Go使用MongoDB:采用Docker
安装MongoDB
在控制台输入:
sudo docker pull mongo
cd ~
mkdir -p docker
cd docker
mkdir -p mongo mongo/db
sudo docker run --name mongodb-server0 -v ~/docker/mongo:/data/db -p 27017:27017 -d 0fb47b43df19 --auth
其中 0fb47b43df19 是镜像id,通过sudo docker images 查看
创建MongoDB用户
首先,进入mongodb 控制台
sudo docker exec -it 5f8c9c467001 mongo admin
(其中 5f8c9c467001 是container id,通过 sudo docker ps -a 查看)
然后创建用户
db.createUser({ user: ‘Niko’, pwd: ‘???’, roles: [ { role: “userAdminAnyDatabase”, db: “admin” } ] });
之后可以通过 db.auth(‘Niko’, ‘???’) 认证(认证后可以获得插入数据,创建用户等权限)
创建用户的role角色,参考 ref:https://www.jianshu.com/p/3a8c1904e807
到此,mongodb即安装配置完成
测试mongodb
首先,进入mongodb 控制台
sudo docker exec -it 5f8c9c467001 mongo admin
其次,尝试插入数据
use medex
db.createUser({ user: ‘temp’, pwd: ‘temp’, roles: [ { role: “readWrite”, db: “medex” } ] });
db.auth(‘temp’,‘temp’)
db.newcollection.insert({test : true})
如果显示插入成功,则一切正常
GO驱动配置
首先获得包
go get gopkg.in/mgo.v2
其次运行测试代码
package main
import (
"fmt"
"log"
"gopkg.in/mgo.v2"
"gopkg.in/mgo.v2/bson"
)
type Student struct {
Name string
Phone string
Email string
Sex string
}
func ConnecToDB() *mgo.Collection {
session, err := mgo.Dial("127.0.0.1:27017")
if err != nil {
panic(err)
}
//defer session.Close()
session.SetMode(mgo.Monotonic, true)
db := session.DB("medex")
db.Login("Niko", "12345")
c := db.C("student")
return c
}
func InsertToMogo() {
c := ConnecToDB()
stu1 := Student{
Name: "zhangsan",
Phone: "13480989765",
Email: "[email protected]",
Sex: "F",
}
stu2 := Student{
Name: "liss",
Phone: "13980989767",
Email: "[email protected]",
Sex: "M",
}
err := c.Insert(&stu1, &stu2)
if err != nil {
panic(err)
}
}
func GetDataViaSex() {
c := ConnecToDB()
result := Student{}
err := c.Find(bson.M{"sex": "M"}).One(&result)
if err != nil {
log.Fatal(err)
}
fmt.Println("student", result)
students := make([]Student, 20)
err = c.Find(nil).All(&students)
if err != nil {
log.Fatal(err)
}
fmt.Println(students)
}
func GetDataViaId() {
id := bson.ObjectIdHex("5a66a96306d2a40a8b884049")
c := ConnecToDB()
stu := &Student{}
err := c.FindId(id).One(stu)
if err != nil {
log.Fatal(err)
}
fmt.Println(stu)
}
func UpdateDBViaId() {
//id := bson.ObjectIdHex("5a66a96306d2a40a8b884049")
c := ConnecToDB()
err := c.Update(bson.M{"email": "[email protected]"}, bson.M{"$set": bson.M{"name": "haha", "phone": "37848"}})
if err != nil {
log.Fatal(err)
}
}
func RemoveFromMgo() {
c := ConnecToDB()
_, err := c.RemoveAll(bson.M{"phone": "13480989765"})
if err != nil {
log.Fatal(err)
}
}
func mongotest() {
InsertToMogo()
}
参考 ref : https://www.cnblogs.com/dfsxh/p/10207110.html
Mongo学习
mongo数据库的创建
隐式创建
即 直接 use newdatabase 就可以直接创建并切换
创建collection
db.createCollection(‘user’)
给collection插入值
db.user.insert({name:‘Niko’, age:22})
数据库查找(相当于select)
db.user.find()
会得到:
{ "_id" : ObjectId("5cfb15ce81ed7253352bb155"), "name" : "Niko", "age" : 22 }
其中 _id 是可以指定的
db.user.insert({ “_id” : 3, “name” : “Jenny”, “age” : 23 })
mongo的collection也是隐式创建
可以直接
db.goods.insert(xxx)
直接创建goods
删除表
db.user.drop()
删除数据库
先 use dbname 切换到数据库
然后db.dropDatabase()
Mongo 的 CURD 操作
切换数据库
use test
增加一篇文档
db.stu.insert({sn:‘001’, name:‘Niko’})
同时增加多篇文档
db.stu.insert([ {name:‘Jenny’}, {name:‘Pony’} , {name:‘Nana’} ])
删除文档
db.stu.remove({name:‘Pony’})
删除name为Pony的文档
remove 命令默认会把所有匹配到的文档全部删除
Update操作
db.stu.update({name:‘Niko’}, {sn:‘001’, name:‘Niko’, age:23})
参数1为查询条件文档
参数2为要替换成新的文档
如果只是要更新一部分
db.stu.update({name:‘Niko’}, {$set: {age:22}})
和 $set 相关的有
$unset : 删除一个属性
db.stu.update({name:‘Niko’}, {$unset: {age:1}})
$rename : 重命名一个属性
db.stu.update({name:‘Niko’}, {$rename: {sn:‘sno’}})
$inc : 自增一个属性的值
db.stu.update({name:‘Niko’}, {$inc: {age:16 })
一起做
db.stu.update({name:‘Niko’}, {$set: {age:22}, $rename: {sn:‘sno’} , $inc: {age:16 } })
update即使匹配到了多个文档,也只会更新一个文档
如果想更新所有匹配的文档
db.stu.update({gender:‘m’}, {$set: {gender:‘male’}} , {multi:true})
upsert 操作
如果已有匹配到的文档,则update 更新
如果没有,则创建文档
db.stu.update({gender:‘m’}, {$set: {gender:‘male’}} , {upsert:true})
配合使用的字段 $setOnInsert
当模式为upsert,且发生insert时,补充插入的字段
db.stu.update({name:‘Gogo’}, {$set: {gender:‘male’}, $setOnInsert:{sn:‘002’, age:23}} , {upsert:true})
查询
查所有文档的gender属性值(默认会带上 _id)
db.stu.find({}, {gender:1})
查所有文档的gender属性值,但是不查_id值
db.stu.find({}, {gender:1, _id:0})

查所有性别是male的文档的名字
db.stu.find({gender:‘male’}, {name:1, _id:0})
查找姓名不是 Niko 的所有文档
db.stu.find({name:{$ne:‘Niko’}})
查找年龄大于20的所有文档
db.stu.find({age:{$gt:20}})
查找年龄小于20的所有文档
db.stu.find({age:{$lt:20}})
同理 :gte 是大于等于, lte是 小于等于
查找名字是 Niko或者Jenny的文档
db.stu.find({name:{$in:[‘Niko’, ‘Jenny’]}})
查找名字不是Niko也不是Jenny的文档
db.stu.find({name:{$nin:[‘Niko’, ‘Jenny’]}})
查找年龄大于20且小于25的所有文档
{$and:[ {age:{$gt:20}}, {age:{$lt:25}} ]}
db.stu.find( {$and:[ {age:{$gt:20}}, {age:{$lt:25}} ]} )
$nor 命令 当且仅当其判断的条件都不成立时 才为真
{$nor:[ {age:{$gt:20}}, {age:{$lt:25}}, {name:{$ne:'Niko'}} ]}
取模 取出所有年龄对5求余数得到0的所有文档
db.stu.find({age: {$mod:[5,0] }})
查出存在gender属性的所有文档
db.stu.find({gender:{$exists:1}})
查看gender属性是字符串类型的所有文档
db.stu.find({gender:{$type:2}})
其中 数值2 再官网查询对应类型
$all 表示指定的元素必须出现
比如
db.stu.find({hobby: {$all : ['basketball', 'books']}})
插叙到的文档是包括’basketball’, ‘books’ 的(也可以包括其他的)
低效率查询
$where 相当于mysql的where
db.stu.find({$where:'this.age>20 && this.age < 500'})
$regex 正则表达式
db.stu.find( name : {$regex : '/^Nik.*/'} )
查询子文档
比如有一个数据
{product : ‘Nokia’, price :5000, spc : {area:‘taiwan’, weight:200}}
现在要查子文档中 area为台湾的文档
dp.goods.find(‘spc.area’ : ‘taiwan’)
索引
建立索引
db.stu.ensureIndex({name: 1})
建立唯一索引
db.collection.ensureIndex({filed.subfield:1/-1}, {unique:true});
比如 db.stu.ensureIndex({name:1}, {unique:true}) 会失败
因为 有多个文档的gender 值是一样的,不满足唯一,无法建立索引
在这种索引方式下
db.stu.find({gender: null}) 可以找到不具有gender这个属性的文档
建立稀疏索引
db.stu.ensureIndex({name:1}, {sparse:true})
如果 某个文档不含有 name 这个属性,将不对这个文档索引
在这种索引方式下
db.stu.find({gender: null}) 不能找到不具有gender这个属性的文档
哈希索引
db.stu.ensureIndex({name:1}, {hashed :true})
速度不一定最快,比如再范围查询,顺序查询之类的情景
重建索引
一个表经过很多次修改后,导致表的文件产生空洞,索引文件也如此.
可以通过索引的重建,减少索引文件碎片,并提高索引的效率.
类似mysql中的optimize table
db.collection.reIndex()
管理
mongo以每个数据库为单位进行管理,即每个数据库都有其自己的管理员
因此,要先
use database
db.addUser(用户名,密码,是否只读)
如果 use admin 再db.addUser 那么添加的用户是超级用户,可以登录任何其他数据库
但是需要 使用 --auth
sudo docker run --name mongodb-server0 -v ~/docker/mongo:/data/db -p 27017:27017 -d 0fb47b43df19 --auth
sudo docker exec -it 69f10e116b4b mongo admin
db.createUser({ user: ‘Niko’, pwd: ‘12345’, roles: [ { role: “userAdminAnyDatabase”, db: “admin” } ] });
db.createUser({ user: ‘Niko’, pwd: ‘12345’, roles: [ { role: “readWrite”, db: “medex” } ] });
副本集
多个服务器,其中有一个为primary,其他为secondary
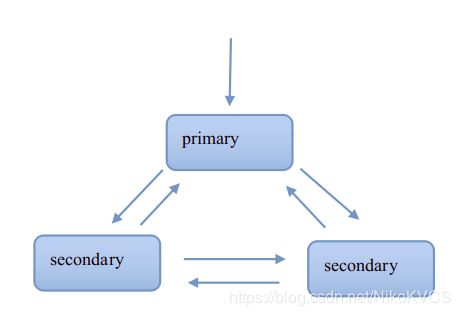
在启动的时候
服务器1:
./bin/mongod --port 27017 --dbpath /data/r0 --smallfiles --replSet rsa --fork --logpath /var/log/mongo17.log
服务器2:
./bin/mongod --port 27018 --dbpath /data/r1 --smallfiles --replSet rsa --fork --logpath /var/log/mongo18.log
服务器3:
./bin/mongod --port 27019 --dbpath /data/r2 --smallfiles --replSet rsa --fork --logpath /var/log/mongo19.log
在3个服务器上启动的mongodb 要指定 --replSet rsa 同一个副本集 rsa
其中,在primary的服务器,要配置信息:
rsconf = {
_id:'rsa',
members:
[
{_id:0,
host:'192.168.1.201:27017'
}
]
}
根据配置做初始化
rs.initiate(rsconf);
添加节点
rs.add(‘192.168.1.201:27018’);
rs.add(‘192.168.1.201:27019’);
分片
一共需要mongos服务,configsvr服务,还有shard服务
可以分散在多个服务器
比如 A B C 三个服务器
**部署环境:**3台机子
A:配置服务器1,2,3、路由1、分片1;
B:分片2,路由2;
C:分片3

给路由器mongos 配置 配置服务器configsvr
./bin/mongos --port 30000 \
--dbconfig 192.168.1.201:27020,192.168.1.202:27020,192.168.1.203:27020
给mongos添加分片节点服务器
>sh.addShard(‘192.168.1.201:27017’);
>sh.addShard(‘192.168.1.203:27017’);
>sh.addShard(‘192.168.1.203:27017’);
开启分片功能:sh.enableSharding(“库名”)、sh.shardCollection(“库名.集合名”,{“key”:1})
Field是collection的一个字段,系统将会利用filed的值,来计算应该分到哪一个片上.
这个filed叫”片键”, shard key
默认的片存储规则
优先存到一个片上,当这个片的chunk数目和其他片的chunk数目差别比较大时,把这个片的chunk移到其他片去,从而使各个片chunk数目保持平衡 (会增加额外IO)
chunk默认比较大,64m
如果想按照其他方式存储分片,可以预先分片
定义以userid为片键
sh.shardCollection(‘shop.user’,{userid:1});
userid 每1K 存一个chunk,这些chunk是空的,但是会平均分配到各个片
for(var i=1;i<=40;i++) { sh.splitAt(‘shop.user’,{userid:i*1000}) }
之后存储时,直接存到对应的片的对应的chunk上面