【新人系列】Python 入门(十六):正则表达式
✍ 个人博客:https://blog.csdn.net/Newin2020?type=blog
专栏地址:https://blog.csdn.net/newin2020/category_12801353.html
专栏定位:为 0 基础刚入门 Python 的小伙伴提供详细的讲解,也欢迎大佬们一起交流~
专栏简介:在这个专栏,我将带着大家从 0 开始入门 Python 的学习。在这个 Python 的新人系列专栏下,将会总结 Python 入门基础的一些知识点,方便大家快速入门学习~
❤️ 如果有收获的话,欢迎点赞 收藏 关注,您的支持就是我创作的最大动力
在线正则表达式测试:https://tool.oschina.net/regex/#
1. 正则表达式详解
介绍
正则表达式是一种用于匹配和操作文本的规则或语法:
- 正则表达式拥有强大的文本处理能力,支持匹配、查找、替换等操作
- 广泛的应用领域,例如编程、数据处理、文本处理等领域
- 通用性强,跨语言跨场景
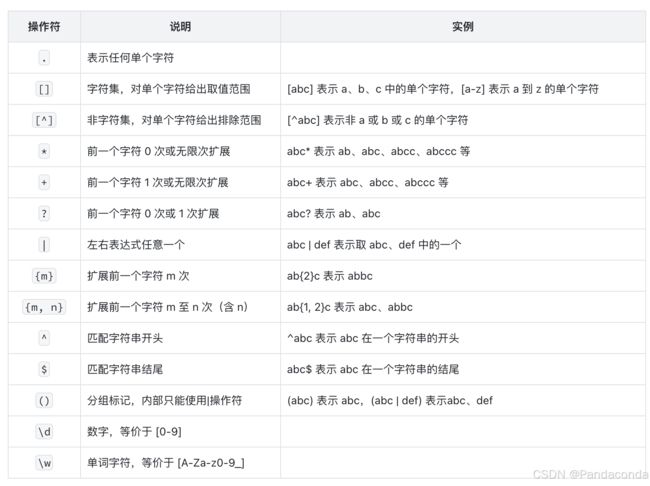
语法
2. 正则表达式实战
案例一
现在有这样一串字符,我需要根据需求查找出相应的字符信息。
hello world 12345 is book 123
- 匹配出 hello 字符串
- 方法一:
hello - 方法二:
^hello
- 方法一:
- 匹配出所有数字
- 方法:
\d+
- 方法:
- 匹配出所有字符串
- 方法:
[a-zA-Z]+
- 方法:
案例二
要求写一个正则表达式,用来匹配邮箱,而邮箱规则如下:
- 结构:前缀@后缀
- 前缀:由大小写字母、数字、下划线、中划线等构成
- 后缀:由小写字母或数字构成,并以 .com 结尾
[email protected]
[email protected]
[email protected]
匹配邮箱的正则表达式:
- 匹配单个邮箱
- 方法:
^[a-zA-Z0-9_-]+@[a-z0-9]+.com$
- 方法:
- 匹配多个邮箱
- 方法:
[a-zA-Z0-9_-]+@[a-z0-9]+.com
- 方法:
3. Python 正则表达式用法 - re 模块
3.1 re.search( )
在字符串中搜索匹配正则表达式的第一个位置。
import re
text = "Hello, World!"
result = re.search('World', text)
# 找到匹配
if result:
print("找到匹配")
print(result) # 3.2 re.match( )
用于从字符串的起始位置匹配正则表达式,如果起始位置匹配成功,则返回一个匹配对象;否则返回 None。
import re
text = "Hello World"
result = re.match('Hello', text)
# 匹配成功
if result:
print("匹配成功")
print(result) # Tips:
re.match() 只从字符串的起始位置进行匹配,而 re.search() 则会在字符串中搜索匹配的部分,不限于起始位置。
再看个复杂点的正则表达式,进一步理解一下 match 和 search 函数的区别。
# !/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author:gdx
# @File:test.py.py
# @Project:test_python
import re
# 匹配1
text1 = "@#@!¥[email protected]"
result = re.match('[a-zA-Z0-9_-]+@[a-z0-9]+.com', text1)
# 匹配失败
if result:
print("匹配成功")
print(result)
print(result.group())
else:
print("匹配失败")
# 匹配2
result = re.search('[a-zA-Z0-9_-]+@[a-z0-9]+.com', text1)
# 匹配成功
if result:
print("匹配成功")
print(result) # 3.3 re.findall( )
返回字符串中所有匹配正则表达式的子串。
import re
text = "apple, banana, cherry"
matches = re.findall('a[a-z]+', text) # ['apple', 'anana']
print(matches)
3.4 re.compile( )
re.complile() 用于编译正则表达式模式,生成一个正则表达式对象。这个对象可以被多次使用,从而提高效率。它接受一个字符串形式的正则表达式作为参数,并返回一个编译后的正则表达式对象。
除了前面提到的可以直接使用编译后的对象调用 findall 等方法之外,还可以设置一些标志参数来影响正则表达式的匹配行为。
常见的标志参数有:
- re.IGNORECASE 或 re.I :使匹配对大小写不敏感。
- re.MULTILINE 或 re.M :多行模式,影响 ^ 和 $ 的匹配行为。
- re.DOTALL 或 re.S :使 . 匹配包括换行符在内的所有字符。
import re
pattern = re.compile('hello', re.IGNORECASE)
text = "Hello World"
result = pattern.search(text)
if result:
print("找到匹配")
print(result) # 可以再来看一个分割字符串的例子。
import re
data_list=[
'2小时10分20秒',
'3小时20分30秒',
'1小时10分5秒'
]
pattern = re.compile('小时|分|秒')
for i in data_list:
res = pattern.split(i)
print(res)
"""
['2', '10', '20', '']
['3', '20', '30', '']
['1', '10', '5', '']
"""
3.5 ( ) 分组
使用括号 () 进行分组,可以提取匹配的子串。
import re
pattern = re.compile(r"(\d{3})-(\d{3})-(\d{4})")
text = "My phone number is 123-456-7890"
result = pattern.search(text)
if result:
print(result.group(1)) # 123
print(result.group(2)) # 456
print(result.group(3)) # 7890
Tips:
这里的 r 表示原始字符串,避免一些字符需要额外的转义。
3.6 re.sub( )
使用 re.sub() 函数可以进行替换操作。
import re
text = "Hello, World!"
new_text = re.sub('World', 'Python', text)
print(new_text) # Hello, Python!
我们再结合前面的分组方法看一个更复杂点的例子,我想要将一串手机号的中间 4 个数字进行加密处理,我们
import re
# 方法一:分两组
pattern = re.compile(r"(\d{3})\d{4}(\d{3})")
text = "我有几个手机号分别是:1361234567,1331234567,1797654321"
new_text = pattern.sub(r"\1****\2", text)
print(new_text) # 我有几个手机号分别是:136****567,133****567,179****321
# 方法二:分三组
pattern = re.compile(r"(\d{3})(\d{4})(\d{3})")
text = "我有几个手机号分别是:1361234567,1331234567,1797654321"
new_text = pattern.sub(r"\1****\3", text)
print(new_text) # 我有几个手机号分别是:136****567,133****567,179****321