使用PyTorch实现resnet-18分类CIFAR-10
昨天看完了resnet的论文,今天试着来实现一下。
先放一个resnet18的模型图:
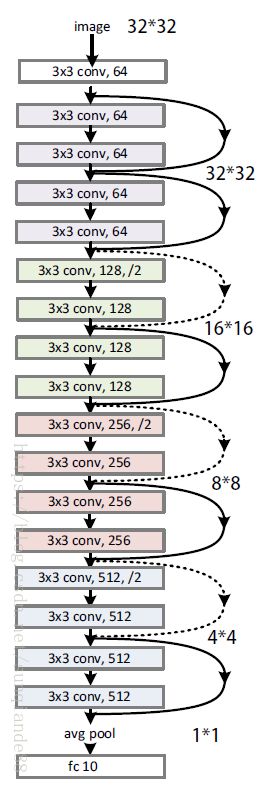
模块引入
# 模块引入
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
数据导入
# 数据导入
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,
download=True,transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,
shuffle=True,num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data',train=False,
download=True,transform=transform)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,
shuffle=False,num_workers=2)
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
class_nums = 10
定义block类
正式准备开始写模型后遇到的第一个问题就是如何表示short connection,一个最直观的想法是,手动编写每一层,然后注意保存输入x,在适当的时候把它进行处理,然后加到输出里。
这个方法实现起来很简单,但它有三个问题:
- 如果要对网络进行修改,会比较麻烦。
- 18层的resnet这样写是可行的,但是论文中提到了有搭建1000层的resnet,如果这样写的话,1000层写起来就太麻烦了。
- 这样写不能体现出resnet的block思想。
出于对以上问题的考虑,我开始设想把block封装起来。封装是很简单的,但是如何使用别的类来调用它,这就超过我的能力范围了。于是我上网找了几篇实现的方法,并用它们写了block和resnet两个类。
# 定义block类
class block(nn.Module):
def __init__(self,insize,outsize,stride=1):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(insize,outsize,kernel_size=3,stride=stride,padding=1,bias=False),
nn.BatchNorm2d(outsize),
nn.ReLU(inplace=True),
nn.Conv2d(outsize,outsize,kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(outsize)
)
# 如果输入和输出的大小不匹配,就要对输入进行处理以便于二者相加
if stride != 1 or insize != outsize:
self.short = nn.Sequential(
nn.Conv2d(insize,outsize,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(outsize)
)
else:
self.short = nn.Sequential()
def forward(self,x):
out = self.net(x)
out += self.short(x)
out = F.relu(out)
return out
定义resnet类
# 定义resnet
class resnet(nn.Module):
def __init__(self,block):
super().__init__()
self.insize = 64
self.conv = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,padding=1,stride=1,bias=False),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.layer1 = self.init_layer(block,64,block_nums=2,stride=1)
self.layer2 = self.init_layer(block,128,block_nums=2,stride=2)
self.layer3 = self.init_layer(block,256,block_nums=2,stride=2)
self.layer4 = self.init_layer(block,512,block_nums=2,stride=2)
self.fc = nn.Linear(512,class_nums)
def init_layer(self,block,size,block_nums,stride):
layers = []
for i in range(block_nums) :
if i == 0:
layers.append(block(self.insize,size,stride))
else:
layers.append(block(size,size,1))
self.insize = size
return nn.Sequential(*layers)
def forward(self,x):
out = self.conv(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out,4)
out = out.view(out.size(0),-1)
out = self.fc(out)
return out
定义精确度函数
# 定义准确度函数
def show_accuracy(epoch,testloader,net,device):
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
inputs,labels = data
inputs,labels = inputs.to(device),labels.to(device)
outputs = net(inputs)
_,pred = torch.max(outputs.data,1)
total += labels.size(0)
correct += (pred == labels).sum().item()
accuracy = correct / total
print("eprch {}---准确度为:{}".format(epoch,accuracy))
定义拟合函数
# 定义拟合函数
def fit(epochs,net,criterion,trainloader,testloader,device):
momentum = 0.9
for epoch in range(epochs):
net.train()
if epoch <= 135:
lr = 0.1
elif epoch <= 185 :
lr = 0.01
else :
lr = 0.001
opt = optim.SGD(net.parameters(),lr=lr,momentum=momentum,weight_decay=5e-4)
print("start train {}".format(epoch))
for i,data in enumerate(trainloader,0):
xb,yb = data
xb,yb = xb.to(device),yb.to(device)
opt.zero_grad()
pred = net(xb)
loss = criterion(pred,yb)
loss.backward()
opt.step()
show_accuracy(epoch,testloader,net,device)
print("finished")
定义模型
# 定义模型
def get_model(device):
net = resnet(block).to(device)
criterion = nn.CrossEntropyLoss()
return net,criterion
main函数
# main函数
epochs = 240
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {}...".format(device))
net,criterion = get_model(device)
fit(epochs,net,criterion,trainloader,testloader,device)
第一次跑了5个epoch试试水,大概10分钟能跑一个epoch,最后结果是
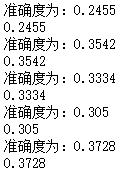
第二遍结果为:

因为第一遍只为跑起来,弄得比较粗糙,估计准确率是不会高了,所以我从resnet的论文和网上的各种文章里寻找它们优化的方式,并进行改动如下:
# 数据导入
transform_train = transforms.Compose([
# 这里是论文的操作,根据cs231n的介绍,这样可以提高精度
transforms.RandomCrop(32,padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# 这里据介绍是RGB每层用到的归一化均值和方差,但我觉得这应该不影响分类精度
transforms.Normalize((0.4914,0.4822,0.4465),(0.2023,0.1994,0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914,0.4822,0.4465),(0.2023,0.1994,0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,
download=True,transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,
shuffle=True,num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data',train=False,
download=True,transform=transform_test)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,
shuffle=False,num_workers=2)
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
class_nums = 10
然后是增加了epoch的数量。其实一开始训练完我还挺怀疑人生的,为什么看别人训练精度都90+,只有我的才30+,思考了一会后才意识到可能是epoch太少了:
# 论文里介绍为了提高精度,每隔一些epoch就要把lr除以10
if epoch <= 135:
lr = 0.1
elif epoch <= 185 :
lr = 0.01
else :
lr = 0.001
论文里提到,它没有使用dropout,这是个提醒,我决定明天用dropout试试,然后再从cs231n里找找有没有什么能提高精度的方法。