网站有 20 亿 url 存在一个黑名单中,这个黑名单要怎么存?若此时随便输入一个 url,你如何快速判断该 url 是否在这个黑名单中?并且需在给定内存空间(比如:500M)内快速判断出。
二、诞生背景
如上述问题,查询某个元素是否存在于一个大型或者超大型数据集(千万、亿级别)中,这是布隆过滤器诞生的技术背景。由于数组、链表、树等数据结构存储的数据量过大时,消耗的内存也会呈现线性增长,最终成为系统瓶颈;如果采用哈希表,其时间复杂度为O(1),但是哈希表需要消耗的内存依然很高,URL字符串通过Hash得到一个Integer的值,Integer占4个字节,那20亿个URL理论上需要:20亿*4/1024/1024/1024=7.45G的内存。那么,为了更快更省内存的解决问题,布隆过滤器应运而生。
三、BF 简介及原理
3.1 哈希函数
介绍布隆过滤器之前,先简单了解下哈希函数。
哈希函数是将任意大小的数据元素转换成特定大小结果的函数。转换后的结果称为哈希值或哈希编码。如下图所示分别输出哈希编码与哈希值:
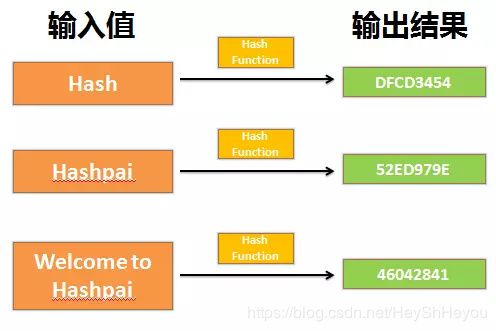

哈希函数是实现哈希表和布隆过滤器的基础。
3.2 BF 简介
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。
3.3 BF 原理
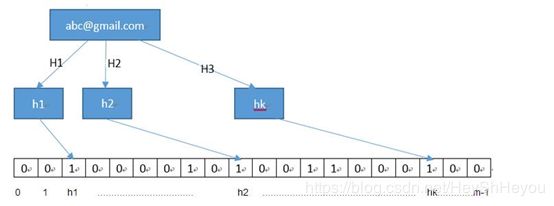
布隆过滤器的核心是由长度为m的位向量(可以理解为位数组)与k个不同的哈希函数组成。将数据(示例为:hash, Hash, HASH. 如下图)添加到布隆过滤器中,首先将数据输入到k个不同的哈希函数,得到k个不同的哈希值,然后在位向量中设置对应的结果位(对应图中的黄色位置)。
例如,将m设置为50,k设置为3。(注意,有时哈希函数会产生重叠位置,因此可以设置小于k的位置)。为了判断测试数据(图中右侧数据test)是否在过滤器中,我们再次将其提供给k个哈希函数,得到k个不同的哈希值并设置对应的结果位。
最终,我们检查测试数据对应的结果位是否已经被设置(黄色)。如果存在没有设置的结果位,则表示该测试数据(test)肯定不在集合中(图中测试结果出现蓝色位置)。否则,测试数据可能在集合中。
注意:如果k个查询结果位置全部为1,则可能在集合中。
为什么时可能呢?因为多个元素经过 hash 得到的结果可能在集合的同一位置,其误判率取决于使用的 hash 算法。

四、BF 常用操作
4.1 添加元素
- 将需要添加的元素给k个哈希函数
- 得到对应于位向量上的k个位置
- 将这k个位置设为1
4.2 查询元素
- 将需要查询的元素给k个哈希函数
- 得到对应于位向量上的k个查询结果位置
- 判断结果:
如果k个查询结果位置有一个为0(对应上图的蓝色位置;说明没有任何一个值映射到这个 bit 位上),则需要查询的元素肯定不在集合中;
如果k个查询结果位置全部为1,则可能在集合中。
4.3 删除元素
不支持直接删除元素。
原因:无法分辨哈希碰撞;同一位被两个值共同覆盖,删除其中一个则将其位置 0,判断另一个值时则直接返回 false(不存在);
解决方法:计数删除。但是计数删除需要额外存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。此时增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
五、BF 优缺点及应用场景
优点:空间效率和查询时间都比一般的算法要好的多。
缺点:存在一定的误识别率和删除相对困难。
六、应用场景
1、黑名单(如开篇引入的问题)
2、URL去重(减少磁盘 IO读写或者网络请求,普遍用于网络爬虫URL去重,例如在scrapy-redis爬虫框架实现布隆过滤器过滤已经爬取过的网页)
3、单词拼写检查(判断单词是否存在于合理正确的单词库中)
4、Key-Value缓存系统的Key校验(防止Redis缓存击穿)
5、ID校验,比如订单系统查询某个订单ID是否存在,如果不存在就直接返回。
七、特殊情况
7.1 超过预期容量
按照一万个元素设计,超过一万个后布隆过滤器准确率下降
解决思路:
a. 扩大存储原始数据
元素超过后扩充位向量成一个更大的布隆过滤器(如位向量个数翻倍)
b. 堆叠布隆过滤器个数 BF( scalable bloomfilter)
超过一万个元素后再生成一个新的一万容量的布隆过滤器,查询时同时查询多个,但性能相对稍差。
7.2 布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小
7.3 哈希函数的个数也需要权衡
个数越多则布隆过滤器bit位设置为1的速度越快,且布隆过滤器的效率越低;但是如果太少的话,误报率会变高。
八、Python实现简单的布隆过滤器算法
用Python模拟布隆过滤器的算法思路,主要函数如下,完整代码参见 GitHub。
def get_positions(self, url):
"""
返回url经过hash之后的位向量。此处采用三个hash函数构建。
取余数,保证向量组的比特位索引小于bit_size
:param url: 需要经过hash的数据
:return: url所在位向量的位置
"""
# hash(key, seed=0, signed=True)
# 参数解释:
# key: 需要hash的元素
# seed: 种子参数,随机化函数的一种方法。采用不同的种子参数,生成不同的hash值,防止不同数据的hash冲突
# signed: 默认True
# seed 参数解释参考:https://stackoverflow.com/questions/9241230/what-is-murmurhash3-seed-parameter
position_one = mmh3.hash(url, 60) % self.bit_size
position_two = mmh3.hash(url, 61) % self.bit_size
position_three = mmh3.hash(url, 62) % self.bit_size
return [position_one, position_two, position_three]九、总结
本文首先由一个实际问题引入布隆过滤器的诞生背景,介绍了布隆过滤器的基本原理、常用操作、优缺点、应用场景及特殊情况,最后给出简单的Python代码实现。水平一般,能力有限,本文中若存在描述不清或描述有误的地方还望读者留言指出,不吝赐教。
十、参考链接
https://www.jasondavies.com/bloomfilter
https://www.cnblogs.com/cpselvis/p/6265825.html
https://zhuanlan.zhihu.com/p/43263751