一、Mapping的概念
1、Mapping类似于数据库中的Schema的定义,作用如下:
1)定义索引中的字段的名称;
2)定义字段的数据类型,例如字符串、数字、日期、布尔等;
3)对每个字段进行倒排索引的建立及相关配置;
4)Mapping会将Json文档映射成Lucene所需要的扁平格式;
5)一个Mapping属于一个索引的Type,从7.0开始,不需要在Mapping中指定Type信息;
2、字段的数据类型
1)简单类型
Text(会增加Keyword子字段);
Date;
Integer/Long/Floating;
Boolean;
IP4&IP6;
Keyword;
2)复杂类型
对象类型;
嵌套类型;
数组(由第一个非空数值的类型所决定);
空值;
3)特殊类型(地理信息)
geo_point&geo_shape
二、Dynamic Mapping的概念
1、在写入文档的时候,如果索引不存在,则会自动创建索引;
2、由于上述机制,可以无需手动定义Mapping,ElasticSearch会自动根据文档信息,推算出字段的类型;
3、但是有时候推算的可能不对,当类型设置的不对时,会导致一些功能无法正常运行,比如范围内的Range查询;
三、Mapping与Dynamic Mapping的使用
1、推断字段的类型
//创建一个文档
put mapping_test/_doc/1
{
"id":"100",
"isvip":false,
"isadmin":"true",
"age":18,
"height":180
}
//查看索引Mapping结构
get mapping_test/_mapping
//删除索引
delete mapping_test
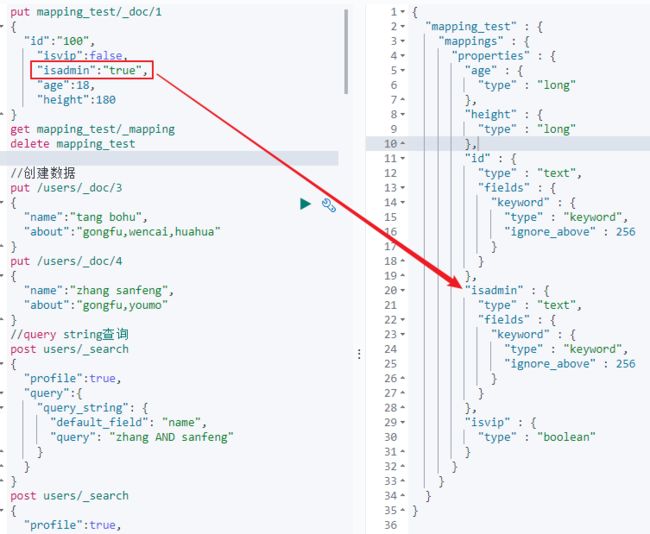
由上图中可以得出,ElasticSearch基本上可以按照数据推断出预想的字段类型,由于isadmin字段的值是由双引号所括起来的,所以该字段被推断成text类型。
2、更改Mapping的字段类型
对于索引后期加入的字段,可以按照如下情况进行设置:
1)新增加字段
a)Dynamic设置为True时,一旦有新增字段的文档写入,Mapping同时会被更新;
b)Dynamic设置为False时,有新增字段的文档写入,Mapping不会被更新,新增字段的数据也无法被索引,但是信息会出现在_Source中;
c)Dynamic设置成Strict时,文档写入失败;

2)已有字段
a)对于已有字段,一旦已经有数据写入,就不再支持修改字段定义。因为Lucene实现的倒排索引,一旦生成后,就不允许修改。
b)如果希望改变已有字段类型,必须ReIndex,重建索引;
为什么会这样?
I)如果修改了字段的数据类型,会导致已被索引的属于无法被搜索;
II)正因为如此,对于新增加的字段,就不会有这个问题的影响;
3、对于这几种情况,我们通过下图进行演示:
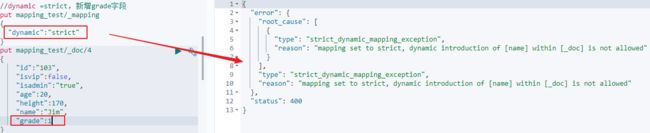
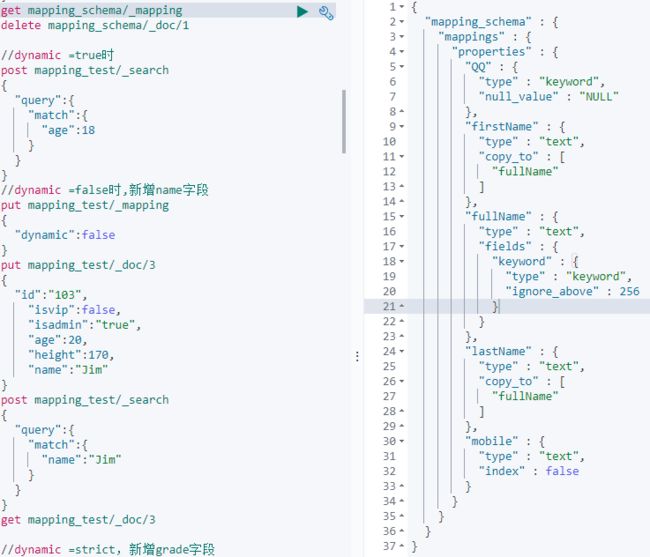
1)对于dynamic为true时,对于创建的文档中的某一字段进行搜索,是可以查询到的。
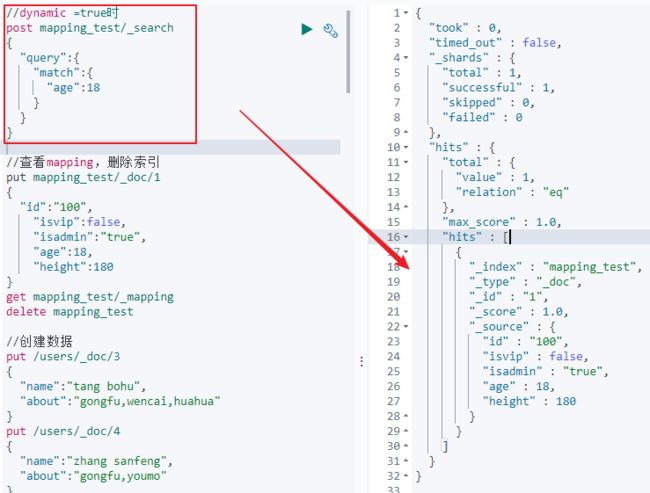
2)将dynamic设置为false,然后新增一个name字段,然后对其搜索,是无法搜索到的。
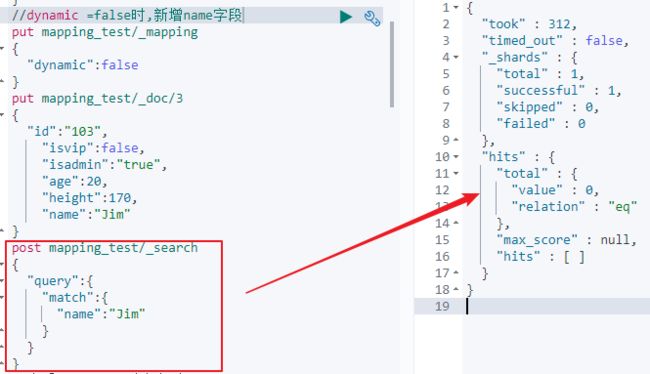
同时mapping中也不存在该字段。
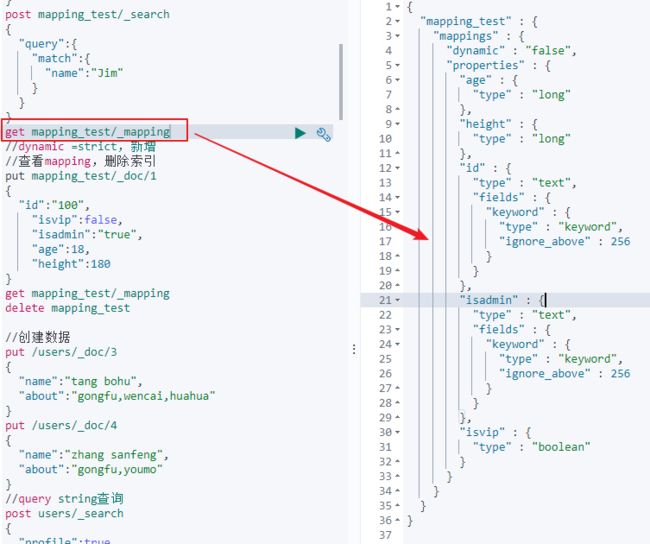
但是可以在_Source中看到这个字段。
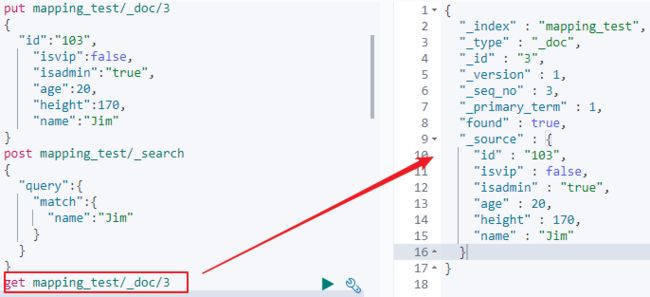
3)将dynamic设置为strict,然后新增一个grade字段,会发现出现异常。
四、索引Mapping的显式定义
1、Mapping定义的方式有两种:
1)可以参考API手册,纯手写;
2)为了减少输入工作量,减少出错概率,可以依照以下步骤:
a)创建一个临时的Index,写入一些样本数据;
b)通过访问Mapping API获取该临时索引的动态Mapping定义;
c)修改成符合要求的Json,然后创建显式索引;
d)将临时索引删除;
2、显式Mapping定义的语法:
Put Index_Name { "mappings":{ 定义Mapping信息,Json格式
"properties":{
"column_name":{
"type":"text"
},
"column_name":{
"type":"long"
}
...
}
}
}
3、显式Mapping定义的说明:
1)控制当前字段是否可以被索引,默认是True。如果设置成False,则该字段不可被搜索。
将不被搜索的字段设置成索引为false,可以节省磁盘开销,因为这样该字段就不需要进行倒排索引了。
2)对于需要索引的字段,ElasticSearch提供了Index_options配置,可以控制倒排索引记录的内容,Index_options提供了四种控制级别:
a)docs:记录doc的Id;
b)freqs:记录doc Id、Term Frequencies;
c)positions:记录doc Id、Term Frequencies、Term Position;
d)offsets:记录doc Id、Term Frequencies、Term Position、Character offsets;
3)Text类型默认是positions级别,其他类型默认是docs级别;
4)索引字段需要记录的内容越多,那么占用存储空间越大;
5)只有keyword类型支持设定Null值;
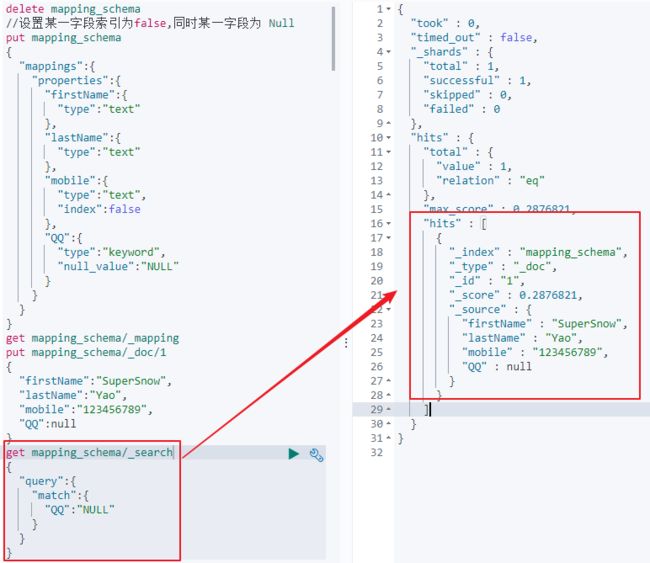
6)copy_to的设置,是将字段的值拷贝到所设定的目标字段中,当查询时,可以将该目标字段做为搜索字段进行查询。但是该目标字段不会出现在_source中。

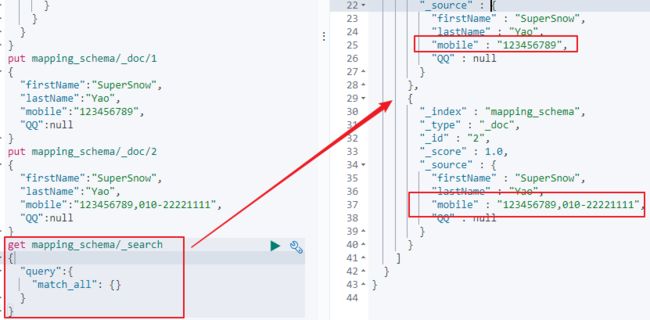
7)数组类型在ElasticSearch中并不提供,但是对于任何字段,是可以包含多个相同类型的数据的。
8)对字段还可以指定特定的analyzer。

9)查看索引Mapping,如下所示:
五、ElasticSearch字段特性与自定义Analyzer
1、Exact Values(精确值)、Full Text(全文本)
Exact Values就是指具体数字、日期、字符串,此类值是不需要进行分词的;
Full Text:是非结构化的文本数据,是需要进行分词的;

2、自定义分词器
当ElasticSearch自带的分词器无法满足要求时,可以自定义分词器,通过组合不同的Character Filter、Tokenizer、Token Filter进行实现。
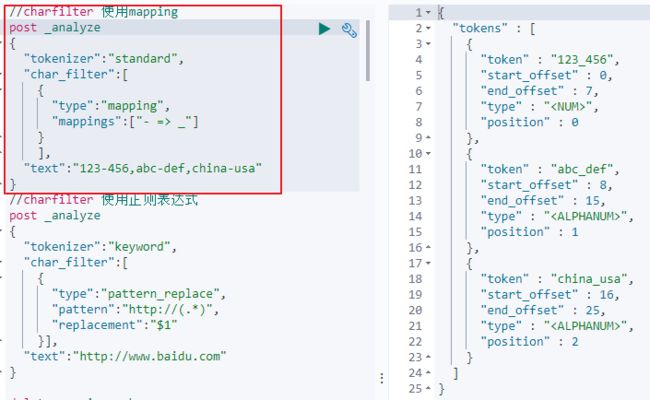
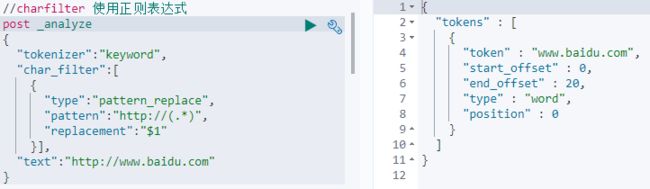
1)Charater Filters
a)在Tokenizer之前,通过使用Character Filters对文本进行处理,如删除或者替换字符。此种处理会影响后续Tokenizer对Term的Position与Offset的信息。
b)可以设置多个Character Filters,一个自带的Character Filters包括:HTML Strip(去除HTML标签)、Mapping(字符串替换)、Pattern Replace(正则表达式替换)。
如下图所示:

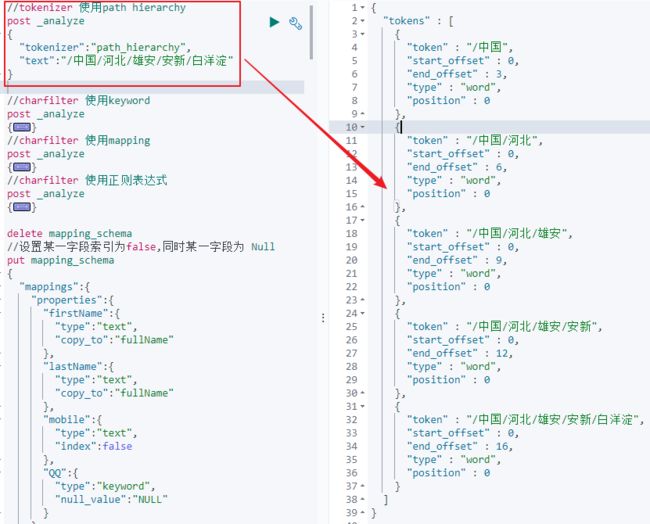
2)Tokenizer
a)将原始的文本按照一定的规则,进行切分成词(Term or Token);
b)内置的Tokenizer有:Standard、uax_url_email、WhiteSpace、keyword、Pattern、Path hierarchy;
c)可以实现自己的Tokenizer插件;
如下图所示:
3)Token Filters
a)将Tokenizer输出的Term,进行增加、修改、删除;
b)内置的Token Filters有:lowercase、stop、synonym(近义词);
如下图所示:
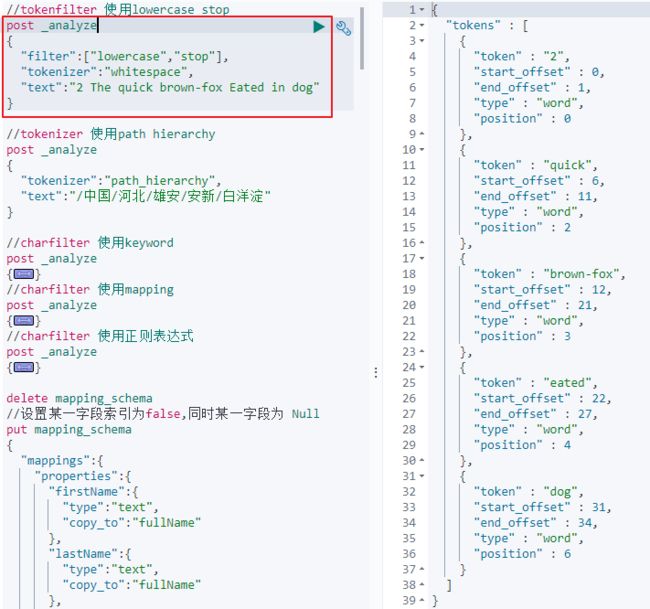
3、自定义Analyzer使用
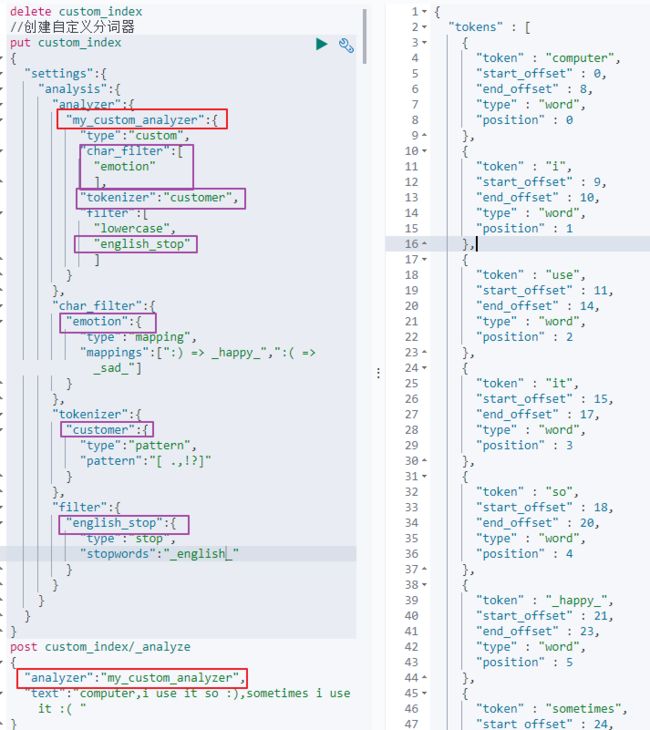
在图中的emotion、customer、english_stop,是分别对Character Filter、Tokenizer、Token Filter的自定义配置。
注意:字段类型keyword与text类型的子字段keyword的说明:
1、一切文本类型的字符串可以定义成"text"或"keyword"两种类型。区别在于,text类型会使用默认分词器分词(当然也可以指定特定的分词器),keyword类型默认不会对其进行分词;
2、多字段类型情况下,查询时可以用title,也可以用title.keyword查询类型为keyword的子字段;
大家可关注我的公众号

知识学习来源:阮一鸣:《Elasticsearch核心技术与实战》