Leetcode 3 无重复字符的最长子串
题目本身不难,思路很清晰,重点是记录下自己代码优化的思考过程
我一开始用的双重循环版,提交后提示栈缓冲区溢出,原因不明
int lengthOfLongestSubstring(string s)
{
int maxLength = 1, len;
set se;
for (int i = 0;i < s.length()-1;i++)
{
se.clear();
se.insert(s[i]);
len = 1;
for (int j = i+1;j < s.length();j++)
{
if (se.find(s[j]) == se.end())
{
se.insert(s[j]);
len++;
}
else
{
break;
}
}
if (maxLength < len)
maxLength = len;
}
return maxLength;
} 无奈,改成伪一重循环,提交
int lengthOfLongestSubstring(string s)
{
int maxLength = 0, len = 0, nextIndex=1;
set se;
for (int i = 0;i < s.length();i++)
{
if (se.find(s[i]) == se.end())
{
se.insert(s[i]);
len++;
if (len > maxLength)
maxLength = len;
}
else
{
i = nextIndex;
nextIndex++;
se.clear();
se.insert(s[i]);
len = 1;
}
}
return maxLength;
} 代码成功,但是,
这数字有点惊心动魄,不太可思议,特别是内存占用。
后经百度发现,stl的set等容器在执行clear后内存并不会释放,只会越来越大
好吧,我改成哈希
int lengthOfLongestSubstring(string s)
{
int maxLength = 0, len = 0, nextIndex = 1;
bool book[128];
memset(book, false, 128);
for (int i = 0;i < s.length();i++)
{
if (book[s[i]] == false)
{
len++;
if (len > maxLength)
maxLength = len;
}
else
{
i = nextIndex;
nextIndex++;
memset(book, false, 128);
len = 1;
}
book[s[i]] = true;
}
return maxLength;
}代码成功,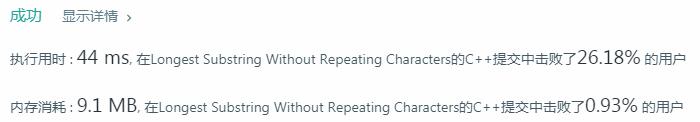
但是似乎速度也不算很快,让我学习下题解,改造一下
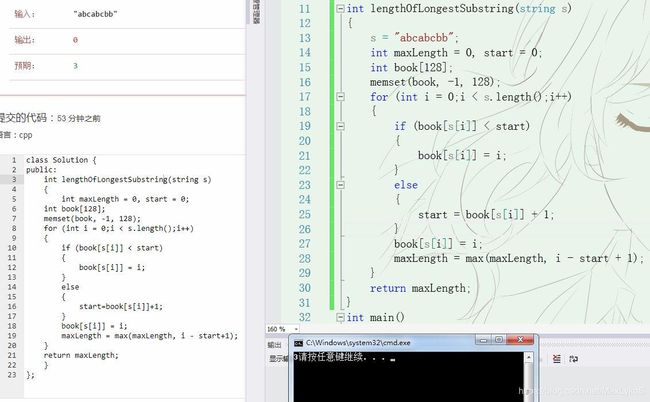
int lengthOfLongestSubstring(string s)
{
int maxLength = 0, start = 0;
int book[128];
memset(book, -1, sizeof(book));
for (int i = 0;i < s.length();i++)
{
if (book[s[i]] >= start)
{
start = book[s[i]]+1;
}
book[s[i]] = i;
maxLength = max(maxLength, i - start+1);
}
return maxLength;
}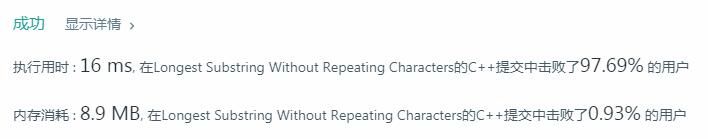
思路,哈希表的键代表字符,值代表下标,仿照“滑动窗口”,start代表开始位置,i代表结束位置
if那里比较难理解,因为start代表开始位置,初值是0而哈希的键初值为-1,所以一开始时,所有字符在哈希里的下标是在start前面的,那么在后面的赋值中,会被“挪到”start后面来,那么在第二次得到相同的字符时,就知道该字符的下标是在start后面。start往后移动之后,i如果碰到了以前出现过或没出现的数,无非还是两种情况,在start前面和后面。在前面就看作是新出现的数,在start后面那肯定是第二次出现的数了。
这里有个很有意思的地方。我一开始的代码是memset(book, -1, 128);
后来发现自己的IDE输出对了而OJ输出是0,思前想后,百度了半天没找到毛病
后来改成memset(book, -1, sizeof(book));就没问题了。原因不明,希望日后能了解