遗传算法 (genetic algorithm (GA))
– 英文原文链接 –
I. 介绍
遗传算法是进化计算的一部分,进化计算是一个快速发展的人工智能领域。遗传算法的灵感来自达尔文的进化论。
简单地说:问题通过演化过程解决,从而产生最佳(最适合)的解决方案(幸存者)
换句话说:解决方案得到了发展。
历史
进化计算是在20世纪60年代由I.Rechenberg在他的作品“进化策略”(Evolutionsstrategie in original)中引入的。他的想法随后由其他研究人员开发。遗传算法(GA)由John Holland发明,由他和他的学生及同事开发。这导致荷兰出版于1975年出版的“自然与人工系统中的适应”一书。1992年,约翰·科扎使用遗传算法来演化程序以执行某些任务。他称他的方法为“遗传编程”(GP)。使用了LISP程序,因为这种语言的程序可以以“解析树”的形式表示,这是GA工作的对象。
II. 生物背景
1.染色体
所有生物都由细胞组成。在每个细胞中都有相同的染色体组。染色体是DNA串,可作为整个生物体的模型。染色体由基因,DNA块组成。每个基因编码特定的蛋白质。基本上,可以说每个基因编码特征,例如眼睛的颜色。特征的可能设置(例如蓝色,棕色)称为等位基因。每个基因在染色体中都有自己的位置。这个位置叫做轨迹。完整的遗传物质(所有染色体)称为基因组。基因组中特定的一组基因称为基因型。基因型是在出生后的基因型,有机体的表型,其身体和心理特征,如眼睛的颜色,智力等。
2.遗传
在再现期间,首先发生重组(或交叉)。来自父母的基因组合形成一个全新的染色体。然后可以突变新创建的后代。突变意味着DNA的元素有点变化。这种变化主要是由父母复制基因的错误引起的。通过生物体在其生命(存活)中的成功来测量生物体的适合度。
III. 搜索空间
如果我们正在解决问题,我们通常会寻找一些最好的解决方案。所有可行解决方案的空间(所需解决方案所在的解决方案集)称为搜索空间(也称为状态空间)。搜索空间中的每个点代表一种可能的解决方案。每个可能的解决方案可以通过其对问题的值(或适应度)进行“标记”。通过GA,我们在众多可能的解决方案中寻找最佳解决方案 - 以搜索空间中的一个点为代表。然后寻找解决方案等于在搜索空间中寻找一些极值(最小值或最大值)。有时可以很好地定义搜索空间,但通常我们只知道搜索空间中的几个点。在使用遗传算法的过程中,随着进化的进行,寻找解决方案的过程会产生其他点(可能的解决方案)。
问题是搜索可能非常复杂。人们可能不知道在哪里寻找解决方案或从哪里开始。有许多方法可用于寻找合适的解决方案,但这些方法不一定能提供最佳解决方案。这些方法中的一些是爬山,禁忌搜索,模拟退火和遗传算法。通过这些方法找到的解决方案通常被认为是很好的解决方案,因为通常不可能证明最佳方案。
NP-hard Problems
NP问题是一类无法用“传统”方式解决的问题。我们可以快速应用许多任务(多项式)算法。还存在一些无法通过算法解决的问题。有很多重要问题很难找到解决方案,但是一旦有了解决方案,就很容易检查解决方案。这一事实导致了NP完全问题。 NP代表非确定性多项式,它意味着可以“猜测”解决方案(通过一些非确定性算法),然后检查它。如果我们有一台猜测机器,我们或许可以在合理的时间内找到解决方案。为简单起见,研究NP完全问题仅限于答案可以是或否的问题。由于存在输出复杂的任务,因此引入了一类称为NP难问题的问题。这个类并不像NP完全问题那样受限。 NP问题的一个特征是,可以使用一个简单的算法,可能是第一眼看到的,可用于找到可用的解决方案。但是这种方法通常提供了许多可能的解决方案 - 只是尝试所有可能的解决方案是非常缓慢的过程(例如O(2 ^ n))。对于这些类型问题的更大的实例,这种方法根本不可用。今天没有人知道是否存在一些更快的算法来提供NP问题的确切答案。对于研究人员来说,发现这样的算法仍然是一项重大任务(也许你!)。今天许多人认为这种算法不存在,因此他们正在寻找替代方法。替代方法的一个例子是遗传算法。 NP问题的例子是可满足性问题,旅行商问题或背包问题。可以获得NP问题汇编。
IV. Genetic Algorithm
基本描述
遗传算法的灵感来自达尔文的进化论。通过遗传算法解决的问题的解决方案使用进化过程(它是进化的)。算法从称为群体的一组解决方案(由染色体表示)开始。一个群体的解决方案被用于形成新的人口。这是出于希望,新人口将比旧人口更好。然后选择形成新解决方案(后代)的解决方案根据它们的适应性进行选择 - 它们越适合它们就越有可能再现。重复这一过程,直到满足一些条件(例如群体数量或最佳解决方案的改进)。示例正如您从关于搜索空间的章节中已经知道的那样,解决问题通常可以表示为寻找函数的极端。我们在这里解决了这个问题 - 给出了一个函数,GA试图找到函数的最小值。尝试通过按下“开始”按钮在以下小程序中运行遗传算法。图表代表搜索空间,垂直线代表解决方案(搜索空间中的点)。红线是最好的解决方案,绿线是其他的。 “开始”按钮启动算法,“步骤”按钮执行一个步骤(即形成一个新一代),“停止”按钮停止算法,“重置”按钮重置群体。这是applet,但您的浏览器不支持Java。
####基本遗传算法概述
1.[开始]生成n个染色体的随机群体(适合该问题的解决方案)
2.[适应度]评估群体中每个染色体x的适应度f(x)
3.[新种群]通过重复以下来创建新种群直到新种群完成的步骤
3.1 [选择]根据种群的适合度选择两个亲本染色体(更好的适应性,更大的选择机会)
3.2 [交叉]以交叉概率跨越父母形成新的后代(儿童) )。如果没有进行交叉,后代就是父母的确切副本。
3.3 [突变]突变概率突变每个基因座(染色体中的位置)的新后代。
4.[接受]在新种群中放置新后代[替换]使用新生成的种群进一步运行算法
5.[测试]如果满足结束条件,则停止并返回当前种群中的最佳解
6。[循环]转到步骤2
一些注释
正如您所看到的,基本GA的概要非常笼统。有许多参数和设置可以在各种问题中以不同方式实现。要问的第一个问题是如何创建染色体以及选择何种类型的编码。然后,我们解决了GA的两个基本运算符Crossover and Mutation。编码,交叉和变异将在下一章介绍。接下来的问题是如何选择父母进行交叉。这可以通过多种方式完成,但主要的想法是选择更好的父母(最好的幸存者),希望更好的父母能够产生更好的后代。您可能认为仅从两个父母中产生群体可能会导致您从最后一个群体中丢失最佳染色体。这是事实,因此经常使用精英主义。这意味着,至少有一代最佳解决方案被复制而无需更改新的群体,因此最佳解决方案可以存活到后代。你可能会徘徊,为什么遗传算法有效。它可以用Schema Theorem(Holland)来部分解释,然而,这个定理近来受到了批评。如果您想了解更多信息,请查看其他资源。
V. 影响GA的因素
1.概述
从遗传算法概述可以看出,交叉和变异是遗传算法中最重要的部分。性能主要受这两个因素的影响。在我们解释有关交叉和变异的更多信息之前,我们将给出一些有关染色体的信息。
2.染色体编码
染色体应该以某种方式包含它所代表的解决方案的信息。最常用的编码方式是二进制字符串。然后染色体看起来像这样:
| 名称 | 染色体编码 |
|---|---|
| Chromosome 1 | 1101100100110110 |
| Chromosome 2 | 1101111000011110 |
每个染色体由二进制字符串表示。字符串中的每个位都可以表示解决方案的一些特征。另一种可能性是整个字符串可以表示一个数字 - 这已在基本的GA小程序中使用。当然,还有许多其他的编码方式。编码主要取决于解决的问题。例如,可以直接编码整数或实数,有时对某些排列等进行编码很有用。
3.染色体交叉
在我们确定了将使用的编码之后,我们可以继续进行交叉操作。 Crossover对来自亲本染色体的选定基因进行操作并产生新的后代。最简单的方法是随机选择一些交叉点,并在此点之前从第一个父项复制所有内容,然后在交叉点之后复制另一个父交叉点之后的所有内容。交叉可以说明如下:( |是交叉点):
| 名称 | 染色体编码 |
|---|---|
| Chromosome 1 | 11011 - 00100110110 |
| Chromosome 2 | 11001 - 11000011110 |
| Offspring 1 | 11011 - 11000011110 |
| Offspring 2 | 11001 - 00100110110 |
还有其他方法可以进行交叉,例如我们可以选择更多的交叉点。交叉可能非常复杂,主要取决于染色体的编码。针对特定问题进行的特定交叉可以改善遗传算法的性能。
4.染色体突变
在执行交叉之后,发生突变。突变旨在防止群体中的所有解决方案落入解决问题的局部最优中。突变操作随机改变由交叉引起的后代。在二进制编码的情况下,我们可以将一些随机选择的位从1切换到0或从0切换到1.突变可以如下所示:
| 名称 | 染色体编码 |
|---|---|
| Original offspring 1 | 110 1 111000011110 |
| Original offspring 2 | 110110 0 100110110 |
| Mutated offspring 1 | 110 0 111000011110 |
| Mutated offspring 2 | 110110 1 100110110 |
突变(以及交叉)技术主要取决于染色体的编码。例如,当我们编码排列时,可以将突变作为两个基因的交换来进行。
VI. GA示例函数的最小值
1.概述
正如您从关于搜索空间的章节中已经知道的那样,解决问题通常可以表示为寻找在搜索空间上定义的函数的极端情况。我们在这里解决了这个问题。给出了一个函数,GA试图找到函数的最小值。对于其他问题,我们只需要定义搜索空间和适应度函数(我们想要找到一个极端)。
2.示例尝试
通过按“开始”按钮在以下小程序中运行遗传算法。图表代表搜索空间,垂直线代表解决方案(搜索空间中的点)。红线是最好的解决方案,绿线是其他的。新旧人口显示在applet的顶部。每个群体由二元染色体组成 - 红色和蓝色点表示零和1。您可以在applet中逐步查看形成新填充的过程。 “开始”按钮启动算法,“步骤”按钮执行一个步骤(即形成一个新一代),“停止”按钮停止算法,“重置”按钮重置群体。建议首先按下“步骤”按钮,然后观察GA的工作原理。 GA的概要已在前面的章节之一中介绍过。您可以看到第一条染色体的精英主义,然后通过交叉和突变形成新的后代,直到新的种群完成。
VII. GA的参数
1.交叉和突变概率
GA有两个基本参数 - 交叉概率和变异概率。
交叉概率 :交叉的频率。如果没有交叉,后代就是父母的精确副本。如果存在交叉,则后代由父母染色体的部分组成。如果交叉概率为100%,那么所有后代都是由交叉产生的。如果它是0%,那么全新一代都是从旧种群的染色体的精确拷贝制成的(但这并不意味着新一代是相同的!)。交叉是希望新染色体将包含旧染色体的良好部分,因此新染色体将更好。但是,将旧人口的一部分留给下一代是好的。
突变概率 :染色体部分突变的频率。如果没有突变,则在交叉(或直接复制)后立即生成后代而不进行任何更改。如果进行突变,则改变染色体的一个或多个部分。如果突变概率为100%,则整个染色体发生变化,如果是0%,则没有变化。突变通常会阻止GA陷入局部极端。突变不应该经常发生,因为GA实际上会改变为随机搜索。
2.其他参数
种群规模:种群中有多少染色体(一代)。如果染色体太少,GA几乎没有可能进行交叉,只探索了一小部分搜索空间。另一方面,如果染色体太多,GA会减慢。研究表明,经过一定的限制(主要取决于编码和问题),使用非常大的种群是没有用的,因为它不能比中等规模的种群更快地解决问题。
VIII. 极端的功能
关于这个问题
问题是再次寻找功能的极端。但是,在这种情况下,还会添加一个维度。
例
图表代表搜索空间,线代表解决方案(搜索空间中的点)。红线是最好的解决方案,蓝线是其他的。您可以在图表下方的文本字段中输入您自己的功能(更改后按enter或按钮更改)。在它下面你可以定义功能限制。函数可以包括x,y,pi,e,(,),/,* , - ,!,^和函数abs,acos,acosh,asin,asinh,atan,atanh,cos,cosh,ln,log, sin,sinh,sqr,sqrt,tan和tanh。可以通过用鼠标拖动来旋转图形。您还可以更改交叉和变异概率。通过复选框,您可以指定是否要使用精英主义以及是否要查找最小值或最大值。尝试更改功能,看看GA的工作原理。
IX. 选择
正如您从GA概述中已经知道的那样,从群体中选择染色体作为交叉的父母。问题是如何选择这些染色体。根据达尔文的进化论,最好的进化能够创造出新的后代。选择最佳染色体的方法有很多种。例如轮盘赌选择,Boltzman选择,锦标赛选择,等级选择,稳态选择和其他一些选择。其中一些将在本章中介绍。
1.轮盘赌选择
父母根据他们的健康状况选择。染色体越好,它们被选择的机会就越多。想象一下轮盘赌轮,人口中的所有染色体都放在那里。轮盘中截面的大小与每条染色体的适应度函数的值成比例 - 值越大,截面越大。有关示例,请参见下图。

轮盘赌中放入一块大理石,并选择停止的染色体。显然,具有较大适应值的染色体将被选择更多次。
该过程可以通过以下算法来描述。
[Sum]计算总体中所有染色体拟合度的总和 - 总和S.
[Select]从区间(0,S)-r生成随机数。
[循环]遍历总体并从0 - 总和中求和。当总和s大于r时,停止并返回您所在的染色体。当然,对于每个群体,步骤1仅执行一次。
2.排名选择
当健身值之间存在很大差异时,先前的选择类型会出现问题。例如,如果最佳染色体适应度是所有拟合度总和的90%,那么其他染色体将很少被选择的机会。等级选择首先对群体进行排序,然后每个染色体接收由该等级确定的适合度值。最差的将是健身1,第二个最差的2等等,最好的将具有适应度N(人口中的染色体数量)。您可以在下面的图片中看到,在更改适应性与排名确定的数字后情况如何变化。
现在所有染色体都有机会被选中。然而,这种方法会导致收敛速度变慢,因为最好的染色体与其他染色体的差别不大。
3.稳态选择
这不是选择父母的特定方法。这种选择新种群的主要思想是染色体的很大一部分可以存活到下一代。稳态选择GA以下列方式工作。在每一代中,选择一些好的(具有更高适应性)染色体来创建新的后代。然后去除一些不好的(具有较低适合度)染色体并将新的后代放置在它们的位置。其余人口幸存下来。
4.精英
精英主义的想法已经被引入。当通过交叉和变异创建新的种群时,我们有很大的机会,我们将失去最好的染色体。精英主义是首先将最佳染色体(或少数最佳染色体)复制到新种群的方法的名称。其余人口以上述方式构建。精英主义可以迅速提高GA的性能,因为它可以防止丢失最佳找到的解决方案。
X. 编码
在开始解决GA问题时,首先要问的是染色体编码。编码很大程度上取决于问题。在本章中,将介绍一些已经使用并取得一些成功的编码。
1.二进制编码
二进制编码是最常见的,主要是因为GA的第一次研究使用了这种类型的编码并且因为它相对简单。在二进制编码中,每个染色体都是一串位 - 0或1。
具有二进制编码的染色体的示例
| 名称 | 染色体编码 |
|---|---|
| Chromosome A | 101100101100101011100101 |
| Chromosome B | 111111100000110000011111 |
即使具有少量等位基因,二进制编码也提供了许多可能的染色体。另一方面,对于许多问题,这种编码通常不自然,并且有时必须在交叉和/或突变之后进行校正。
问题示例:背包问题
问题:有些东西具有给定的价值和规模。背包已经提供了容量。选择最大化背包中物品价值的东西,但不要扩展背包容量。
编码:每一位都说,相应的东西是否在背包中。
2.置换编码
置换编码可用于排序问题,例如旅行商问题或任务排序问题。在置换编码中,每个染色体是一串数字,表示序列中的位置。
具有置换编码的染色体的示例
| 名称 | 染色体编码 |
|---|---|
| Chromosome A | 1 5 3 2 6 4 7 9 8 |
| Chromosome B | 8 5 6 7 2 3 1 4 9 |
置换编码对于排序问题很有用。对于某些类型的交叉和突变,必须进行校正以使染色体保持一致(即在其中具有实际序列)以解决某些问题。
问题示例:旅行商问题(TSP)
问题:城市之间存在距离。旅行推销员必须访问他们所有人,但他不想旅行超过必要的。查找具有最小行进距离的一系列城市。
编码:染色体描述了城市的顺序,销售人员将在其中访问它们。
3.价值编码
直接值编码可以用于一些更复杂的值(例如实数)的问题。对这类问题使用二进制编码将是困难的。在值编码中,每个染色体都是一些值的序列。值可以是与问题相关的任何值,例如(实数),字符或任何对象。
具有值编码的染色体的示例
| 名称 | 示例 |
|---|---|
| Chromosome A | 1.2324 5.3243 0.4556 2.3293 2.4545 |
| Chromosome B | ABDJEIFJDHDIERJFDLDFLFEGT |
| Chromosome C | (back), (back), (right), (forward), (left) |
对于某些特殊问题,值编码是一个不错的选择。但是,对于这种编码,通常需要开发一些针对该问题的新的交叉和突变。
问题示例:查找神经网络的权重
问题:神经网络具有定义的体系结构。在神经网络中的神经元之间找到权重,以从网络获得所需的输出。
编码:染色体中的实际值表示神经网络中的权重。
4.树编码
树编码主要用于进化程序或表达,即用于遗传编程。在树编码中,每个染色体都是一些对象的树,例如编程语言中的函数或命令。
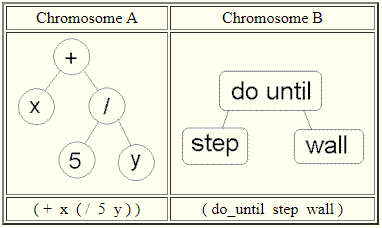
树编码对于演化程序或可以在树中编码的任何其他结构非常有用。编程语言LISP通常用于此目的,因为LISP中的程序直接以树的形式表示,并且可以很容易地解析为树,因此可以相对容易地完成交叉和变异。
问题示例:查找将近似给定值对的函数
问题:给出输入和输出值。任务是找到一个能为所有输入提供最佳输出(即最接近所需输出)的功能。
编码:染色体是树中表示的功能。
XI. 交叉(Crossover)和突变 (Mutation)
交叉和变异是GA的两个基本运算符。 GA的表现非常依赖于它们。运算符的类型和实现取决于编码以及问题。有多种方法可以执行交叉和变异。在本章中,我们将简要介绍一些如何执行多个编码的示例和建议。
1.二进制编码
交叉
-
单点交叉 - 选择一个交叉点,从第一个父项复制从染色体开始到交叉点的二进制字符串,其余从另一个父项复制

-
选择两点交叉 - 两个交叉点,从第一个父节点复制从染色体开始到第一个交叉点的二进制字符串,从第一个父节点复制从第一个交叉点到第二个交叉点的部分,其余的是再次从第一个父级复制
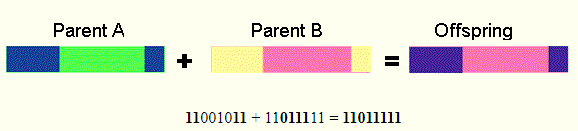
-
均匀交叉 - 从第一个父项或第二个父项中随机复制位
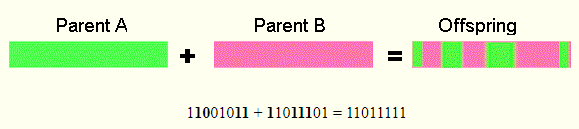
-
算术交叉 - 执行一些算术运算以产生新的后代

突变
- 位反转 - 选择的位被反转

2.置换编码
交叉
- 单点交叉 - 选择一个交叉点,将排列从第一个父项复制到交叉点,然后扫描另一个父项,如果该数字还没有在后代中,则添加它注意:还有更多方法如何在交叉点之后产生休息
(1 2 3 4 5 6 7 8 9) + (4 5 3 6 8 9 7 2 1) = (1 2 3 4 5 6 8 9 7)
变异
- 顺序更改 - 选择并交换两个数字
(1 2 3 4 5 6 8 9 7) => (1 8 3 4 5 6 2 9 7)
3.值编码
交叉
- 可以使用来自二进制编码的所有交叉
变异 - 添加一个小数字(用于实数值编码) - 将一个小数字添加到(或减去)所选值
(1.29 5.68 2.86 4.11 5.55)=>(1.29 5.68 2.73 4.22 5.55)
4.树编码
交叉
- 树交叉 - 在父母双方中选择一个交叉点,父母在该点被分割,交换点下面的部分被交换以产生新的后代
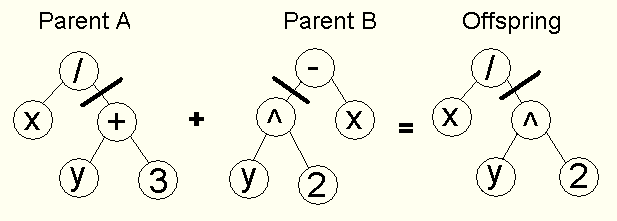
变异
- 更改运算符,数字 - 选定节点已更改
XII. 旅行推销员问题
问题前面章节中已经提到过旅行商问题(TSP)。需要提醒的是,城市之间存在距离。旅行推销员必须访问他们所有人,但他不想旅行。任务是找到一系列城市,以减少行驶距离。换句话说,在N个节点的完整图中找到最小的哈密顿游。
实现
使用16条染色体的群体。为了编码这些染色体,使用了排列编码 - 你可以在关于编码的章节中找到如何编码TSP的城市排列。 TSP在完整图形(即每个节点彼此连接)上以欧几里德距离求解。请注意,添加和删除城市后,有必要创建新的染色体并重新启动整个遗传算法。
您可以选择交叉和突变类型。其含义如下:
交叉
- 一点 - 第一个父项的一部分(即城市顺序的一部分)被复制,其余的城市采用与第二个父项相同的顺序
- 两点 - 第一个父项的两个部分被复制,其余部分之间这两个部分采用与第二个父母相同的顺序
- 无 - 没有交叉,后代是父母的精确副本
突变
- 正常随机 - 选择和交换几个城市
- 随机,只有改进 - 一些城市随机选择和交换只有当他们改善解决方案(增加适应性)
- 系统,只有改善 - 城市系统地选择和交换只有他们改善解决方案(增加适应性)
- 随机改进 - 与“随机”相同,只改善“,但在此之前,进行”正常随机“突变
- 系统性改进 - 与“系统性,仅改善”相同,但在此之前进行“正常随机”突变
- 没有 - 没有变异
示例
以下小程序显示GA优化TSP。按钮“更改视图”将视图从整个群体更改为最佳解决方案,反之亦然。您可以点击图表来添加和删除城市。添加或删除城市后,随着新的随机染色体的新种群被创建,它们之间将出现随机游览。另请注意,我们正在完整的图表上解决TSP问题。尝试运行具有不同类型的交叉和变异的GA,并注意GA的性能(和速度 - 添加更多城市以查看它)的变化。已知错误:如果您在Netscape中使用旧版本的Java,请在执行任何其他操作之前按“更改视图”按钮,否则某些图形将不会响应。
XIII.建议
GA的参数
如果您决定实施遗传算法,本章应该为您提供一些基本建议。这些建议非常笼统。您可能希望尝试使用自己的GA来解决特定问题,因为没有一般理论可以帮助您针对任何问题调整GA参数。
建议通常是对GA的经验研究的结果,这些研究通常仅在二进制编码上进行。
- 交叉率
交叉率一般应高,约为80%-95%。 (但是有些结果表明,对于某些问题,交叉率约为60%是最好的。) - 突变率
另一方面,突变率应该非常低。最佳利率似乎约为0.5%-1%。 - 人口规模
可能令人惊讶的是,非常大的人口规模通常不会改善GA的性能(从找到解决方案的速度的意义上说)。良好的人口规模约为20-30,但有时大小为50-100是最好的。一些研究还表明,最佳种群规模取决于编码字符串(染色体)的大小。这意味着如果你有32位染色体,那么人口应该高于16位染色体。 - 选择
可以使用基本的轮盘赌选择,但有时排名选择可以更好。查看有关选择优缺点的章节。还有一些更复杂的方法可以在GA运行期间更改选择参数。基本上,这些表现类似于模拟退火。如果您不使用其他方法来保存最佳找到的解决方案,则应确保使用精英主义。您也可以尝试稳态选择。 - 编码
编码取决于问题以及问题实例的大小。查看有关编码的章节以获取一些建议或查看其他资源。 - 交叉和变异
运算符取决于所选的编码和问题。查看有关操作员的章节以获取一些建议。您还可以查看其他网站。
GA的应用
遗传算法已被用于困难问题(例如NP难问题),机器学习以及不断发展的简单程序。它们也被用于一些艺术,用于演变图片和音乐。 GAs的优势在于它们的并行性。 GA正在搜索空间中使用更多的个体(并且具有基因型而不是表型),以便它们不像其他方法那样陷入局部极端。它们也很容易实现。一旦你实现了基本的GA算法,你只需编写一个新的染色体(只有一个对象)来解决另一个问题。使用相同的编码,您只需更改适应度函数 - 就完成了。然而,对于一些问题,编码和适应度函数的选择和实现可能是困难的。 GA的缺点在于计算时间。 GA可能比其他方法慢。但是我们可以随时终止计算,长时间运行是可以接受的(特别是对于速度越来越快的计算机)。
为了了解GA解决的一些问题,这里有一些应用程序的简短列表:
- 非线性动力系统 - 预测,数据分析
- 设计神经网络,包括架构和权重
- 机器人轨迹
- 不断发展的LISP计划(遗传编程)
- 战略规划
- 寻找蛋白质分子的形状
- TSP和序列调度
- 用于创建图像的功能