B站视频信息爬取
B站视频信息爬取
- 爬虫思路
- 网页分析
- 数据爬取
- 导入库
- 构造请求头
- 设定代理IP
- 数据获取
- 将获取内容写入excell文档
- 爬取数据部分展示
B站数据可视化视频逐渐流行,想做一期B站视频类型的数据分析,故开始爬取视频信息,来挖掘内容。
爬虫思路
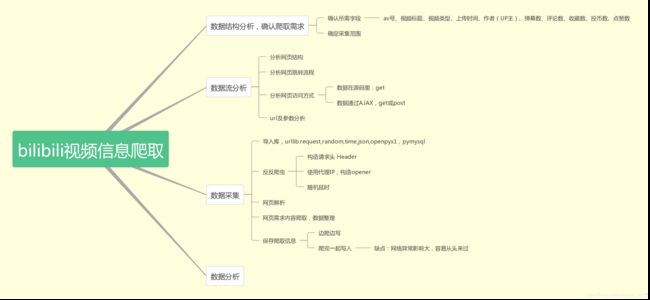
网页分析
目标是爬取每个视频的av号、视频标题、视频类型、上传时间、作者(UP主)、弹幕数、评论数、收藏数、投币数、点赞数。
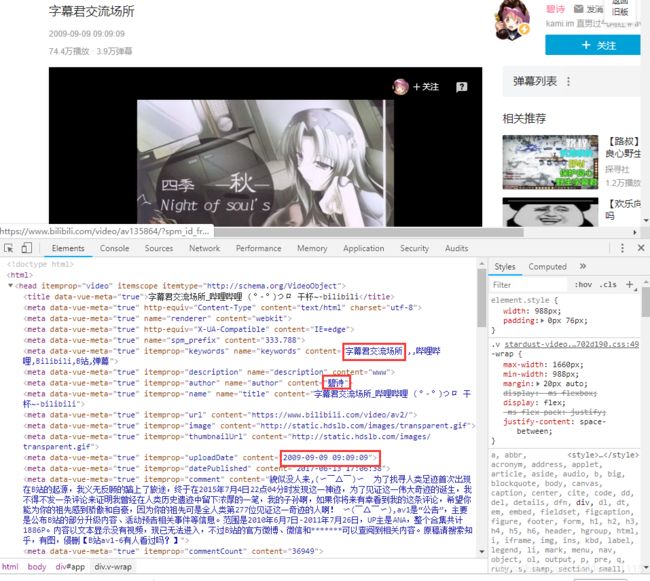

看起来很简单嘛,需要的内容都可以从网页源代码获取,简单的正则处理就好了。。。然而事实是这样吗?
import urllib.request
response = urllib.request.urlopen("https://www.bilibili.com/video/av2/")
print(response.info())
print(response.read())
response.close()
在运行过后,403 错误,服务器拒绝了我们的访问。
运行结果
HTTPError: HTTP Error 403: Forbidden
这是我们本次爬虫遇到的第一个坑。在浏览器中能正常返回响应,但是直接打开请求链接时,却会被服务器拒绝。
第一反应是,静态爬取方式不行,就用动态的爬取方式吧,找它的js加载。
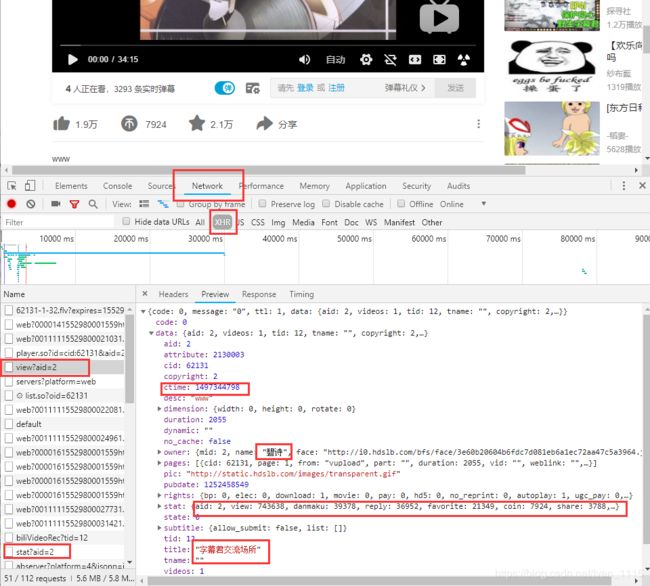
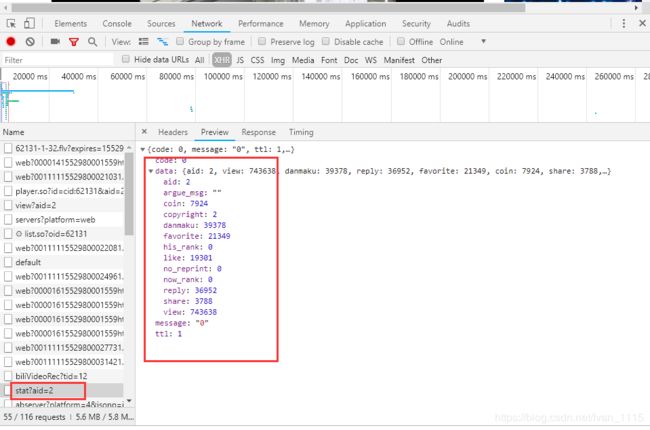
OK,我们需要的数据都在这了,view?aid还包括了视频的标题,作者,视频类型等,就决定是你了。(注意视频的审核通过时间ctime在源代码处为Unix时间戳,后续须做格式转换)
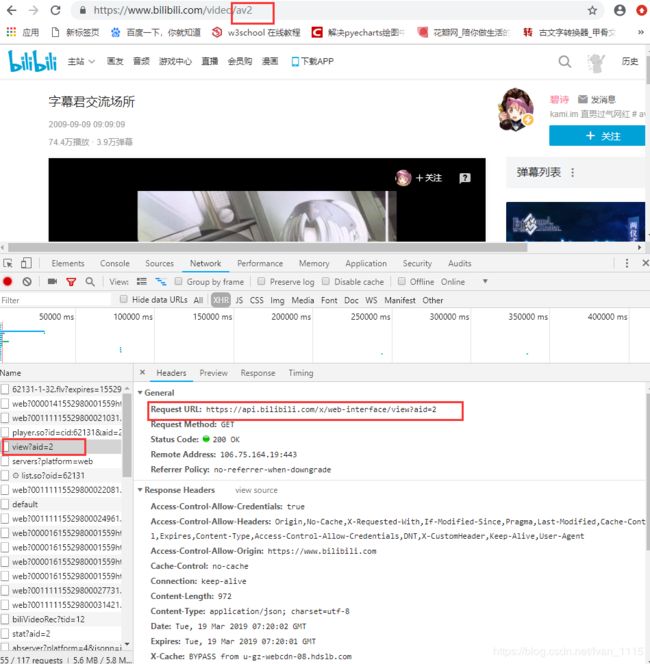
获取它的URL,很明显的是https://api.bilibili.com/x/web-interface/view?aid=2,通过多个视频网页对比分析,’2‘为每个视频的av号。
测试下能否获取
import urllib.request
response = urllib.request.urlopen("https://api.bilibili.com/x/web-interface/view?aid=2")
print(response.info())
print(response.read())
response.close()
运行结果

OK,网页分析测试到这里,开始正式开工。
数据爬取
导入库
import urllib.request
import random
import time
import json
import openpyxl
构造请求头
def requests_headers(): #构造请求头池
head_connection = ['Keep-Alive','close']
head_accept = ['text/html,application/xhtml+xml,*/*']
head_accept_language = ['zh-CN,fr-FR;q=0.5','en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3']
head_user_agent = ['Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
header = {
'Connection':head_connection[random.randrange(0,len(head_connection))],
'Accept':head_accept[0],
'Accept-Language':head_accept_language[random.randrange(0,len(head_accept_language))],
'User-Agent':head_user_agent[random.randrange(0,len(head_user_agent))],
} #获得随机请求头
return header
设定代理IP
应为有IP访问限制,基本上是1分钟150次以下不会封IP,封闭IP一次为5分钟,所以考虑用代理IP,下面IP都是网上获取的。
#代理IP池
proxies = ['125.66.217.114:6675','112.251.161.82:6675',
'117.34.253.157:6675','113.94.72.209:6666',
'114.105.217.144:6673','125.92.110.80:6675',
'112.235.126.55:6675','14.148.99.188:6675',
'112.240.161.20:6668','122.82.160.148:6675',
'175.30.224.66:6675']
#抽取IP池IP,构建opener
def request_proxie():
header1 = requests_headers () # 获得随机请求头
proxie_handler = urllib.request.ProxyHandler({'http':random.choice(proxies)})
opener = urllib.request.build_opener(proxie_handler)
header = []
for key,value in header1.items():
elem = (key,value)
header.append(elem)
opener.addheaders = header
return opener
数据获取
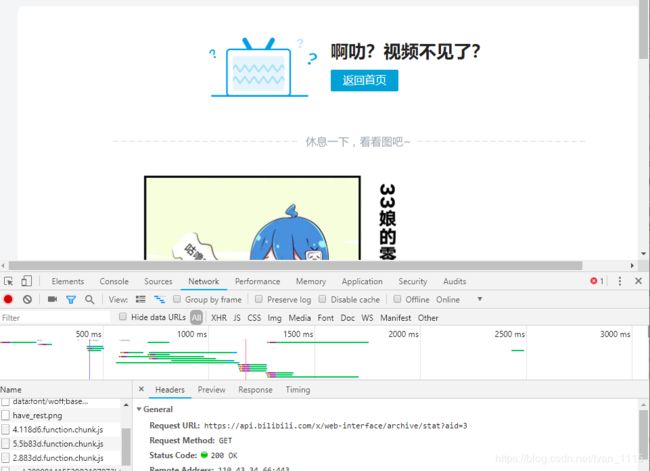
部分视频被封,没有访问权限,或者还没有用到该av号,
针对这部分视频做个测试访问其view?aid看能获得什么
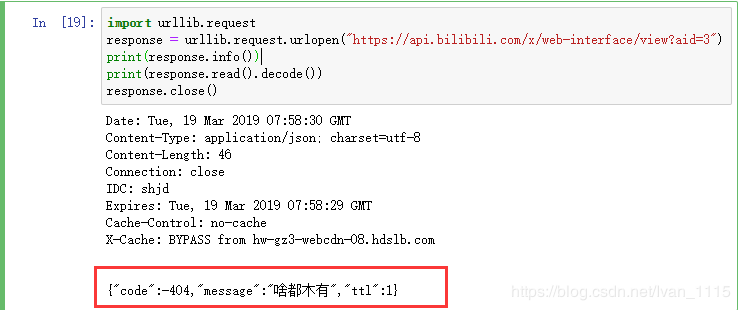
对于能访问的视频获取的内容:
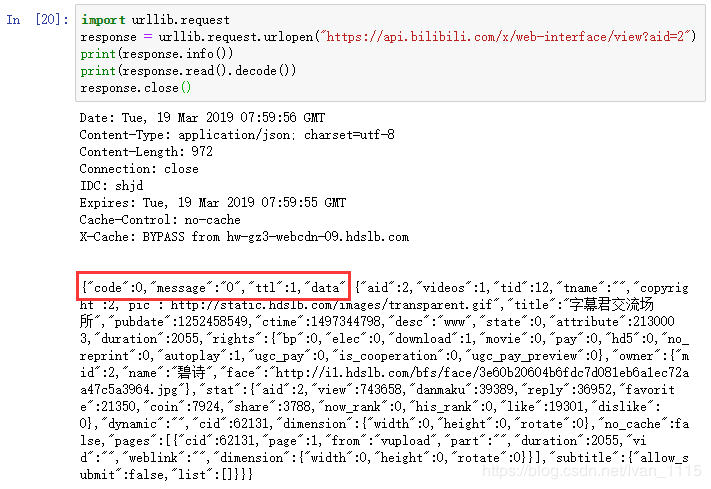
对比可以发现,两者的code的数据不同,通过多个视频比较,能访问的视频code的参数均为0。
| code参数 | 含义 |
|---|---|
| 0 | 可以访问 |
| -404 | 稿件不存在 |
| -403 | 访问权限不足 |
| 62002 | 稿件不可见 |
通过分析,我们可以通过使用If判断其code参数,对其异常权限的视频,只获取其av号,异常原因,和参数
#获取b站单个视频网页内容
def getHtmlInfo(av_num):
opener = request_proxie()
req_view= opener.open("https://api.bilibili.com/x/web-interface/view?aid="+str(av_num))
page_view = req_view.read().decode('utf-8')
dic_page = json.loads ( page_view ) # 将获取内容转成字典形式
if dic_page['code'] != 0:#判断视频是否存在,不存在返回av号及错误原因
video_data=[av_num,dic_page['message'],dic_page['code'],'','','','','','','']
else:
"""
依次获取视频av号、视频标题、视频类型、上传时间、作者(UP主)、弹幕数、评论数、收藏数、投币数、点赞数
"""
video_info = dic_page['data']
video_data = [video_info['aid'],#av号
video_info['title'],#标题
video_info['tname'],#视频类型
time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(video_info['ctime'])),#上传时间,网页获取时间为Unix时间戳,转换成一般时间显示模式
video_info['owner']['name'],#作者
video_info['stat']['danmaku'],#弹幕数
video_info['stat']['reply'],#评论数
video_info['stat']['favorite'],#收藏数
video_info['stat']['coin'],#投币数
video_info['stat']['like']#点赞数
]
time.sleep(2+random.randint(-1,2))
print("爬取av"+str(av_num)+'已完成') #提示爬取进度
req_view.close ()
通过传入参数的形式,设定需要爬取的视频av号范围,方便做分布式爬取,一次爬取太多太久,怕断网。。。。。
def getAllInfo(start_Num,end_Num):
allinfo = []
for av_num in range(start_Num,end_Num+1):
allinfo.append(getHtmlInfo(av_num))
return allinfo
将获取内容写入excell文档
#将获取内容写入excell文档
def savetoExcell(start_Num,end_Num):
allinfo = getAllInfo(start_Num,end_Num)
wb = openpyxl.Workbook()
sheet1 = wb.create_sheet('bilibili视频信息爬取',0)
title_ls = ['av号','视频标题','视频类型','上传时间','作者(UP主)','弹幕数','评论数','收藏数','投币数','点赞数']
for i in range(len(title_ls)):#循环写入标题
sheet1.cell(1,1+i).value = title_ls[i]
for row in range(len(allinfo)): #嵌套循环写入视频信息
print ( '真正写入av' + str ( allinfo[0][0] + row ) ) #提示写入进度
for column in range(len(allinfo[row])):
sheet1.cell(row+2,column+1).value = allinfo[row][column]
wb.save('./bilibili_data'+'_'+start_Num+'_'+end_Num+'.xlsx')
wb.close()
爬取数据部分展示
大功告成,就差做数据分析啦。
免责申明
本爬虫只用于个人学习,切勿用于其他用途,否则出现一切问题作者概不负责.
如有对贵公司造成损失请联系我进行删除