Scrapy 框架爬虫知识、爬虫实战教程
GitHub Python库 GitHub 爬虫库 官方教程 豆瓣电影爬虫案例
1、scrapy
Scrapy 是一个为了抓取网页数据、提取结构性数据而编写的应用框架,该框架是封装的,包含 request (异步调度和处理)、下载器(多线程的 Downloader)、解析器(selector)和 twisted(异步处理)等。对于网站的内容爬取,其速度非常快捷。

涉及技术应用:Scrapy、Xpath、css选择器、正则表达式(Python re 库)
2、 爬虫入门实战
目标:爬取https://www.cnblogs.com/文章
- 创建Scrapy项目
scrapy startproject cnblog- 编写item文件,根据需要爬取的内容定义爬取字段
class CnblogItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
name = scrapy.Field()
- 编写spider文件 、使用命令创建一个基础爬虫类
scrapy genspider cnblogJob "cnblog.com"编辑爬虫
# -*- coding: utf-8 -*-
import scrapy
from cnblog.items import CnblogItem
class CnblogjobSpider(scrapy.Spider):
name = 'cnblogJob'
allowed_domains = ['cnblog.com']
start_urls = ['https://www.cnblogs.com/']
def parse(self, response):
item = CnblogItem()
item['title'] = response.xpath('//a[@class="titlelnk"]/text()').extract()
item['link'] = response.xpath('//a[@class="titlelnk"]/@href').extract()
item['name'] = response.xpath('//div[@class="post_item_foot"]/a/text()').extract()
yield item- 编写pipelines文件
class FilePipeline(object):
def process_item(self, item, spider):
data = ''
with open('cnblog.txt', 'w', encoding='utf-8') as f:
titles = item['title']
links = item['link']
name = item['name']
for i, j, k in zip(titles, links, name):
data += '用户名:' + k + ' <> ' + i + ':' + j + '\n'
f.write(data)
f.close()
return item- settings文件设置(主要设置内容)
BOT_NAME = 'cnblog'
SPIDER_MODULES = ['cnblog.spiders']
NEWSPIDER_MODULE = 'cnblog.spiders'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
#user-agent新添加
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
#新修改
ITEM_PIPELINES = {
'cnblog.pipelines.FilePipeline': 300, #实现保存到txt文件
}- 执行命令,运行程序
scrapy crawl cnblogJob

3、知识深入
3.1、Scrapy各个组件介绍
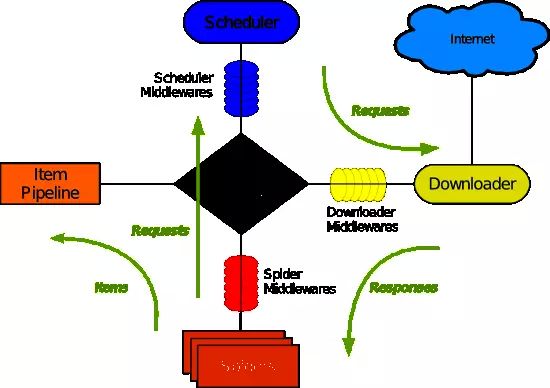
Scrapy Engine:
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。它也是程序的入口,可以通过scrapy指令方式在命令行启动,或普通编程方式实例化后调用start方法启动。
调度器(Scheduler)
调度器从引擎接收爬取请求(Request)并将它们入队,以便之后引擎请求它们时提供给引擎。一般来说,我们并不需要直接对调度器进行编程,它是由Scrapy主进程进行自动控制的。
下载器(Down-loader)
下载器负责获取页面数据并提供给引擎,而后将网站的响应结果对象提供给蜘蛛(Spider)。具体点说,下载器负责处理产生最终发出的请求对象 Request 并将返回的响应生成 Response对象传递给蜘蛛。
蜘蛛——Spiders
Spider是用户编写用于分析响应(Response)结果并从中提取Item(即获取的Item)或额外跟进的URL的类。每个Spider负责处理一个特定(或一些)网站。
数据管道——Item Pipeline
Item Pipeline 负责处理被 Spider 提取出来的 Item。 典型的处理有清理、验证及持久化(例如,存取到数据库中)。
下载器中间件(Downloader middle-wares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy的功能。
Spider中间件(Spider middle-wares)
Spider 中间件是在引擎及 Spider 之间的特定钩子(specific hook),处理 Spider 的输入(Response)和输出(Items及Requests)。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy的功能。
4、爬虫进阶实战
- 分页爬虫
- 禁止重定向、反爬
5、知识总结
- 通过网络向指定的 URL 发送请求,获取服务器响应内容。
- 使用某种技术(如正则表达式、XPath 等)提取页面中我们感兴趣的信息。
- 高效地识别响应页面中的链接信息;
- 使用多线程有效地管理网络通信交互。