SSD目标检测
SSD (Single Shot MultiBox Detector)
这是一个one-stage的多框预测的方法。
1 网络结构

YOLO和Faster RCNN都是在检测的时候只用到了最高层的feature maps。
ssd提取了不同尺度的特征图来做预测。在多个feature maps上同时进行softmax分类和位置回归。
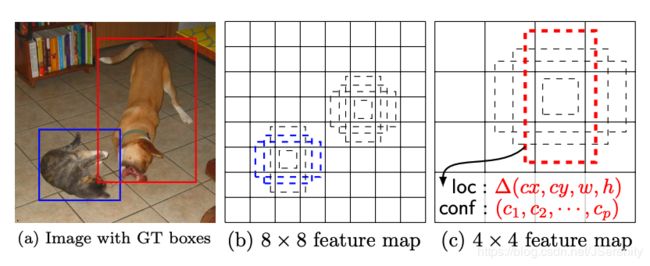
SSD采用了不同尺度和长宽比的先验框。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。如图所示,在8x8的feature map中,蓝框可以匹配到较小的猫,而无法匹配到较大的狗。在4x4的feature map中,红框可以匹配到较大的狗,无法匹配到较小的猫。
相比yolo在最后使用全连接层做预测。ssd直接用CNN预测。
2 Default Box
先验框=预选框=Default Box=Prior Box=Anchor box
Default Box类似于Faster R-CNN的anchor box,为目标的预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。Default Box与anchor box不同的是,SSD为每一个不同尺度的feature map分别设置了预选框以更有效的检测到目标。
为了降低复杂度,SSD采用手动选择预选框的形状。SSD为每一个feature map分别设置了预选框。假设我们想要使用m个feature maps去预测。
Default Box的宽和高通过以下公式计算出:
w = s k ⋅ a r w = s_k \cdot \sqrt{a_r} w=sk⋅ar
h = s k a r h = \frac {s_k} {\sqrt{a_r}} h=arsk
a r a_r ar为aspect ratio a r ∈ { 1 , 2 , 3 , 1 2 , 1 3 } a_r ∈ \{1, 2, 3, {1\over2}, {1\over3}\} ar∈{1,2,3,21,31} s k s_k sk为scale
Default Box的scale这样计算:
s k = s m i n + s m a x − s m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] s_k = s_{min} + \frac{s_{max} − s_{min}} {m − 1} (k − 1), k ∈ [1, m] sk=smin+m−1smax−smin(k−1),k∈[1,m]
s m i n s_{min} smin为0.2, s m a x s_{max} smax为0.9。所以每个layer的scale从0.2到0.9均匀增加。
对于 a r a_r ar等于1的情况,再额外添加一个Default Box,它的scale为 s r ′ = s k s k + 1 s^{'}_r = \sqrt{s_ks_{k+1}} sr′=sksk+1。这样feature map的每个格子产生六个default boxes。
我们设置每个default box的中心坐标为 ( i + 0.5 ∣ f k ∣ , j + 0.5 ∣ f k ∣ ) \left(\frac{i+0.5}{|f_k|}, \frac{j+0.5}{|f_k|}\right) (∣fk∣i+0.5,∣fk∣j+0.5), ∣ f k ∣ |f_k| ∣fk∣为第 k k k个feature map, i , j ∈ [ 0 , ∣ f k ∣ ] i, j ∈ [0, |f_k|] i,j∈[0,∣fk∣]。
default box的数量应该是4到6个。一个博客上面写道实际设定和论文不符,所以这里没有太清楚。
而且下面的具体实现里使用的是min_size和max_size。

对于conv4-3:k = 1, min_size = s1 * 300, max_size = s2 * 300
以下为SSD300的conv4_3_norm_priorbox层prototxt的定义
layer {
name: "conv4_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv4_3_norm"
bottom: "data"
top: "conv4_3_norm_mbox_priorbox"
prior_box_param {
min_size: 30.0
max_size: 60.0
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 8
offset: 0.5
}
}
3 SSD如何预测

这里以第一个feature map预测为例,分为两步:
-
首先提取feature maps
-
然后,使用卷积预测目标。
得到第一个feature map后,我们看一下通过第一个feature map进行预测,在Conv4_3 layer上做的预测。在38x38的feature map上,每一格都设4个预选框。使用一个3x3的卷积核对feature map进行卷积。卷积计算结果为21个类别(20和物体类别+背景)和4个位置信息 Δ ( c x , c y , w , h ) \Delta(cx, cy, w, h) Δ(cx,cy,w,h)。
所以计算过程为: ( 38 × 38 × 512 ) ⟶ ( 4 × 3 × 3 × 512 × ( 21 + 4 ) ) ( 38 × 38 × ( 4 × ( 21 + 4 ) ) ) (38 \times 38 \times 512) \stackrel{(4\times3\times3\times512\times(21+4))}\longrightarrow (38 \times 38 \times (4 \times (21 + 4 ))) (38×38×512)⟶(4×3×3×512×(21+4))(38×38×(4×(21+4)))
4 Matching strategy
SSD将预测分为正匹配和负匹配。SSD只使用正匹配来计算位置误差。如果预选框和GT的iou超过0.5的时候为正匹配,否者为负匹配。
5 Loss Function
总损失函数为:

数字N为正匹配的default boxes的数量。如果N=0,就让loss等于0。location loss是预测框(l)和GT(g)参数之间的Smooth L1 loss。权重系数 α \alpha α默认为1。

置信度损失采用softmax loss。

6 数据增强
- 使用原图像
- 采样patch with IoU of 0.1, 0.3, 0.5, 0.7 or 0.9
- 随机采样patch
采样的patch的大小占原始图像大小比例在[0.1, 1]之间,aspect ratio在1/2到2之间。
We keep the overlapped part of the ground truth box if the center of
it is in the sampled patch. 如果GT的中心在采样中的话,我们就保留GT重叠的部分。不是很懂什么意思。
在采样之后,每个采样都被resize到固定的大小,然后有0.5的概率被水平翻转。
另外对图像进行扭曲。(photo distortions)
7 总结
SSD是一个one-stage的多框预测的方法。它没有使用RPN,而是直接通过卷积从feature map预测边框和类别。
未使用RPN再加上使用低分辨率的图像,使他可以实现在实时检测的同时,在精度上依然超过Faster R-CNN。
特点:
- 使用小卷积核来完成目标类别和边框的检测。
- 不同长宽比的预选框以使用不同的目标。
- 多尺度的feature maps。
缺点:
- default box需要人工设置。
- 对小目标的检测方面没有好过Faster R-CNN。因为靠左边的feature map中包含的是低级别的特征,如边缘或颜色块。这些信息对分类不是充足。
Tricks:
- 可以通过增加default box的数量来增加精度,但同时牺牲了速度。
- 设计更好的default box可以对提高精度有帮助。
- COCO数据集包含很多小物体。可以通过设置小一点的default boxes来提高精度。例如,将 s m i n s_{min} smin设为0.15。
- SSD比R-CNN有着更低的位置误差和更高的分类误差。
参考:
Paper: https://arxiv.org/pdf/1512.02325.pdf
https://zhuanlan.zhihu.com/p/33544892
https://zhuanlan.zhihu.com/p/31427288
https://medium.com/@jonathan_hui/ssd-object-detection-single-shot-multibox-detector-for-real-time-processing-9bd8deac0e06