Python抓取妹子图
前言
如果你对python爬虫感兴趣,不妨试一下python语言的魅力。
学习一门新的语言怎么样才有动力呢,我比较喜欢妹子,如果在我python入门后,想学习下python爬虫技术,对象如果是一个丰富的妹子图网站,这是不是一个增益buff呢 [滑稽]
- 目标网站:妹子图
- python 2.7 如果你用的更高版本,运行出异常,欢迎留言
- 第三方库 requests、Beautiful Soup 4
- 源代码:Github传送门

准备
下载python
在开始前我们需要安装python 2.7 或 python 3.6,前往官网选择对应系统的版本

安装完成后可以在终端下输入
python --version输出 Python 2.7.10 或其他版本说明安装成功了
安装requests库
mac os 安装pip
如果你使用的mac os系统,并且还没安装pip需要提前pip,同样是终端下输入:
sudo easy_install pip
# 省略很多很多,完成后提示下面说明安装成功了
Using /Library/Python/2.7/site-packages/pip-9.0.1-py2.7.egg
Processing dependencies for pip
Finished processing dependencies for pip如有需要可以顺便把
ipython也安装了,关于ipython的好处请跳转
知乎-使用IPython有哪些好处?
sudo pip install ipython
# 省略很多很多,完成后提示下面说明安装成功了
Successfully installed appnope-0.1.0 decorator-4.0.4 gnureadline-6.3.3 ipython-4.0.0 ipython-genutils-0.1.0 path.py-8.1.2 pexpect-4.0.1 pickleshare-0.5 ptyprocess-0.5 simplegeneric-0.8.1 traitlets-4.0.0下面开始安装requests库
pip install requests
# 如出现报红异常,并且有权限英文,请用
sudo pip install requests
# 安装完成后,终端下输出,如果没有报错说明安装成功了
python
import requests
# 或者你在终端下输出,显示所有已安装库
pip list
安装Beautiful Soup 4库
pip install beautifulsoup4
# 安装完成后,终端下输出,如果没有报错说明安装成功了
python
from bs4 import BeautifulSoup抓取数据
引入第三方库
import os, re, sys
import requests
from bs4 import BeautifulSoup说明:
- os 其他操作系统接口,对文件读写
- re 正则表达式语法,如意
- sys 系统特定的参数和功能,改变编码
爬取指定页面
@staticmethod
def get_beautiful_soup(url):
r = requests.get(url)
if r.status_code == 200:
html = r.content
# print(html)
soup = BeautifulSoup(html, 'html.parser')
# print(soup.prettify)
return souprequests.get(url)获取对象,然后判断code值
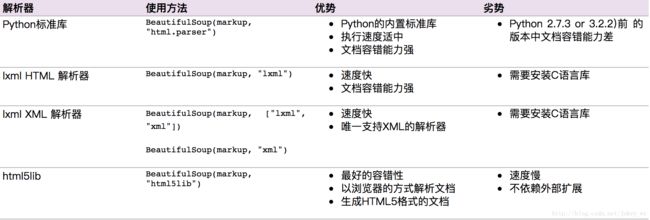
soup = BeautifulSoup(html, 'html.parser')获取BeautifulSoup对象,第一个参数是html值,第二个是指定的
创建文件夹
# 创建文件夹
def createFolder(self, folder_path):
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# print('创建文件目录成功 ' + folder_path)
else:
# print('文件目录已存在 ' + folder_path)
pass
return folder_path抓取数据
# 获取二级目录名称
def get_two_level_directory(self):
soup = self.get_beautiful_soup(self.site_url)
item = soup.find_all('div', class_='subnav')[0]
all_string = item.find('span').string
# 声明一个数组保存文件目录路径,创建名称为 all_folder 的文件目录
folders = [all_string]
hrefs = [self.site_url]
all_a = item.find_all('a')
for a in all_a:
folders.append(a.string)
hrefs.append(a.get('href'))
return folders, hrefs
# 获取三级目录
def get_three_level_directory(self, url_path):
soup = self.get_beautiful_soup(url_path)
items = soup.find_all('div', class_='pic')[0].find('ul').find_all('li')
# 声明一个数组保存文件目录路径
folders3 = []
hrefs3 = []
for item in items:
title = item.find('a').find('img').get('alt')
href_url = item.find('a').get('href')
folders3.append(title)
hrefs3.append(href_url)
return folders3, hrefs3获取页码
# 获取总页码
def get_page(self, url):
soup = self.get_beautiful_soup(url)
a_list = soup.find_all('div', class_='page')[0].find_all('a')
max_page = 1
for a in a_list:
# 获取到`a标签`中的值,然后通过正则判断是否为整型,返回一个list集合
pages = re.findall('\d+', a.string)
# 因为pages集合里数据编码格式为utf-8,这里将它转换成整型(我在输出pages时,值为 u'36' 等这样的数据,所以把集合强制转换成了int类型)
pages = [int(pages) for pages in pages if pages]
# 查找到最大值,之前用 max(pages)报错了,,
for page in pages:
max_page = max(max_page, page)
return max_page抓取图片地址
# 抓取图片地址
def get_crawl_data(self, url, max_page, folder_path3):
for i in range(max_page + 1):
site_url = url + '/' + str(i)
soup = self.get_beautiful_soup(site_url)
item = soup.find_all('div', class_='content')[0].find('a').find('img')
title = item.get('alt')
pic_url = item.get('src')
folder_path = folder_path3 + title + '.jpg'
# print('{0} {1}'.format(pic_url, folder_path))
self.download_pic(pic_url, folder_path)根据图片url保存到本地目录
# 保存图片到本地
@staticmethod
def download_pic(pic_url, pic_path):
headers = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Referer': "http://www.mmjpg.com"
}
try:
# 设置绝对路径,文件夹路径 + 图片路径
if os.path.isfile(pic_path):
print('该图片已存在 ' + pic_path)
return
print('文件路径:' + pic_path + ' 图片地址:' + pic_url)
try:
img = requests.get(pic_url, headers=headers, timeout=10)
with open(pic_path, 'ab') as f:
f.write(img.content)
print(pic_path)
except Exception as e:
print(e)
print "保存图片完成"
except Exception, e:
print e
print "保存图片失败: " + pic_url唯一注意的是18、19、20行
# with 从某种意义上等同
img = requests.get(pic_url, headers=headers, timeout=10)
f = open(pic_path, 'ab')
data = f.write(img.content)
f.close()open(pic_path, 'ab')
第一个参数是存储的绝对路径,第二是文件模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:
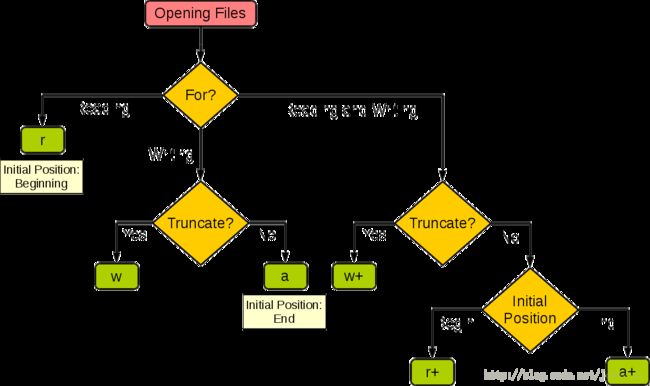
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
引用:结构图和表格来自该网站
源代码:Github传送门