基于caffe的googlenet的多标签检测
本文是进一步继续上文基于googlenet inception v3模型的多标签检测的研究,上文的链接为基于Inception v3多标签训练,当博主用该模型训练结果时,会出现测试数据集准确率远低于训练准确率,例如博主就用该模型训练了一个多标签数目总共200多个,而训练数据集总共13000张图片,测试集为3000张图片,此时训练的准确度高达100%,而且迭代次数50次就达到了96%,测试的准确度却只有45%,低的可怜,查阅了一下各种相关内容,总结了产生这样的一个结果主要有几个方面:
- 训练集太少,而训练参数过多,模型产生了过拟合;
- 该inception v3模型只训练最后的输出层,这样会使产生训练的准确度及测试的准确度不高;
- 该模型所使用的优化方法为SGD,使用其它的优化方法可能会产生更好的效果。
- 使用更多的训练集,不过这需要人工进行标注,耗费人力资源;
- 引入dropout以及正则化,这两项对于解决过拟合问题具有一定的效果;
- 使用生成式对抗神经网络,但是一般使用生成式对抗神经网络需要原始的数据集很大,才能生成与数据集具有相似信息的图片;
- 采用更好的优化方法;
- 更换多标签训练模型;
每个图片均有三个标签,分别是车的type,year,name。
打开github上的lable_map.txt,可以看见图片的多标签名称,如audi tt hatchback 2011 00000,其中audi tt为车的name,hatchback为车的type,2011位车的year标签,最后的00000为图片目录,目录为00000里的图片的标签均为audi tt hatchback 2011,例如001465.jpg该图片的所在目录就为00000,它的标签为audi tt hatchback 2011。
现在需要对车进行标注,在文件new_label_train中我们可以看到标记的样式,例如00032/003913.jpg 15 8 39,表示00032目录下的003913.jpg的标签为15(year标签),8(type标签),39(name)标签,其中15对应与label1.txt文件中的索引为15标签(从0开始)即2012,同理可知8为label2.txt文件中的索引为8的标签即sedan,39位label3.txt文件中索引号为39的标签即buick verano。
修改caffe配置
caffe默认只支持单标签的分类,为此我们需要修改配置。此时我们需要将caffe中默认的convert_imageset.cpp删除,并将github中的convert_
multilabel.cpp以及car_multi/data/classification_multilabel.cpp放置在caffe的tools文件夹中,然后重新编译环境
使用如下命令行重新编译环境:
make clean
make all
make test
make pycaffe
make runtest那么此时我们便配置好了caffe环境,caffe可以进行多标签训练了。
生成lmdb文件以及binaryproto文件
现在我们需要生成图片的lmdb文件以及binaryproto文件,这和单标签生成lmdb文件以及binaryproto文件方法相同。
生成lmdb文件时,我们需要的数据有数据集,以及它们的标签如new_label_train.txt和new_label_test.txt。我们可以看到github中car_multi/create_imagenet.sh,你需要修改其中的路径,主要修改的是TRAIN_DATA_ROOT,TOOLS,VAL_DATA_ROOT,以及修改参数resize_height,和resize_width,几个参数我解释一下。–resize_height=227 –resize_width=227 代表将图像缩放到227*227,TRAIN_DATA_ROOT/是目录,TRAIN_DATA_ROOT/new_label_train.txt是你的标注所在的地方,TRAIN_DATA_ROOT/imagenet_train_lmdb和TRAIN_DATA_ROOT/imagenet_train_label是要生成的lmdb文件夹,最后一个3代表着你这里有3类标签。修改完成之后使用命令行
sh create_imagenet.sh那么将会生成 lmdb 文件以及label文件。

然后再根据label文件以及lmdb文件生成binaryproto文件,此时你需要修改的是make_imagenet_mean.sh,将更换此文换中的DATA以及TOOLS的绝对路径.
然后使用命令行
sh make_imagenet_mean.sh那么将会生成两个文件 imagenet_mean.binaryprot o 以及 imagenet_test_mean.binaryprot o。
开始训练模型
有了binaryproto文件之后我们可以开始训练模型,我们的训练网络已经给出googLeNet_multilabel.prototxt,关于这个网络你可以使用http://ethereon.github.io/netscope/#/editor查看网络的结构关系,当你需要训练自己的网络时,需要修改slice层,以及loss1/car_year,loss1/car_type,loss1/car_name,loss1/accuracy_year,loss1/loss_year,loss1/accuracy_type,loss1/loss_type,
loss1/accuracy_name,loss1/loss_name,
loss2/car_year,loss2/car_type,loss2/car_name,loss2/accuracy_year,loss2/loss_year,loss2/accuracy_type,loss2/loss_type,
loss2/accuracy_name,loss2/loss_name,
loss3/car_year,loss3/car_type,loss3/car_name,loss3/accuracy_year,loss3/loss_year,loss3/accuracy_type,loss3/loss_type,
loss3/accuracy_name,loss3/loss_name等层,
训练模型的配置文件也已经给出,solver_googlenet.prototxt为网络的配置文件,最好使用GPU训练,该模型迭代300000次,博主试过只用CPU进行
训练,结果周末放在服务器上训练了两天才迭代了40000次,所以最好不要使用CPU进行训练,是在太慢了,使用GPU估计一晚上就解决了,另外训练的
shell文件为car_multi/data/train_caffenet.sh,修改其中的绝对路径,然后使用命令行
sh train_caffenet.shnohup命令行
nohup sh train_caffenet.sh &这样模型训练的输出日志就会形成一个nohup.out文件,如car_multi/data/nohup.out,你可以使用vi nohup.out查看也可以使用记事本查看。
当训练完模型之后,会出现googLenet_fine_tuning文件夹,该文件夹中包含了训练好的模型,我们需要使用googLenet_iter_300000.caffemodel进行图片检测。
测试单张图片
当我们训练好了模型之后一定迫不及待的想检测一下训练的结果,首先测试单张图片是否可行,下面介绍两种方法进行单张图片的检测:
- 使用classification_multilabel.cpp进行单图片检测

然后运行命令行
sh test_caffenet.sh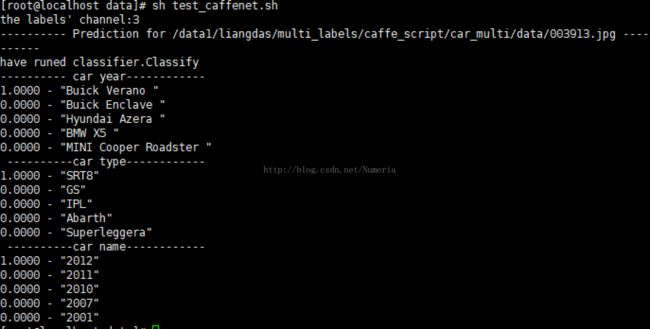
2.使用python与caffe的接口classifier.py进行检测
默认的classifier.py文件是python中定义的classifier,它用来预测输出结果,但它默认也是只输出单个标签,为此我们需要对它进行一些修改,修改内容已在github上给出,对于不同数目的输出标签需要不同的修改该文件,读者可以根据博主的classifier.py文件和caffe默认的classifier.py文件进行对比,找出需要修改的位置进行修改。并替换掉caffe中默认的classifier.py文件。
配置好classifier.py文件后,我们使用car_multi/data/pycaffe_multilabel.py文件进行预测。
在检测之前会有一个问题就是python中的googlenet使用的均值二进制文件不为binaryproto文件,而是npy文件,为此我们需要将binaryproto文件转换成npy文件,因此使用car_multi/data/binary2npy.py脚本进行转换。
直接使用命令行
python binary2npy.py这时会生成npy文件如car_multi/data/mean.npy
博主的pycaffe_multilabe.py是用来检测多张图片的,用于检测集测试的准确率,对于单张图片,只需要将main函数内容修改如下即可:
if __name__=='__main__':
recognition_obj = Recogniton() #initial an object
googlenet = recognition_obj.load_net()
#ssd_transformer = recognition_obj.ssd_transformer(ssdnet)
#label_map = resnet.load_label_map()
start=datetime.datetime.now()
image_path='/data1/liangdas/multi_labels/caffe_script/car_multi/data/003913.jpg'
image=caffe.io.load_image(image_path)
predictions = googlenet.predict([image])
print ('have run classifier.Classify')
print ('---------- car name---------')
print ('the predict name number is %d)'%proba_name)
proba_name = predictions[0].argmax()
print ('---------- car type---------')
print ('the predict type number is %d)'%proba_type)
proba_type = predictions[1].argmax()
print ('----------car year----------')
print ('the predict year number is %d)'%proba_year)
proba_year = predictions[2].argmax()
end=datetime.datetime.now()
print (end-start)修改上述图片路径,然后使用命令行
python pycaffe_multilabel.py即可以进行单张图片检测 。
检测测试集
当检测测试集时使用pycaffe_multilabel脚本会方便很多,例如博主要检测3314张图片的检测集,利用pycaffe_multilabel脚本即可以运行处结果,输出的日志在car_multi/data/result_test_log.txt中,我们可以看到检测的最终多个标签均一致的数目为2967,检测的准确率为89.6%,这个结果还是可以的。