hive的HiveServer2/beeline配置及使用
第一:修改 hadoop 集群的 hdfs-site.xml 配置文件:加入一条配置信息,表示启用 webhdfs
第二:修改 hadoop 集群的 core-site.xml 配置文件:加入两条配置信息:表示设置 hadoop的代理用户
最后发送修改的文件给别的节点:
[hadoop@hadoop05 hadoop]$ scp -r hdfs-site.xml hadoop02:$PWD
[hadoop@hadoop05 hadoop]$ scp -r hdfs-site.xml hadoop03:$PWD
[hadoop@hadoop05 hadoop]$ scp -r hdfs-site.xml hadoop04:$PWD
[hadoop@hadoop05 hadoop]$ scp -r core-site.xml hadoop02:$PWD
[hadoop@hadoop05 hadoop]$ scp -r core-site.xml hadoop03:$PWD
[hadoop@hadoop05 hadoop]$ scp -r core-site.xml hadoop04:$PWD
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
以上操作做好了之后,请继续做如下
---------------------------------------------------------------------------------------------------------------------
启动为前台:
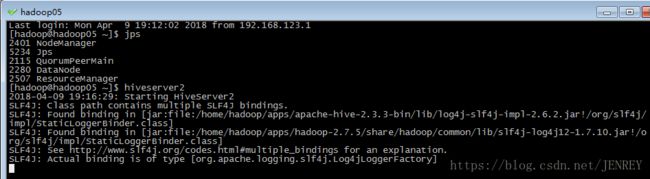
第一步:先启动 hiveserver2 服务
(我的hive装在hadoop05上所以在05输入hiveserver2命令):
启动为前台:(窗口不能关不能动,只能在复制一个hadoop05的窗口)
运行 hiveserver2 命令,如下图,不要管
然后再克隆一个hadoop05窗口
使用jps查看进程
第二步:启动 beeline客户端
在克隆的窗口输出 beeline 命令,进入到beeline客户端,然后输入
beeline> !connect jdbc:hive2://hadoop05:10000
!connect jdbc:hive2:// 这是固定的,后面的是hive客户端服务在哪个节点上(我的hive装在hadoop05),端口号10000
输入hadoop05节点的用户名
Enter username for jdbc:hive2://hadoop05:10000: hadoop
输入hadoop05节点的密码
---------------------------------------------------------------------------------------------------------------------
启动为后台:
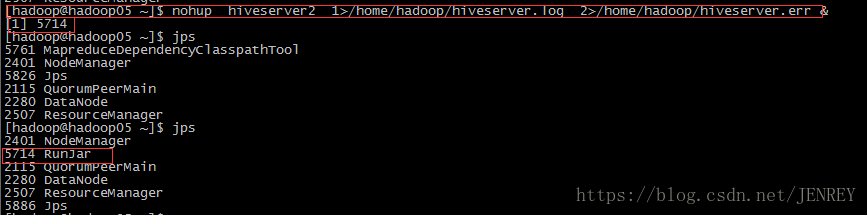
第一步:先启动 hiveserver2 服务
nohup hiveserver2 1>/home/hadoop/hiveserver.log 2>/home/hadoop/hiveserver.err &
或者:nohup hiveserver2 1>/dev/null 2>/dev/null &
或者:nohup hiveserver2 >/dev/null 2>&1 &
以上 3 个命令是等价的,第一个表示记录日志,第二个和第三个表示不记录日志
命令中的 1 和 2 的意义分别是:
1:表示标准日志输出
2:表示错误日志输出
如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做:nohup.xxx
第二步:启动 beeline客户端
执行命令:beeline -u jdbc:hive2://hadoop05:10000 -n hadoop
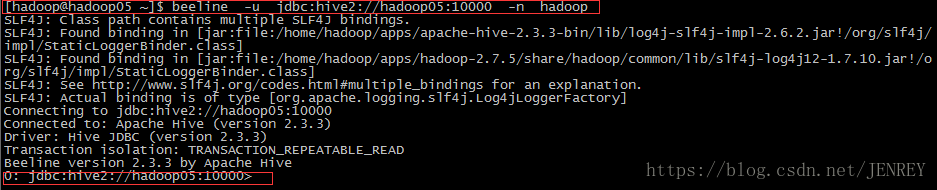
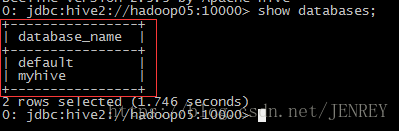
另外还有一种方式也可以去连接:先执行 beeline
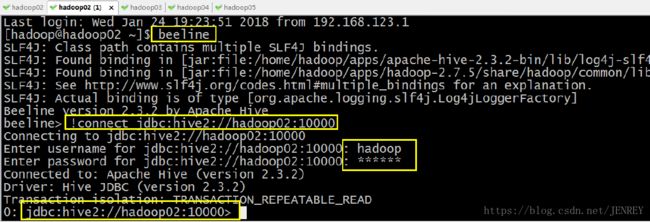
然后按图所示输入:!connect jdbc:hive2://hadoop02:10000 按回车,然后输入用户名,这个用户名就是安装 hadoop 集群的用户名,(图应该是hadoop05,因为我hive装在05)
最后进入客户端就是为了方便的看到下图的效果,横竖对其的。
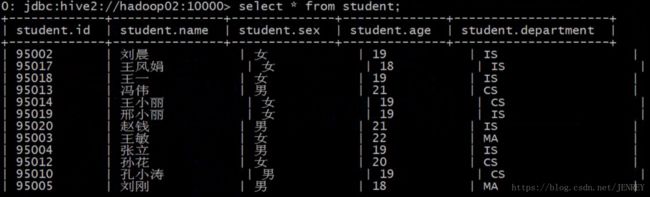
如果发现beeline连接不上,可能是spark版本出了问题,需要在hive的元数据库中(mysql)修改一下spark的版本号