python爬虫-->表单交互
前几篇博文中,我们的程序下载的静态网页总是返回相同的内容。在本篇博文中,我们将与网页进行交互,根据用户输入返回对应的内容。
本篇博文将主要介绍以下两种方式进行表单交互
- 使用cookie登录网页,更新网页内容(较麻烦)
- 使用Mechanize模块实现自动化表单处理(较简单)
登录表单
打开网址http://example.webscraping.com/places/default/user/login,按F12,进入开发者模式。
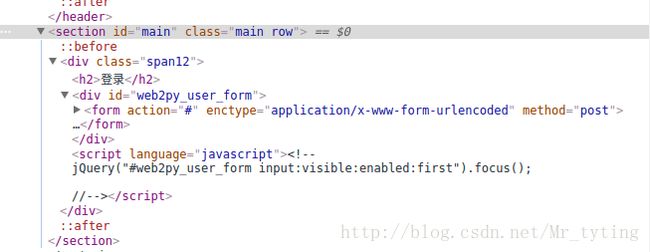
这里需要注意form标签的action,enctype,method属性以及两个input域。action:表示表单数据提交的地址。本例为#,也就是和登录表单相同的URL。enctype:数据提交的编码。method:提交方法,post表示通过请求体向服务器提交表单。input标签,重要的属性是name,用于设定提交到服务器端时某个域的名称。
当我们登录时需要提交账号密码,然后点击登录按钮才能把数据提交到服务器。下面是尝试自动化处理该流程代码。
LOGIN_EMAIL = '[email protected]'
LOGIN_PASSWORD = 'example'
LOGIN_URL = 'http://example.webscraping.com/places/default/user/login'
def login_basic():
"""fails because not using formkey
"""
data = {'email': LOGIN_EMAIL, 'password': LOGIN_PASSWORD}
encoded_data = urllib.urlencode(data)
request = urllib2.Request(LOGIN_URL, encoded_data)
response = urllib2.urlopen(request)
print response.geturl()
login_basic()打印结果为:http://example.webscraping.com/places/default/user/login
显然没有发生跳转,就是没有登录成功。
因为登录表单十分严格。除了邮箱和密码外,还需要提交另外几个域。我们编写一个函数,来提取表单中所有的input标签详情。
def parse_form(html):
"""extract all input properties from the form
"""
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data看看获取了哪些表单数据:
html = urllib2.urlopen(LOGIN_URL).read()
data = parse_form(html)
print data打印结果:
{‘remember_me’: ‘on’, ‘_formname’: ‘login’, ‘_next’: ‘/places/default/index’, ‘_formkey’: ‘3049b530-61de-43dc-b1fa-57b105b37769’, ‘password’: ”, ‘email’: ”}
这里需要注意_formkey属性,服务器端使用这个唯一的ID来避免表单多次提交。每次加载网页时,都会产生不同的ID,然后服务器端就可以通过这个给定的ID来判断表单是否已经提交过。
再把获取的所有表单数据全部进行提交,看能不能成功跳转登录
def login_formkey():
"""fails because not using cookies to match formkey
"""
html = urllib2.urlopen(LOGIN_URL).read()
data = parse_form(html)
data['email'] = LOGIN_EMAIL
data['password'] = LOGIN_PASSWORD
encoded_data = urllib.urlencode(data)
request = urllib2.Request(LOGIN_URL, encoded_data)
response = urllib2.urlopen(request)
print response.geturl()
login_formkey()打印结果
http://example.webscraping.com/places/default/user/login
很明显没有发生跳转即没有登录成功。
我们缺失了一个重要的组成部分–cookie。当普通用户加载登录界面时,_formkey的值会保存在cookie中,然后该值会和提交的登录表单数据中的_formkey进行比较。下面是使用urllib2.HTTPCookieProcessor类的代码:
def login_cookies():
"""working login
"""
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
html = opener.open(LOGIN_URL).read()
data = parse_form(html)
data['email'] = LOGIN_EMAIL
data['password'] = LOGIN_PASSWORD
encoded_data = urllib.urlencode(data)
request = urllib2.Request(LOGIN_URL, encoded_data)
response = opener.open(request)
print response.geturl()
return opener
login_cookies()打印结果:
http://example.webscraping.com/places/default/index
跳转到登录成功后的网页。成功登录。
支持内容更新的登录脚本扩展
我们利用LOGIN_EMAIL = ‘[email protected]’
LOGIN_PASSWORD = ‘example’ 登录http://example.webscraping.com/places/default/user/login,打开任意一个国家的网页,点击左下角的edit按钮。这里我们编写一个函数,每次运行这个函数时都会使得该国家人口数量加1。
import urllib
import urllib2
import mechanize
import login
COUNTRY_URL = 'http://example.webscraping.com/places/default/edit/Afghanistan-1'
def edit_country():
opener = login.login_cookies()
country_html = opener.open(COUNTRY_URL).read()
data = login.parse_form(country_html)
import pprint; pprint.pprint(data)
print 'Population before: ' + data['population']
data['population'] = int(data['population']) + 1
encoded_data = urllib.urlencode(data)
request = urllib2.Request(COUNTRY_URL, encoded_data)
response = opener.open(request)
country_html = opener.open(COUNTRY_URL).read()
data = login.parse_form(country_html)
print 'Population after:', data['population']使用Mechanize模块实现自动化表单处理
使用Mechanize模块不再需要管理cookie,而且访问表单输入框也更加容易。
def mechanize_edit():
"""Use mechanize to increment population
"""
# login
br = mechanize.Browser()
br.open(login.LOGIN_URL)
br.select_form(nr=0)
print br.form
br['email'] = login.LOGIN_EMAIL
br['password'] = login.LOGIN_PASSWORD
response = br.submit()
print response.geturl()##打印输出http://example.webscraping.com/places/default/index登录成功
# edit country 更新内容
br.open(COUNTRY_URL)
br.select_form(nr=0)
print 'Population before:', br['population']
br['population'] = str(int(br['population']) + 1)##注意要字符串类型的值,否则会抛出TypeError
br.submit()
# check population increased
br.open(COUNTRY_URL)
br.select_form(nr=0)
print 'Population after:', br['population']