(工程整理)如何用Maven构建Hadoop项目
本人去年的时候一直对maven项目很头疼,由于在构建hadoop项目时涉及到很多版本冲突方面的问题,但是在今年的开发中将很多问题得以解决。这一次,将本人的经验得以总结,为大家讲解一下用maven构建hadoop项目的具体步骤。
(一)hadoop家族简介

Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
参考资料:http://blog.fens.me/series-hadoop-family/
(二)Maven构建Hadoop
0. 前言
Hadoop的MapReduce是一个复杂的编程环境,所以要尽可能简化构建MapReduce项目的过程。Maven是一个很不错的自动化项目构建工具,通过Maven帮助我们从复杂的环境配置中解脱出来,从而标准化开发过程。因此,写MR之前,我们先花点时间把刀磨快!!当然,除了Maven还有其他的选择Gradle(推荐),Ivy等。后面会有介绍几篇MapReduce开发的文章,都要依赖于本文中Maven的构建的MapReduce环境。
1. Maven介绍
Apache Maven,是一个Java的项目管理及自动构建的工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)的概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。
Maven的目标是使得项目的构建更加容易,它把编译、打包、测试、发布等开发过程中的不同环节有机的串联了起来,并产生一致的、高质量的项目信息,使得项目成员能够及时地得到反馈。maven有效地支持了测试优先、持续集成,体现了鼓励沟通,及时反馈的软件开发理念。如果说Ant的复用是建立在”拷贝–粘贴”的基础上的,那么Maven通过插件的机制实现了项目构建逻辑的真正复用。
2. Maven安装(win)
下载Maven:http://maven.apache.org/download.cgi
下载最新的xxx-bin文件(例如:apache-maven-3.5.2-bin.tar.gz),在win上解压到 E:\HadoopWorkPlat\apache-maven-3.5.2。

并把maven/bin目录设置在环境变量PATH中:先创建系统变量MAVEN_HOME,将E:\HadoopWorkPlat\apache-maven-3.5.2赋值给MAVEN_HOME变量,再将%MAVEN_HOME%/bin添加到系统的Path中,如下所示。
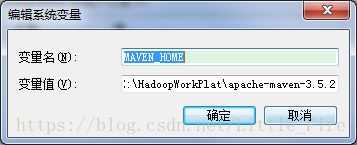
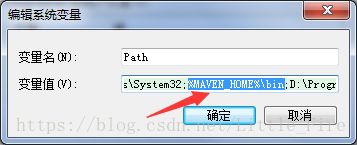

接下来需要安装Eclipse的Maven插件,下载地址:http://www.eclipse.org/m2e/,安装完成后,打开windows -> Preferences,Maven的Eclipse插件配置如下(注意,需要配置两个setting文件,可以选择相同的setting路径,也可以不同)


如图所示,我们可以选择在windows中开发,也可以在linux中开发,可以选择则在本地启动Hadoop或者远程调用Hadoop,标配的工具都是Maven和Eclipse。
4.用Maven构建Hadoop环境
(1)用Maven创建一个标准化的Java项目;(2)导入项目到eclipse;(3)增加hadoop依赖,修改pom.xml;(4)下载依赖;(5)从Hadoop集群环境下载hadoop配置文件;(6)配置本地host。
(1)用Maven创建一个标准化的Java项目
在指定的路径x输入以下命令,maven就会自动下载一个项目:
mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=org.conan.myhadoop.mr
-DartifactId=myHadoop -DpackageName=org.conan.myhadoop.mr -Dversion=1.0-SNAPSHOT -DinteractiveMode=false我们创建好了一个基本的maven项目,然后导入到eclipse中。 这里我们最好已安装好了Maven的插件。
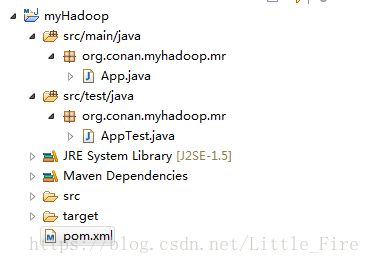
(3)在pom.xml中添加hadoop依赖
2.6.0
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
(4)下载依赖:mvn clean install
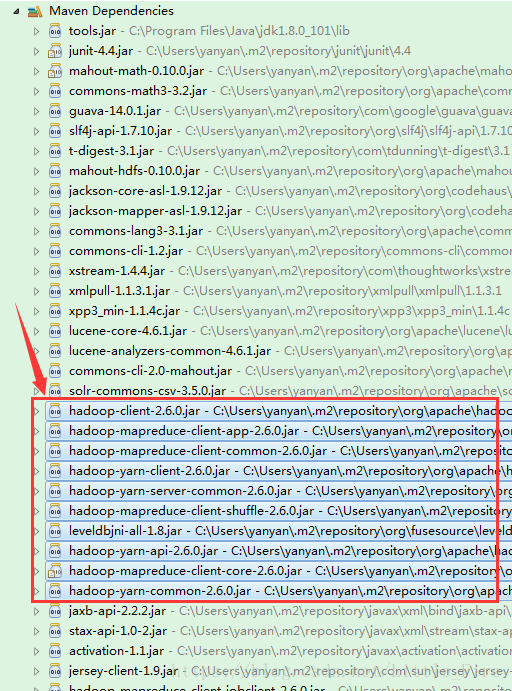
项目的依赖程序,被自动加载的库路径下面。
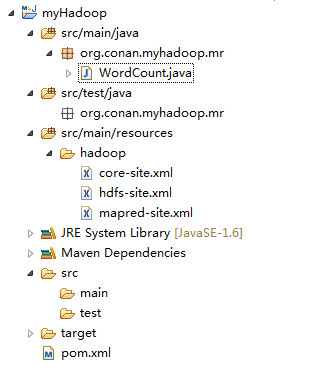
(5)从Hadoop集群环境中下载hadoop的相关配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,并将它们保存在src/main/resources/hadoop目录下面,同时delete掉原自动生成的文件:App.java和AppTest.java。
(6)配置本地host,增加master的域名指向:进入目录C:\Windows\System32\drivers\etc,打开hosts,配置master的域名指向:

5 一个简单的MapReduce程序开发
public class WordCounterJob {
private static Configuration getBigdataConfig() {
Configuration conf = HBaseConfiguration.create();
conf.addResource("/usr/local/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml");
conf.set("fs.default.name", "hdfs://192.168.106.102:9000");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "192.168.106.102");
conf.set("hbase.master", "192.168.106.102:16010");
conf.set("hbase.rpc.timeout", "2000");
conf.set("hbase.client.retries.number", "5");
conf.set("dfs.socket.timeout", "180000");
conf.set("zookeeper.session.timeout", "180000");
conf.set("hbase.client.scanner.timeout.period", "240000");
conf.set("hbase.client.retries.number", "100");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
conf.set("mapreduce.tasktracker.map.tasks.maximum", "7");
conf.set("mapreduce.tasktracker.reduce.tasks.maximum", "4");
conf.set("mapreduce.job.reduces", "4");
conf.set("mapred.compress.map.output", "true");
return conf;
}
protected static class WordCounterMapper extends Mapper {
String name;
String company;
IntWritable one;
Text outKey;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = context.getConfiguration();
name = conf.get("my.name", "null");
company = conf.get("my.company", "null");
one = new IntWritable(1);
outKey = new Text();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
outKey.set(name);
context.write(outKey, one);
outKey.set(company);
context.write(outKey, one);
String line = new String(value.getBytes(), 0, value.getLength(), "GBK");
String[] tokens = line.split("\\s+");
for (String token : tokens) {
int mid = token.indexOf("/");
if (mid != -1) {
String word = token.substring(0, mid);
word = word.replace("[", "").replace("]", "");
if (word.matches("[\u4e00-\u9fa5]+")) {
outKey.set(word);
context.write(outKey, one);
}
}
}
}
}
protected static class MyPartitioner extends Partitioner {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// TODO Auto-generated method stub
return 0;
}
}
protected static class WordCounterReducer extends Reducer {
@Override
protected void reduce(Text arg0, Iterable arg1, Context arg2)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum = 0;
for (IntWritable i : arg1) {
sum += i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}
private static void run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = getBigdataConfig();
System.out.println(conf.get("fs.default.name"));
conf.setStrings("my.name", "wangyanyan");
conf.setStrings("my.company", "cnki");
Job job = Job.getInstance(conf);
job.setJarByClass(WordCounterJob.class);
job.setJobName("WordCounterJob");
job.setInputFormatClass(TextInputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCounterMapper.class);
job.setReducerClass(WordCounterReducer.class);
job.setCombinerClass(WordCounterReducer.class);
job.setNumReduceTasks(2);
Path outputPath = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outputPath);
long t0 = System.currentTimeMillis();
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
} else {
long t1 = System.currentTimeMillis();
System.out.println(">> Running success, " + (t1 - t0) / 60000.0 + " min");
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
args = new String[] { "hdfs://192.168.106.102:9000/wangyanyan/count/in",
"hdfs://192.168.106.102:9000/wangyanyan/count/out" };
run(args);
}
} wangyanyan 10000
一万 2
一下 9
一下子 7
一九九七年 6
一九九八年 4
一九五六 1
一九八二年 1
一体化 9
一千 3
......