利用Docker搭建大数据处理集群
转自:http://blog.csdn.net/iigeoxiaoyang/article/details/53020066
所需安装包已放入百度网盘,链接:https://pan.baidu.com/s/1i5tCWjN
在开始正文之前,需要掌握以下基础知识:
- Linux基础知识(推荐《鸟哥的Linux私房菜》,我早年看的时候是第三版,现在已经有了新版本);
- Doceker镜像,容器和仓库的概念(推荐《Docker — 从入门到实践》);
- Hadoop的基础概念和原理;
在Centos7上搭建数据分析集群过程包括:
- 在Cnetos7上安装Docker并创建Hadoop镜像和三节点容器
- 在Docker上配置三节点Hdfs集群
- 在Docker上配置三节点Yarn集群
- 在Docker上配置三节点Spark集群
(一)安装Docker与创建Hadoop镜像和三节点容器
1.1 安装Dcoker
本文在Cnetos7系统上安装Docker,安装Docker对于Linux系统的要求是
64 位操作系统,内核版本至少为 3.10。
1.1.1 安装Docker
- 1
- 1
1.1.2 配置Docker加速器和开机启动服务
这里需要注册一个阿里云账号,每个账号有自己专属的加速器,专属加速器的地址,根据自己的地址配。

- 1
- 2
- 3
- 1
- 2
- 3
1.2 在Docker上创建Hadoop镜像
1.2.1 从Docker Hub官网仓库上获取centos镜像库
- 1
- 2
- 3
- 1
- 2
- 3
1.2.2 生成带有SSH功能的centos的镜像文件
为了后面配置各节点之间的SSH免密码登陆,需要在pull下的centos镜像库种安装SSH,
这里利用 Dockerfile 文件来创建镜像
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1.2.3 根据上面的Dockerfile生成centos7-ssh镜像
- 1
- 2
- 3
- 1
- 2
- 3
1.2.4 生成Hadoop镜像库文件
在构建Hadoop镜像库的Dockerfile所在目录下,上传已经下载的 jdk-8u101-linux-x64.tar.gz, hadoop-2.7.3.tar.gz,Scala-2.11.8.tgz,spark-2.0.1-bin-hadoop2.7.tgz。
注意:这里要提前在Dockerfile文件配置环境变量,如果镜像库构建完成后,在
容器中配置环境变量是不起作用的。
cd /usr/local
# 创建一个存放hadoop镜像Dockerfile文件的目录
mkdir DockerImagesFiles/hadoop
#创建带ssh的centos的Dockerfile 文件
vi Dockerfile
# Dockerfile文件内容
#基于centos7-ssh构建
FROM centos7-ssh
#安装java
ADD jdk-8u101-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_101 /usr/local/jdk1.8
#配置JAVA环境变量
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
#安装hadoop
ADD hadoop-2.7.3.tar.gz /usr/local
RUN mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
#配置hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
#安装scala 注意Spark2.0.1对于Scala的版本要求是2.11.x
ADD scala-2.11.8.tgz /usr/local
RUN mv /usr/local/scala-2.11.8 /usr/local/scala2.11.8
#配置scala环境变量
ENV SCALA_HOME /usr/local/scala
ENV PATH $SCALA_HOME/bin:$PATH
#安装spark
ADD spark-2.0.1-bin-hadoop2.7.tgz /usr/local
RUN mv /usr/local/spark-2.0.1-bin-hadoop2.7.tgz /usr/local/spark2.0.1
#配置spark环境变量
ENV SPARK_HOME /usr/local/spark2.0.1
ENV PATH $SPARK_HOME/bin:$PATH
#创建hdfs账号
RUN useradd hdfs
RUN echo "hdfs:12345678" | chpasswd
RUN yum install -y which sudo
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
1.2.5 根据上面的Dockerfile构建Hadoop镜像库
- 1
- 2
- 3
- 1
- 2
- 3
1.2.6 生成三节点Hadoop容器集群
1.2.6.1首先规划一下节点的主机名称,IP地址(局域网内构建docker镜像时,自动分配172.17.0.1/16网段的IP)和端口号
master 172.17.0.2
slave01 172.17.0.3
slave02 172.17.0.4
1.2.6.2下面在Hadoop镜像上创建三个容器,做为集群的节点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.2.6.3 查看已创建的容器并更改hadoop和spark2.0.1目录所属用户
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
(二)在Docker上配置三节点Hdfs集群
2.1开启三个容器终端
- 1
- 2
- 3
- 1
- 2
- 3
2.1 配置hdfs账号容器各节点间的SSH免密码登陆
分别进入master,slave01,slave02三个容器节点,执行下面命令
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2 配置hadoop
这里主要配置hdfs,因为我们的计算框架要用spark,所以maprreduce的不需要配置。
进入master容器的hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml
2.2.1 在hadoop-env.sh中配置JAVA_HOME
- 1
- 1
2.2.2 在slaves中配置子节点主机名
进入slaves文件,添加下面名称
- 1
- 2
- 1
- 2
2.2.3 修改core-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2.4 修改hdfs-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.2.5 修改mapred-site.xml
2.2.5.1 复制mapred-site.xml文件
- 1
- 2
- 1
- 2
2.2.5.2 修改mapred-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
2.2.6 修改yarn-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2.2.7 master容器配置的hadoop目录分别分发到slave01,slave02节点
- 1
- 2
- 1
- 2
2.3 启动HDFS集群,验证是否搭建成功
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
浏览器输入http://本机ip地址:50070 ,可以浏览hadoop node管理界面
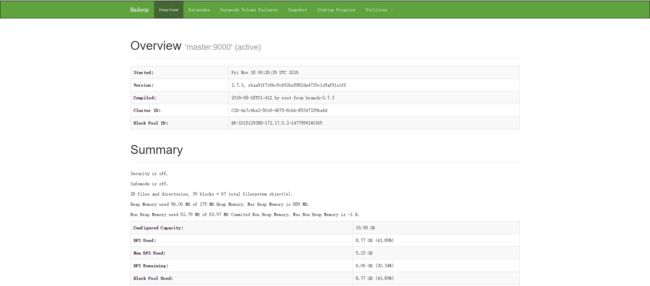
(二)在Docker上配置三节点Yarn集群
上面已经配置成功,直接启动yarn集群
- 1
- 2
- 1
- 2
浏览器输入http://本机ip地址:8088/cluster 可以浏览节点;

(三) 在Docker上配置三节点spark集群
3.1 配置spark
进入master容器的spark配置目录,需要配置有两个文件:spark-env.sh,slaves
3.1.1 配置spark-env.sh
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
在spark-env.sh末尾添加以下内容:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.1.2 在slaves文件下填上slave主机名
- 1
- 2
- 1
- 2
3.1.3 master容器配置的spark目录分别分发到slave01,slave02节点
- 1
- 2
- 1
- 2
3.2 启动spark集群
- 1
- 1
浏览Spark的Web管理页面: http://本机ip地址:8080

总结
本文只是搭建了数据分析的开发环境,作为开发测试使用,距离生成环境的标准还很远。例如容器节点的自动化扩容,容器的CPU内存,调整,有待继续研究。
参考文章
1.https://www.sdk.cn/news/5278 . Docker部署Hadoop集群
2.http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/ .Spark On YARN 集群安装部署
3.http://shinest.cc/static/post/scala/hadoop_cluster_on_docker.md.html . Hadoop Cluster On Docker