使用logstash中的grok插件解析apache日志输出至elasticsearch
在实际应用中,我们可能会对apache产生的请求访问日志进行解析,对其中的一些数据进行处理。我们可以使用Logstash中提供的grok插件(该插件是针对apache的日志,里面可以帮我们自动识别一些信息)对数据格式进行处理,并将数据输出到elasticsearch。
关于elk的搭建,可以参考这篇:https://blog.csdn.net/QYHuiiQ/article/details/87538141
1.启动elasticsearch
由root切换至elasticsearch用户:elssearch(该用户在之前我们已经创建好了)
[elssearch@localhost elk-kafka]$ cd elasticsearch-6.6.0
[elssearch@localhost elasticsearch-6.6.0]$ cd bin
[elssearch@localhost bin]$ ./elasticsearch
![]()
启动成功,访问页面:
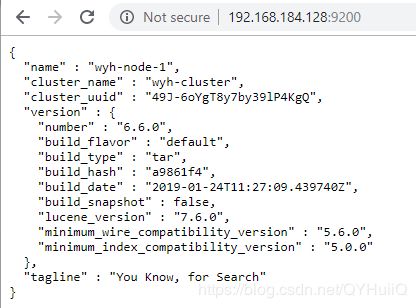
2.启动kibana:
[root@localhost elk-kafka]# cd kibana-6.6.0-linux-x86_64/bin
[root@localhost bin]# ./kibana启动成功后访问5601端口:
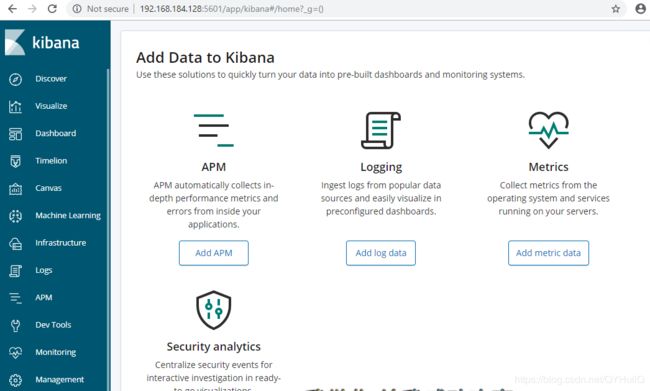
3.配置logstash:
3.1我们要对apache的log进行解析,这里我就创建一个文件里面复制了一下apache格式的log(我这里的log存放路径:/usr/local/wyh/elk-kafka/apache-log/apachelog.txt)。
假设log中有一条记录:
192.168.184.128 - - [12/Apr/2019:16:47:37 -0400] Second:18 "POST /index/article?writer=wyh&articleid=jsd_kojb_91.43.68_2548_33_87_3849 HTTP/1.1" 200 658 "-" "Java/1.8.0_51"3.2进入logstash的config目录下创建配置解析log的配置文件:
[root@localhost config]# vi wyh-apache-log.confinput{
file{ --从文件中读取
path => "/usr/local/wyh/elk-kafka/apache-log/apachelog.txt" --要解析的log路径
type => "apachelog" --自定义一个type
start_position => "beginning" --从文件起始位置读起
}
}
filter{
grok{ --logstash自带的filter插件,用来解析apache类型的Log
patterns_dir => "/usr/local/wyh/elk-kafka/logstash-6.6.0/custom/patterns" --前面我提供的log数据中的articleid这个字段中包含了数字、字母、下划线、圆点等复杂符号。grok中没有对应的正则,所以需要自定义一个正则。该配置指定了自定义正则所在的路径。(若你的Log中不需要自定义正则,可不添加此配置)
match => { --对log进行正则匹配
"message" => "%{IP:client_address} - - \[%{HTTPDATE:timestamp}\] Second:%{NUMBER:second} \"%{WORD:http_method} %{URIPATHPARAM:url}\?writer=%{WORD:writer}&articleid=%{ARTICLEID:articleid} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_code} %{NUMBER:bytes} \"(?:%{URI:http_referer}|-)\" %{QS:java_version}"
}
remove_field => "message" --上面一行对数据进行了拆分解析,此处就没必要再完整地显示一遍Log信息,所以可以移除掉message这个字段。
}
}
output{
elasticsearch{ --输出到elasticsearch中
hosts => ["192.168.184.128:9200"] --elasticsearch的ip及端口
index => "wyh-apache-log" --输出到哪个index
}
}(配置中不要写注释,因为它不识别,会报错)
上面的%{A:b}中A表示grok提供的已经定义好的正则名称,比如IP会自动匹配到IP格式的信息,NUMBER是匹配数字格式,WORD匹配字符串,QS匹配带引号的字符串。。。冒号后面的b表示将匹配得到的信息以什么字段名展示,这个是自己起的名字。在匹配的时候有些特殊符号是需要在前面加上一个/来转义的。
grok提供的正则默认表达式详细信息:https://cloud.tencent.com/developer/article/1342777
3.3在3.2的配置中提到了自定义正则,patterns_dir是路径。我们在/usr/local/wyh/elk-kafka/logstash-6.6.0下创建目录:custom,在custom下创建文件patterns:
cd /usr/local/wyh/elk-kafka/logstash-6.6.0/custom[root@localhost custom]# vi patterns这里我们要自定义的是articleid字段的正则,所以就根据articleid的特征编辑正则:
[root@localhost custom]# cat patterns
ARTICLEID [a-z]{3}_[a-z]{4}_[0-9]{2}.[0-9]{2}.[0-9]{2}_[0-9]{4}_[0-9]{2}_[0-9]{2}_[0-9]{4}前面的ARTICLEID是自定义的表达式名称,在filter匹配时直接使用这个名称。
如果自定义多个正则,那就换行另写。
3.4启动logstash:
[root@localhost logstash-6.6.0]# ./bin/logstash -f ./config/wyh-apache-log.conf启动过程要稍微等一会儿。。。
![]()
3.5在kibana中创建一个刚才在配置文件中指定的index:
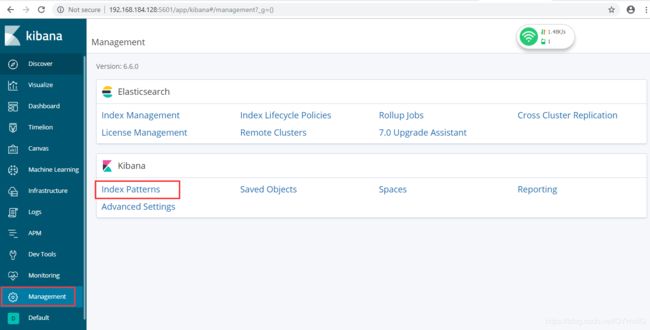
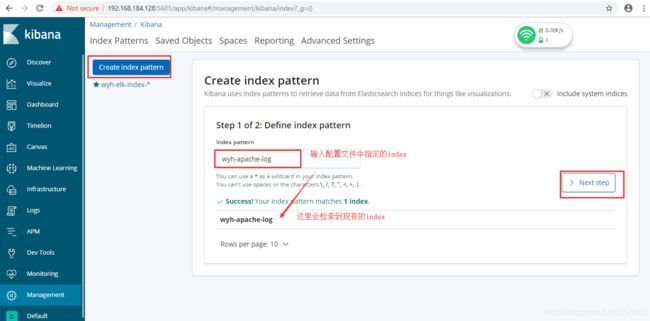
创建好之后查看刚才的log信息:
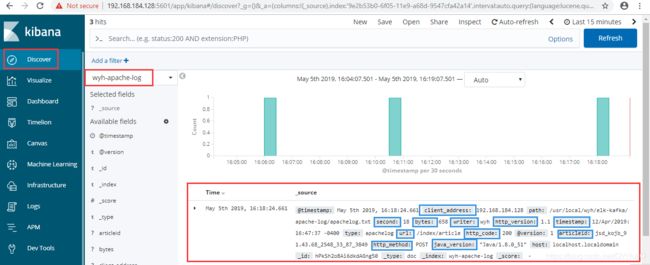
蓝色方框中的就是我们对Log解析之后的每一个属性的值,在elasticsearch中可以对这些属性进行操作分析等。
在测试的过程中可能遇到的问题:
1)如果遇到message没有解析成我们指定的字段,一般就是因为filter中的正则没有匹配对。
2)如果你只修改了logstash的配置,没有修改Log源文件,可能会导致kibana中刷新不出来,可以修改一下源文件中的内容再测试。
以上就完成了logstash对apache日志解析的过程。