XGBoost论文阅毕
花了两天读了陈天奇大神的XGBoost论文,了解了大概原理,水平有限,如有错误,烦请指正,记录如下。
一、简要介绍
1、模型
提升树(Boosted tree )最基本的组成部分叫做回归树(regression tree),称为CART。
XGBoost Tree由多个CART集成,按照策略选取最佳分隔点,对稀疏数据进行处理,并加入了例如并行化等优化方法。
2、特点
1、设计并构建了高可扩展(规模化的)的端到端的提升树系统(a highly scalable end-to-end tree
boosting system )
(end-to-end(端对端)的方法是指:一端输入我的原始数据,一端输出我想得到的结果。只关心输入和输出,中间的步骤全部都不管。)
2、在树的并行学习过程中引入了新的稀疏感知算法
3、在理论上证明了分布式加权直方图算法能提高计算效率
4、针对树的核外学习提出了有效的缓存感知块结构
提升树每一次进行回归树生成时采用的训练数据都是上次预测结果与训练数据值之间的残差
梯度提升树其学习流程与提升树类似只是不再使用残差作为新的训练数据而是使用损失函数的梯度作为新的新的训练数据的y值
二、公式推导
目标函数=训练损失+正则化

常用的损失函数有以下两种:
1、平方损失
![]()
2、逻辑回归损失
![]()
f(x)是单棵树的叶子结点的得分相加,对于K棵Cart回归树这个过程可以表示如下:

当前模型如下:
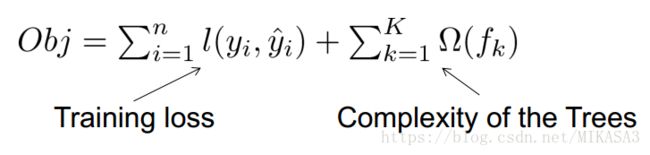
采用前向分步算法来计算函数f(x):

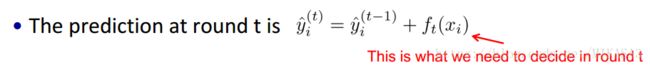
代入模型的公式,其中我们选用平方损失来评估:

使用二阶泰勒公式展开:

移除常数项![]() 整理得到模型:
整理得到模型:
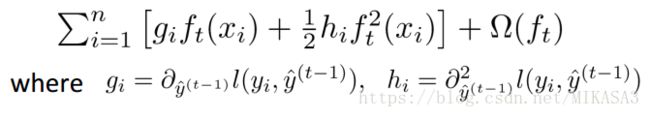
重新用向量定义树的叶子结点:

选取一种方式定义树的复杂度:

代入模型公式,整理如下:
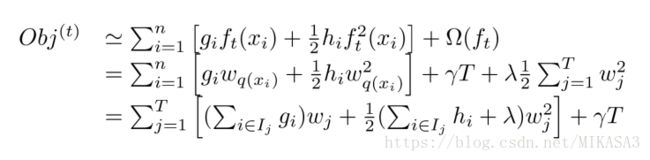
增加定义,修改公式形式:
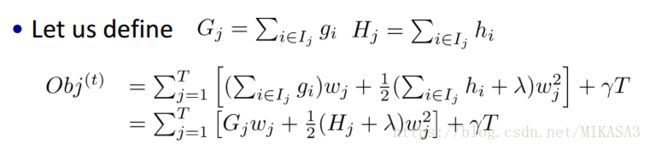
我们定义每个叶子结点的权重为:
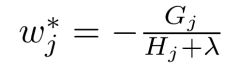
最终得到的对树的评估模型:
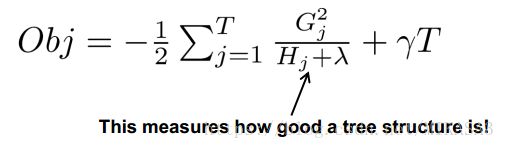
这个模型的得分越小表示树的分隔点选取得越好~
3、剪枝
优化这个目标对应了树的剪枝, 当引入的分割带来的增益小于一个阀值的时候,我们可以剪掉这个分割。
4、防止过拟合
(1)缩减(Shrinkage)
在梯度提升的每一步之后,增加权重,类似于随机优化过程中的学习率,减少单棵树的影响
(2)对列的二次采样(Column Subsampling)
常用于随机森林,此前从未被应用到提升树中。从用户反馈来看,优于传统的对行的二次采样,而且还能提高并行算法的计算速度。
三、分隔点查找算法
1、基础贪心算法
在所有特征上遍历,每个特征中选择该特征下的每个值作为其分裂点,计算增益损失。当遍历完所有特征之后,增益损失最大的特征值将作为其分裂点。由此可以看出这其实就是一种穷举算法,而整个树构造过程最耗时的过程就是寻找最优分裂点的过程。
缺点:当数据量很大不能全都放入内存中的时候,不能高效操作
2、近似算法
根据特征分布的百分数采样,选择待分隔点,将连续的特征映射到一个桶(buckets)中,基于统计信息选择最佳分隔方案。选择分隔点的方式有两个,一种是global,一种是local。
global是在树构建的初始阶段选出所有候选分隔点,后面每层都使用相同的策略选择分隔点;
local在每次split后重新选出候选分隔点,适合较深的树,这样步骤比global多。
综上,local只需要较少的候选点,而global必须要有足够多的候选点(桶)才能达到和local差不多的精确度。
对每一个特征进行「值」采样,原来需要对每一个特征的每一个可能分割点进行尝试,采样之后只针对采样的点进行分割尝试,这种方法很明显可以减少计算量,采样密度越小计算的越快,拟合程度也会越差,所以采样还可以防止过拟合。
3、带权重直方图算法
样本的所有第k个特征构造一个集合:{特征的值,二阶导数}
序函数表示第k个特征的值小于z的样本比例,为了找到满足相邻两个分隔点的值相差不大于阈值e的分隔点。
相当于将特征的值排序,在这个序列上根据计算带权的序函数选择合适的分隔点,使得每个含有不同权重的特征值区间分布均匀。
对于带权重的数据集合,此前还没有直方图算法来处理。
4、稀疏感知的分隔点查找算法
指定一个默认方向。
这里只遍历特征非空的样本上对应的所有特征值,分别尝试将该缺失特征分配到左右子树,分别计算这两种情况下的打分函数的值,选择分数较大的方向为缺失数据的默认方向:

计算复杂度是线性的,速度提升50倍。
四、并行化
1、按列分块并行化
对每个特征的值排序,使用CSC结构存储数据到块(block)中。
在不同的特征属性上采用多线程并行方式寻找最佳分隔点
每一次Split Finding的时候是需要对当前节点中的样本按照特征值进行排序的,其实这个排序可以在初始化的时候进行一次就够了,比如有n个样本m维特征,只需要预先生成一个n*m的矩阵,第m列表示的是按照第m个特征从小到大对样本的排序索引。 通过指针存储,一个指针也就是四个字节,耗费的空间有限。
2、缓存感知存取
因为对特征的值排序后,其对应的二阶梯度在内存中不是连续存放的,所以需要一个新算法能够通过行索引直接获取梯度数据。
在每个线程内开辟内部缓冲区,存储梯度统计数据,以小批量方式执行累加。
预取改变直接读取相依性为长相依性
也就是说本来每次操作的时候都要寻找特征对应的梯度,现在放入缓冲区之后,可以很快找到对应信息并计算。
3、核外计算的块
为了可模块化的学习,将数据分成多个block存在磁盘上,在计算过程中,用其他的线程预取数据到主要的内存缓冲区,这样计算和读数据就可以并发进行。
(1)块压缩
但是由于磁盘IO速度太慢,通常更不上计算的速度,将block按列压缩,对于行索引,只保存第一个索引值,然后只保存其余数据与第一个索引值之差(offset),实验得到的较好情况是使用16个bits来保存 offset,因此,一个block一般有2的16次方个样本。
(2)块碎片
将数据分片到不同的磁盘上,预取线程分配到各个磁盘上,取得的数据放入内存缓冲区中,之后训练线程从各个内存缓冲区中获取数据。
有多个磁盘的时候,有助于增加磁盘读数据的吞吐量。