实体识别和关系抽取的联合模型总结
实体识别和关系抽取的目标是从非结构化的文本中发现(实体1、关系、实体2)的三元组,它对知识库的构建和问答任务都很重要,是信息抽取的核心问题。
现有的关系抽取方法主要有两种:
1.使用流水线方法进行抽取:先对句子进行实体识别,然后对识别出的实体两两组合,再进行关系分类,最后把存在实体关系的三元组做为输入。
缺点:1.错误传播,实体识别模块的错误会影响下面的关系分类性能。2.差生了没必要的冗余信息,没有关系的实体会带来多余信息,提升错误率。
2.实体识别和关系抽取的联合模型:对句子同时做实体识别和关系抽取得到一个有关系的实体三元组。
模型结构图:

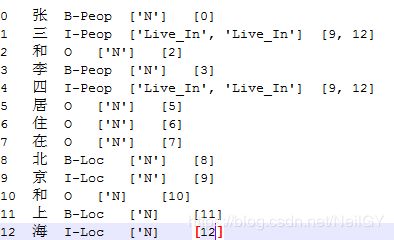
数据标记策略:采用BIO标记策略。字在句子中的下标(token_id),字(token),标注标签(BIO),实体关系(无关系则为N)(relations),对应关系下标位置(无关系则为当前下标)(heads)。
比如有如下一句话:张三和李四居住在北京和上海,姓名和地址有live_in关系,标记位置为地址最后一个字的下标。
数据预处理:
1.读取所有数据,获得字的部首的全集chars_set,实体标签的全集bios_set,关系的全集relations_set。
2.遍历训练数据,将每个句子中token_id,token,bio,relations,heads作为列表封装到该句子中。再遍历当前句子将样本数据id化,将句子中字列表embedding_ids,偏旁部首id的列表char_ids,实体标签的列表bio_ids,关系的列表scoringMatrixHeads封装到句子中。其中scoringMatrixHeads的获得:
1).先获取关系relations的ids,id从relations_set全集里边对应。比如‘三’对应['Live_In', 'Live_In'],而Live_In在relations_set中下标为3,则relations对应的ids为[3,3]
2).遍历字对应关系relations的列表,将heads*len(relations_set)+relations。比如‘三’对应relations为[23,23],对应heads为[9,12],relations_set长度为10,则scoringMatrixHeads=[9*10+3,12*10+3]=[93,123]
3.处理句子id化的数据,使其在一个批量数据内每个句子的维度相等,已最长句子的维度作为最大维度,不足的填充0。其中scoringMatrixHeads关系的处理需要特别说明一下,先初始化一个 [句子长度,句子长度*len(relations_set)]的0矩阵scoringMatrix,遍历scoringMatrixHeads,将每个字的通过步骤2计算出来的id作为scoringMatrix矩阵的列向量 填充1,用1来表示字与字之间的关系。
模型结构:
1.word Embedding层:先初始化偏旁部首char_ids权重参数,词嵌入,通过双向LSTM提取特征得到char_logitics。加载skip-gram模型预训练的字向量,得到word embedding,将word embedding和char_logitics拼接作为模型的输入inputs。
2.双向LSTM层:通过三个隐藏层的双向LSTM对输入的inputs进行特征提取得到lstm_out。
3.对lstm_out做激活函数为relu的全连接,进行实体分类,得到nerScores
4.通过BIO标记策略,使用CRF引入标签间的依赖关系。1.计算每个词得到不同标签的分数。2.计算句子的标签序列概率。通过最小化交叉熵损失函数得到ner_loss。最后使用viterbi算法得到分数最高的标签preNers。
5.对步骤4得到的labels(训练则用真实标签,测试则用预测的标签preNers)进行词嵌入得到label Embedding,将步骤2中输出的lstm_out和label Embedding拼接得到rel_inputs,作为实体关系预测的输入。
6.通过下列公式计算每个词最有可能对应的关系和头向量(即为样本中的relations和heads)得到rel_scores。

7.对得到的rel_scores与数据预处理中得到的scoringMatrix矩阵做sigmod交叉熵,得到损失rel_loss。对rel_scores做sigmod预测实体关系得到pre_Rel。
8.对抗训练层:通过在原来的embedding上加入最坏的扰动使损失函数最大,来得到对抗样本。
噪音数据:损失对词向量求导,再L2正则化,再乘以一个系数。
使用如下公式得到最终损失:

9.使用Adam优化函数优化损失。