如何理解梯度下降法
前面的文章「机器学习入坑指南(三):简单线性回归」中提到,梯度下降法是一种常用的迭代方法,其目的是让输入向量找到一个合适的迭代方向,使得输出值能达到局部最小值。在拟合线性回归方程时,我们把损失函数视为以参数向量为输入的函数,找到其梯度下降的方向并进行迭代,就能找到最优的参数值。
一、一元函数与导数
一元函数可以看成是平面上的函数。设一次函数形式为 y = k x + b y = kx + b y=kx+b,图像如下
可以看出,如果要通过迭代(取不同的 x x x 值代入方程)的方式找出最小的 y y y 值,我们实际上只有两个方向可以选择,即 x x x 轴的正向或负向。于是,只要做出一次尝试,就知道该往哪个方向迭代。
在定义域有限的情况下,一次函数的局部最值就是全局最值。而对于多次函数来说,可能有多个局部最值,而三角函数则不用考虑定义域······
总而言之,不管平面上的函数是什么形式,为了找到其局部最值,我们都只用考虑向前向后两个方向。
实际上,我们可以求得函数在某一点处的导数,如果它是正的,则说明向前迭代会使函数值增大,反之则减小。导数的意义,及函数在某一点处的斜率。
二、二元函数与梯度
1 如何寻找正确的迭代方向?
对三维空间中的二元函数 z = f ( x , y ) z = f(x,y) z=f(x,y) 来说,函数图像上点可以向其周围 360°的方向运动,而不是简单地向前、向后、向左、向右。进行迭代的自变量,也不再是一个一维的数字,而是二维的向量。
我们固然可以像上面那样,任意找出一个方向,只要使 f ( x , y ) f(x,y) f(x,y) 的值是减小的就可以,但如果在无数个方向中只有极少的一部分能达到这个目的呢?任意蒙出来的几率有点低吧?就算蒙出来了, f ( x , y ) f(x,y) f(x,y) 在这个方向上减小到头(收敛)了,你能证明往 360° 的任意一个方向再走不会再减小了吗?于是,你需要再次蒙出一个方向去迭代······
显然,蒙这种方式不靠谱,而且根本体现不出逼格来,我们得找到一个从数学上说的通的方法才行。
2 什么是梯度?
假设我们在山上想下山,观察了观察四周,发现咦有好几个向下的坡,左前方这个坡太缓了,下山得老半天,右前方这个还行,我从这儿走。对于一般人来说,坡度不能太陡,但科学嘛,是对生活的提炼与升华,所以数学上的这个人就像怪物猎人一样从多高的地方跳下去都死不了,于是他老是找最陡的坡走、滑行或者跳下去,最后,他很快地到了山下,当然,运气背的时候他会发现自己到了一个山谷。。。
所谓梯度,就是上面的故事中猎人找到的最陡的坡的陡峭程度。当然,它不仅有大小,还有方向,是一个向量。那么我们如何找到这个向量呢?
我们可以求得函数图像上的任意一点处的偏导数 f x ( x , y ) f_x(x,y) fx(x,y) 和 f y ( x , y ) f_y(x,y) fy(x,y)。同时,在自变量组成的平面空间中,任意取一个单位向量:
u = c o s θ i + s i n θ j u = cos\theta i + sin\theta j u=cosθi+sinθj
其中 θ \theta θ 是该向量与 x x x 轴的夹角, i i i、 j j j 分别是 x x x、 y y y方向上的单位向量。那么沿着 u u u 方向变化 t t t ,相当于沿着 x x x 方向变化了 $tcos\theta $,同时沿着 y y y 方向变化了 t s i n θ tsin\theta tsinθ。
接下来,我们要求函数在这个向量方向上的变化率,称为方向导数,即
U = lim t → 0 f ( x 0 + t c o s θ , y 0 + t s i n θ ) − f ( x 0 , y 0 ) t U = \lim _{t \to 0}\frac{f(x_0 + tcos\theta, y_0 + tsin\theta) - f(x_0, y_0)}{t} U=t→0limtf(x0+tcosθ,y0+tsinθ)−f(x0,y0)
根据全微分公式,
lim t → 0 f x ( x 0 , y 0 ) t c o s θ + f y ( x 0 , y 0 ) t s i n θ t = f x ( x 0 , y 0 ) c o s θ + f y ( x 0 , y 0 ) s i n θ \lim _{t \to 0}\frac{f_x(x_0,y_0)tcos\theta + f_y(x_0,y_0)tsin\theta}{t} = f_x(x_0,y_0)cos\theta + f_y(x_0,y_0)sin\theta t→0limtfx(x0,y0)tcosθ+fy(x0,y0)tsinθ=fx(x0,y0)cosθ+fy(x0,y0)sinθ
设 A = ( f x ( x 0 , y 0 ) , f y ( x 0 , y 0 ) ) A =(f_x(x_0,y_0),f_y(x_0,y_0)) A=(fx(x0,y0),fy(x0,y0)) , I = ( c o s θ , s i n θ ) I = (cos\theta,sin\theta) I=(cosθ,sinθ),则
U = A ⋅ I = ∣ A ∣ ∣ I ∣ c o s α ≤ ∣ A ∣ ∣ I ∣ U = A\cdot I = |A||I|cos\alpha \leq|A||I| U=A⋅I=∣A∣∣I∣cosα≤∣A∣∣I∣
也就是说,当 A A A 和 I I I 共线时,方向导数能取到最大值,故而向量 ( f x ( x 0 , y 0 ) , f y ( x 0 , y 0 ) ) (f_x(x_0,y_0),f_y(x_0,y_0)) (fx(x0,y0),fy(x0,y0)),即 ( ∂ f ∂ x , ∂ f ∂ y ) (\frac{\partial f}{\partial x},\frac{\partial f}{\partial y}) (∂x∂f,∂y∂f) 就是我们要寻找的梯度,其方向代表函数某点处变化率最大的方向,大小(模)代表变化率的值。二元函数的梯度通常用 ∇ f ( x , y ) \nabla f(x,y) ∇f(x,y) 或 g r a d f ( x , y ) grad f(x,y) gradf(x,y) 表示。
这个结论可以推广到多元,不管输入有多少,我们都可以把它们视为一个向量,从而通过梯度来找到迭代的方向。
三、梯度下降法应用举例
以「斯坦福大学机器学习教程——线性回归」为例。
首先,给出线性回归的模型
h θ ( x ) = θ 0 + θ 1 x h_\theta(x) = \theta_0 + \theta_1x hθ(x)=θ0+θ1x
假设我们用来拟合的数据共有 m m m 组,根据最小二乘法,我们实际要找出令
∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})^2 i=1∑m(hθ(x(i))−y(i))2
最小的 θ \theta θ 值,其中上标 ( i ) (i) (i) 代表是第几组数据。设关于 θ \theta θ 的损失函数
J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})^2 J(θ)=21i=1∑m(hθ(x(i))−y(i))2
θ \theta θ 可以看做是一个参数向量,即 { θ 0 , θ 1 } T \{\theta_0, \theta_1\}^T {θ0,θ1}T。式子的前面乘上系数,是为了方便计算。
根据前面梯度的概念,我们得到
∇ J ( θ ) = ( ∂ J ( θ ) ∂ θ 0 , ∂ J ( θ ) ∂ θ 1 ) \nabla J(\theta) = (\frac{\partial J(\theta)}{\partial \theta_0},\frac{\partial J(\theta)}{\partial \theta_1}) ∇J(θ)=(∂θ0∂J(θ),∂θ1∂J(θ))
也就是说,为了使损失函数达到局部最小值,我们只需要沿着这个向量的反方向进行迭代即可。
那么参数的值到底该一次变化多少呢?我们通常用 α \alpha α 来表示这个大小,称为**“步长”**,它的值是需要我们手动设定的,显然,步长太小,会拖慢迭代的执行速度,而步长太大,则有可能在下降时走弯路或者不小心跳过了最优解。所以,我们应该根据实际的情况,合理地设置 α \alpha α 的值。
于是,在每次迭代,中,我们令
θ 0 = θ 0 − α ∂ J ( θ ) ∂ θ 0 , θ 1 = θ 1 − α ∂ J ( θ ) ∂ θ 1 \theta_0 = \theta_0 - \alpha\frac{\partial J(\theta)}{\partial \theta_0},\theta_1 = \theta_1 - \alpha\frac{\partial J(\theta)}{\partial \theta_1} θ0=θ0−α∂θ0∂J(θ),θ1=θ1−α∂θ1∂J(θ)
即可使损失函数最终收敛到局部最小值,我们也得到了我们想要的参数值。这个过程如下图
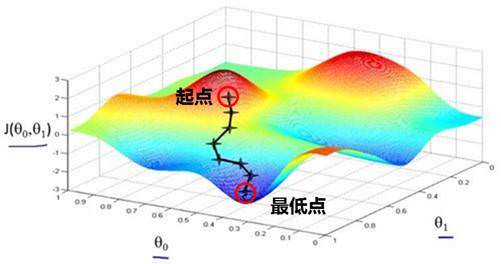
最后,为了加快梯度下降法的执行速度,我们可以对它进行改进,如采用随机梯度下降法等,感兴趣的同学可以搜索相关文章,这里不再赘述。