将DOTA标签格式转为VOC格式形成xml文件
DOTA数据集的格式为:
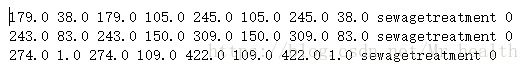
前8个数字分别为gt的4个点坐标(x、y)
转换为VOC标注的代码为:
这里有两种选择
1. 将原有的8坐标转换为4坐标的最小外界矩形,即hbb形式 xmin,ymin,xmax,ymax
2. 保留原有/坐标,即obb形式x0,y0,x1,y1,x2,y2,x3,y3
import os
import cv2
from xml.dom.minidom import Document
#windows下无需
import sys
stdi, stdo, stde = sys.stdin, sys.stdout, sys.stderr
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdin, sys.stdout, sys.stderr = stdi, stdo, stde
category_set = ['ship']
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def limit_value(a,b):
if a<1:
a = 1
if a>=b:
a = b-1
return a
def readlabeltxt(txtpath, height, width, hbb = True):
print(txtpath)
with open(txtpath, 'r') as f_in: #打开txt文件
lines = f_in.readlines()
splitlines = [x.strip().split(' ') for x in lines] #根据空格分割
boxes = []
for i, splitline in enumerate(splitlines):
if i in [0,1]: #DOTA数据集前两行对于我们来说是无用的
continue
label = splitline[8]
if label not in category_set:#只书写制定的类别
continue
x1 = int(float(splitline[0]))
y1 = int(float(splitline[1]))
x2 = int(float(splitline[2]))
y2 = int(float(splitline[3]))
x3 = int(float(splitline[4]))
y3 = int(float(splitline[5]))
x4 = int(float(splitline[6]))
y4 = int(float(splitline[7]))
#如果是hbb
if hbb:
xx1 = min(x1,x2,x3,x4)
xx2 = max(x1,x2,x3,x4)
yy1 = min(y1,y2,y3,y4)
yy2 = max(y1,y2,y3,y4)
xx1 = limit_value(xx1, width)
xx2 = limit_value(xx2, width)
yy1 = limit_value(yy1, height)
yy2 = limit_value(yy2, height)
box = [xx1,yy1,xx2,yy2,label]
boxes.append(box)
else: #否则是obb
x1 = limit_value(x1, width)
y1 = limit_value(y1, height)
x2 = limit_value(x2, width)
y2 = limit_value(y2, height)
x3 = limit_value(x3, width)
y3 = limit_value(y3, height)
x4 = limit_value(x4, width)
y4 = limit_value(y4, height)
box = [x1,y1,x2,y2,x3,y3,x4,y4,label]
boxes.append(box)
return boxes
def writeXml(tmp, imgname, w, h, d, bboxes, hbb = True):
doc = Document()
#owner
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
#owner
folder = doc.createElement('folder')
annotation.appendChild(folder)
folder_txt = doc.createTextNode("VOC2007")
folder.appendChild(folder_txt)
filename = doc.createElement('filename')
annotation.appendChild(filename)
filename_txt = doc.createTextNode(imgname)
filename.appendChild(filename_txt)
#ones#
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
source.appendChild(database)
database_txt = doc.createTextNode("My Database")
database.appendChild(database_txt)
annotation_new = doc.createElement('annotation')
source.appendChild(annotation_new)
annotation_new_txt = doc.createTextNode("VOC2007")
annotation_new.appendChild(annotation_new_txt)
image = doc.createElement('image')
source.appendChild(image)
image_txt = doc.createTextNode("flickr")
image.appendChild(image_txt)
#owner
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid = doc.createElement('flickrid')
owner.appendChild(flickrid)
flickrid_txt = doc.createTextNode("NULL")
flickrid.appendChild(flickrid_txt)
ow_name = doc.createElement('name')
owner.appendChild(ow_name)
ow_name_txt = doc.createTextNode("idannel")
ow_name.appendChild(ow_name_txt)
#onee#
#twos#
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
size.appendChild(width)
width_txt = doc.createTextNode(str(w))
width.appendChild(width_txt)
height = doc.createElement('height')
size.appendChild(height)
height_txt = doc.createTextNode(str(h))
height.appendChild(height_txt)
depth = doc.createElement('depth')
size.appendChild(depth)
depth_txt = doc.createTextNode(str(d))
depth.appendChild(depth_txt)
#twoe#
segmented = doc.createElement('segmented')
annotation.appendChild(segmented)
segmented_txt = doc.createTextNode("0")
segmented.appendChild(segmented_txt)
for bbox in bboxes:
#threes#
object_new = doc.createElement("object")
annotation.appendChild(object_new)
name = doc.createElement('name')
object_new.appendChild(name)
name_txt = doc.createTextNode(str(bbox[-1]))
name.appendChild(name_txt)
pose = doc.createElement('pose')
object_new.appendChild(pose)
pose_txt = doc.createTextNode("Unspecified")
pose.appendChild(pose_txt)
truncated = doc.createElement('truncated')
object_new.appendChild(truncated)
truncated_txt = doc.createTextNode("0")
truncated.appendChild(truncated_txt)
difficult = doc.createElement('difficult')
object_new.appendChild(difficult)
difficult_txt = doc.createTextNode("0")
difficult.appendChild(difficult_txt)
#threes-1#
bndbox = doc.createElement('bndbox')
object_new.appendChild(bndbox)
if hbb:
xmin = doc.createElement('xmin')
bndbox.appendChild(xmin)
xmin_txt = doc.createTextNode(str(bbox[0]))
xmin.appendChild(xmin_txt)
ymin = doc.createElement('ymin')
bndbox.appendChild(ymin)
ymin_txt = doc.createTextNode(str(bbox[1]))
ymin.appendChild(ymin_txt)
xmax = doc.createElement('xmax')
bndbox.appendChild(xmax)
xmax_txt = doc.createTextNode(str(bbox[2]))
xmax.appendChild(xmax_txt)
ymax = doc.createElement('ymax')
bndbox.appendChild(ymax)
ymax_txt = doc.createTextNode(str(bbox[3]))
ymax.appendChild(ymax_txt)
else:
x0 = doc.createElement('x0')
bndbox.appendChild(x0)
x0_txt = doc.createTextNode(str(bbox[0]))
x0.appendChild(x0_txt)
y0 = doc.createElement('y0')
bndbox.appendChild(y0)
y0_txt = doc.createTextNode(str(bbox[1]))
y0.appendChild(y0_txt)
x1 = doc.createElement('x1')
bndbox.appendChild(x1)
x1_txt = doc.createTextNode(str(bbox[2]))
x1.appendChild(x1_txt)
y1 = doc.createElement('y1')
bndbox.appendChild(y1)
y1_txt = doc.createTextNode(str(bbox[3]))
y1.appendChild(y1_txt)
x2 = doc.createElement('x2')
bndbox.appendChild(x2)
x2_txt = doc.createTextNode(str(bbox[4]))
x2.appendChild(x2_txt)
y2 = doc.createElement('y2')
bndbox.appendChild(y2)
y2_txt = doc.createTextNode(str(bbox[5]))
y2.appendChild(y2_txt)
x3 = doc.createElement('x3')
bndbox.appendChild(x3)
x3_txt = doc.createTextNode(str(bbox[6]))
x3.appendChild(x3_txt)
y3 = doc.createElement('y3')
bndbox.appendChild(y3)
y3_txt = doc.createTextNode(str(bbox[7]))
y3.appendChild(y3_txt)
xmlname = os.path.splitext(imgname)[0]
tempfile = os.path.join(tmp ,xmlname+'.xml')
with open(tempfile, 'wb') as f:
f.write(doc.toprettyxml(indent='\t', encoding='utf-8'))
return
if __name__ == '__main__':
data_path = '/home/yantianwang/lala/ship/train/examplesplit'
images_path = os.path.join(data_path, 'images') #样本图片路径
labeltxt_path = os.path.join(data_path, 'labelTxt') #DOTA标签的所在路径
anno_new_path = os.path.join(data_path, 'obbxml') #新的voc格式存储位置(hbb形式)
ext = '.tif' #样本图片的后缀
filenames=os.listdir(labeltxt_path) #获取每一个txt的名称
for filename in filenames:
filepath=labeltxt_path + '/'+filename #每一个DOTA标签的具体路径
picname = os.path.splitext(filename)[0] + ext
pic_path = os.path.join(images_path, picname)
im= cv2.imread(pic_path) #读取相应的图片
(H,W,D) = im.shape #返回样本的大小
boxes = readlabeltxt(filepath, H, W, hbb = True) #默认是矩形(hbb)得到gt
if len(boxes)==0:
print('文件为空',filepath)
#读取对应的样本图片,得到H,W,D用于书写xml
#书写xml
writeXml(anno_new_path, picname, W, H, D, boxes, hbb = True)
print('正在处理%s'%filename)