数据预处理 01处理
前面机器学习 K-近邻算法(一)博客中值为连续值。我们要进行朴素贝叶斯分类时需要对数据进行离散处理,简单的是进行01处理。
1 首先,惯例pandas读取数据变成DataFrame,查看数据及数据描述。(如需数据请留言,博客没办法上传附件请见谅)
import time
import numpy as np
import pandas as pd
group = pd.read_table('bayes.txt',header=None,usecols = (0,1,3))
print('原始数据\n',group)
print(group.describe())注:这里header设为None,否则会默认把第一行数据当成列标签。usecols=(0,1,3)表示只取bayes.txt数据的第0,1,3行数据。
运行结果:
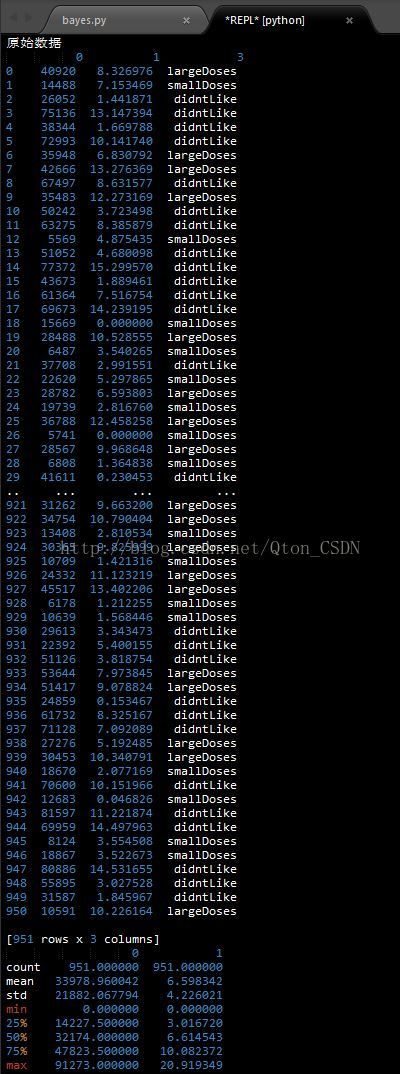
2 对3行标签行进行转换,didntLike转化为值0,smallDoses转化为值1,largeDoses转化为值2.
#标签进行01处理
group = group.replace('didntLike',0)
group = group.replace('smallDoses',1)
group = group.replace('largeDoses',2)3 对0行飞行时间行进行01处理,低于等于样本数据平均飞行时间的转为0,否则为1
# Fly进行01处理
Fly_s = group[0]
Fly_mean = Fly_s.mean()
Fly_s[Fly_s<=Fly_mean] = 0
Fly_s[Fly_s>Fly_mean] = 14 对1行玩游戏时间行进行处理,也是低于平均值为0,否则为1
# Game进行01处理
Game_s = group[1]
Game_mean = Game_s.mean()
Game_s[Game_s<=Game_mean] = 0
Game_s[Game_s>Game_mean] = 15 查看处理后的数据
print('01处理后数据\n',group)
print(group.describe())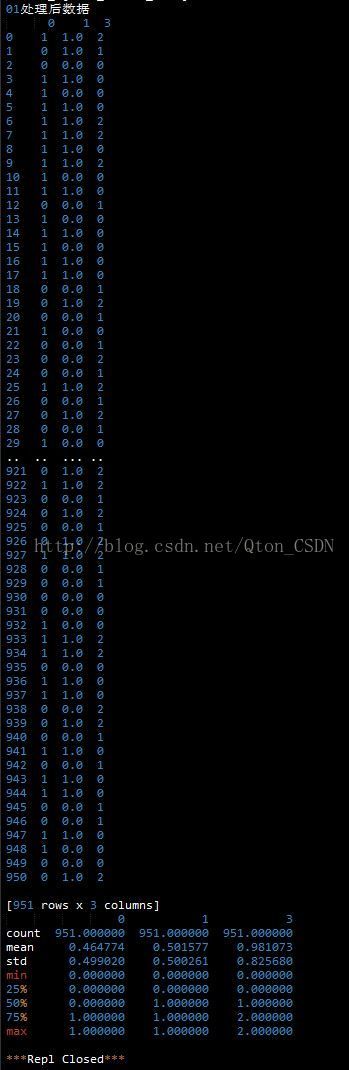
6 查看无问题后写入数据。
group.to_csv('bayes_04.txt',index = None,header=None)注:pandas有to_csv to_excel to_hdf to_json 等函数。此处to_csv也可保存为bayes.csv文件。index设为None,否则会保存一行“行数”行。header设为None,否则第一行会是0 1 3列标签。
详细保存的参数看最后面的附录
全部代码:
import time
import numpy as np
import pandas as pd
group = pd.read_table('bayes.txt',header=None,usecols = (0,1,3))
print('原始数据\n',group)
print(group.describe())
#标签进行01处理
group = group.replace('didntLike',0)
group = group.replace('smallDoses',1)
group = group.replace('largeDoses',2)
# Fly进行01处理
Fly_s = group[0]
Fly_mean = Fly_s.mean()
Fly_s[Fly_s<=Fly_mean] = 0
Fly_s[Fly_s>Fly_mean] = 1
# Game进行01处理
Game_s = group[1]
Game_mean = Game_s.mean()
Game_s[Game_s<=Game_mean] = 0
Game_s[Game_s>Game_mean] = 1
print('01处理后数据\n',group)
print(group.describe())
group.to_csv('bayes_04.txt',index = None,header=None)运行结果:
原始数据
0 1 3
0 40920 8.326976 largeDoses
1 14488 7.153469 smallDoses
2 26052 1.441871 didntLike
3 75136 13.147394 didntLike
4 38344 1.669788 didntLike
5 72993 10.141740 didntLike
6 35948 6.830792 largeDoses
7 42666 13.276369 largeDoses
8 67497 8.631577 didntLike
9 35483 12.273169 largeDoses
10 50242 3.723498 didntLike
11 63275 8.385879 didntLike
12 5569 4.875435 smallDoses
13 51052 4.680098 didntLike
14 77372 15.299570 didntLike
15 43673 1.889461 didntLike
16 61364 7.516754 didntLike
17 69673 14.239195 didntLike
18 15669 0.000000 smallDoses
19 28488 10.528555 largeDoses
20 6487 3.540265 smallDoses
21 37708 2.991551 didntLike
22 22620 5.297865 smallDoses
23 28782 6.593803 largeDoses
24 19739 2.816760 smallDoses
25 36788 12.458258 largeDoses
26 5741 0.000000 smallDoses
27 28567 9.968648 largeDoses
28 6808 1.364838 smallDoses
29 41611 0.230453 didntLike
.. ... ... ...
921 31262 9.663200 largeDoses
922 34754 10.790404 largeDoses
923 13408 2.810534 smallDoses
924 30365 9.825999 largeDoses
925 10709 1.421316 smallDoses
926 24332 11.123219 largeDoses
927 45517 13.402206 largeDoses
928 6178 1.212255 smallDoses
929 10639 1.568446 smallDoses
930 29613 3.343473 didntLike
931 22392 5.400155 didntLike
932 51126 3.818754 didntLike
933 53644 7.973845 largeDoses
934 51417 9.078824 largeDoses
935 24859 0.153467 didntLike
936 61732 8.325167 didntLike
937 71128 7.092089 didntLike
938 27276 5.192485 largeDoses
939 30453 10.340791 largeDoses
940 18670 2.077169 smallDoses
941 70600 10.151966 didntLike
942 12683 0.046826 smallDoses
943 81597 11.221874 didntLike
944 69959 14.497963 didntLike
945 8124 3.554508 smallDoses
946 18867 3.522673 smallDoses
947 80886 14.531655 didntLike
948 55895 3.027528 didntLike
949 31587 1.845967 didntLike
950 10591 10.226164 largeDoses
[951 rows x 3 columns]
0 1
count 951.000000 951.000000
mean 33978.960042 6.598342
std 21882.067794 4.226021
min 0.000000 0.000000
25% 14227.500000 3.016720
50% 32174.000000 6.614543
75% 47823.500000 10.082372
max 91273.000000 20.919349
33978.960042060986
bayes.py:24: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
Fly_s[Fly_s<=Fly_mean] = 0
bayes.py:25: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
Fly_s[Fly_s>Fly_mean] = 1
bayes.py:31: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
Game_s[Game_s<=Game_mean] = 0
bayes.py:32: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
Game_s[Game_s>Game_mean] = 1
01处理后数据
0 1 3
0 1 1.0 2
1 0 1.0 1
2 0 0.0 0
3 1 1.0 0
4 1 0.0 0
5 1 1.0 0
6 1 1.0 2
7 1 1.0 2
8 1 1.0 0
9 1 1.0 2
10 1 0.0 0
11 1 1.0 0
12 0 0.0 1
13 1 0.0 0
14 1 1.0 0
15 1 0.0 0
16 1 1.0 0
17 1 1.0 0
18 0 0.0 1
19 0 1.0 2
20 0 0.0 1
21 1 0.0 0
22 0 0.0 1
23 0 0.0 2
24 0 0.0 1
25 1 1.0 2
26 0 0.0 1
27 0 1.0 2
28 0 0.0 1
29 1 0.0 0
.. .. ... ..
921 0 1.0 2
922 1 1.0 2
923 0 0.0 1
924 0 1.0 2
925 0 0.0 1
926 0 1.0 2
927 1 1.0 2
928 0 0.0 1
929 0 0.0 1
930 0 0.0 0
931 0 0.0 0
932 1 0.0 0
933 1 1.0 2
934 1 1.0 2
935 0 0.0 0
936 1 1.0 0
937 1 1.0 0
938 0 0.0 2
939 0 1.0 2
940 0 0.0 1
941 1 1.0 0
942 0 0.0 1
943 1 1.0 0
944 1 1.0 0
945 0 0.0 1
946 0 0.0 1
947 1 1.0 0
948 1 0.0 0
949 0 0.0 0
950 0 1.0 2
[951 rows x 3 columns]
0 1 3
count 951.000000 951.000000 951.000000
mean 0.464774 0.501577 0.981073
std 0.499020 0.500261 0.825680
min 0.000000 0.000000 0.000000
25% 0.000000 0.000000 0.000000
50% 0.000000 1.000000 1.000000
75% 1.000000 1.000000 2.000000
max 1.000000 1.000000 2.000000
***Repl Closed***
附录:to_csv to_excel to_hdf to_json 等函数参数
如:
group.to_csv('bayes_04.txt',index = None,header=None)
参数
Parameters:
path_or_buf :
string or file handle, default None
File path or object, if None is provided the result is returned as a string.
sep :
character, default ‘,’
Field delimiter for the output file.
na_rep :
string, default ‘’
Missing data representation
float_format :
string, default None
Format string for floating point numbers
columns :
sequence, optional
Columns to write
header :
boolean or list of string, default True
Write out column names. If a list of string is given it is assumed to be aliases for the column names
index :
boolean, default True
Write row names (index)
index_label :
string or sequence, or False, default None
Column label for index column(s) if desired. If None is given, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex. If False do not print fields for index names. Use index_label=False for easier importing in R
mode :
str
Python write mode, default ‘w’
encoding :
string, optional
A string representing the encoding to use in the output file, defaults to ‘ascii’ on Python 2 and ‘utf-8’ on Python 3.
compression :
string, optional
a string representing the compression to use in the output file, allowed values are ‘gzip’, ‘bz2’, ‘xz’, only used when the first argument is a filename
line_terminator :
string, default '\n'
The newline character or character sequence to use in the output file
quoting :
optional constant from csv module
defaults to csv.QUOTE_MINIMAL. If you have set a float_format then floats are comverted to strings and thus csv.QUOTE_NONNUMERIC will treat them as non-numeric
quotechar :
string (length 1), default ‘”’
character used to quote fields
doublequote :
boolean, default True
Control quoting of quotechar inside a field
escapechar :
string (length 1), default None
character used to escape sep and quotechar when appropriate
chunksize :
int or None
rows to write at a time
tupleize_cols :
boolean, default False
write multi_index columns as a list of tuples (if True) or new (expanded format) if False)
date_format :
string, default None
Format string for datetime objects
decimal:
string, default ‘.’
Character recognized as decimal separator. E.g. use ‘,’ for European data
New in version 0.16.0.