Lucene总结(一):认识Lucene以及简单入门实战
前段时间在GitHub克隆了一个SSM的博客的项目,上面用到了Lucene。觉得以后用到的地方可能比较多,于是花了点时间大致了解了一下,总结一下了解的。
什么是Lucene?
Lucene是apache的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
上面是百度百科的简介,简单的说,Lucene是一个开放源代码的全文检索引擎工具包。
数据分类及搜索
使用Lucene之前,先来了解一下数据的分类,一般数据分为两类:
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据(也可称为全文数据):指不定长或无固定格式的数据,如邮件,word文档等。
针对两种不同的数据,也有两种搜索方式:
- 对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
由于Lucene的是非结构化数据,所以讲一下非结构化搜索使用的方法,一般也是两种:
- 顺序扫描法(Serial Scanning):比如你要查一个字符串“spring”,这个方法就是在每一个文档里从头到尾的搜索,无论有没有找到都去下一个文档,找到了就都是我们需要的文档,这种方法非常费时,windows的搜索就是使用这个,这个方法对于文档不多,还是比较好的,但是文档一旦多了,就非常慢。
- 全文检索(Full-text Search):就是先建立一个索引,再对索引进行检索。通常,可以把这个方法想象成字典,你比如查找一个“飞”,肯定是先查找fei这个拼音,再到对应的页数去找这个字,如果没有索引,你就需要使用顺序扫描法,从头到尾的查找字典,直到找到为止。
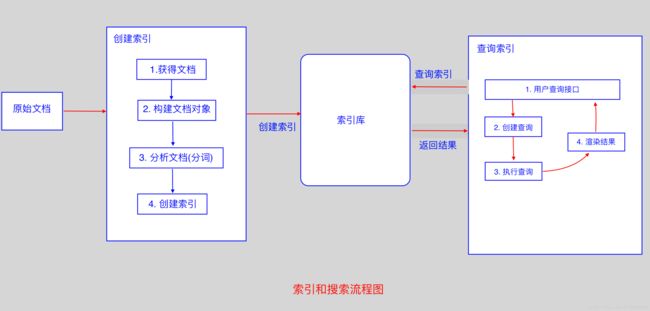
上面就是Lucene 实现全文检索的流程。
全文检索的原理
参考这篇博客。
- 一些要索引的原文档(Document),如:
文档一:Tom lives in Shanghai, I live in Shanghai too.
文档二:My friends are very friendly to me 将原文档传给分词组件(Tokenizer):分词组件(Tokenizer)会做以下几件事情( 此过程称为Tokenize) :
1.将文档分成一个一个单独的单词。
2.去除标点符号。
3.去除停词(Stop word) 。
所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,英语中停词如:“the”,“a”,“this”等。经过分词(Tokenizer) 后得到的结果称为词元(Token) 。
在我们的例子中,得到以下词元(Token):文档一:[Tom] [lives] [Shanghai] [I] [live] [Shanghai]
文档二:[My] [friends] [very] [friendly] [me]将得到的词元(Token)传给语言处理组件(Linguistic Processor):语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。对于英语,语言处理组件(Linguistic Processor) 一般做以下几点:
- 变为小写(Lowercase) 。
- 将单词缩减为词根形式,如“cars ”到“car ”等。这种操作称为:stemming 。
- 将单词转变为词根形式,如“drove ”到“drive ”等。这种操作称为:lemmatization 语言处理组件(linguistic processor)的结果称为词(Term) 。在我们的例子中,经过语言处理,得到的词(Term)如下:
文档一:[tom] [live] [shanghai] [i] [live] [shanghai]
文档二:[my] [friend] [very] [friendly] [me]
最后,将得到的词(Term)传给索引组件(Indexer),索引组件(Indexer)主要做以下几件事情:
- 利用得到的词(Term)创建一个字典。
- 对字典按字母顺序进行排序。
- 合并相同的词(Term) 成为文档倒排(Posting List) 链表。
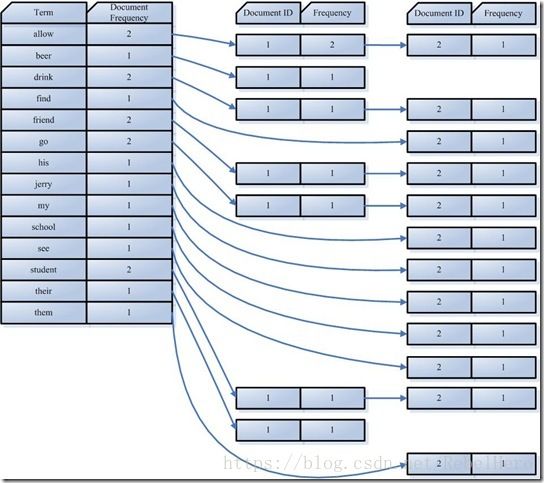
这个是那篇博客上的,不是我给的例子上的。但是我觉得这个图能加深理解。 - Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)。
在这幅图中,对词(Term) “allow”来讲,总共有两篇文档包含此词(Term),从而词(Term)后面的文档链表总共有两项,第一项表示包含“allow”的第一篇文档,即1号文档,此文档中,“allow”出现了2次,第二项表示包含“allow”的第二个文档,是2号文档,此文档中,“allow”出现了1次。
以上就是全文检索使用的原理。Lucene也就是使用这个。
Lucene常用包和类
可以通过查看官方文档来了解各个包的使用,这里我借用了别人对于包的介绍。
包介绍:
- Lucene-core.jar,核心包,包括了常用的文档,索引,搜索,存储等相关核心代码。
- Lucene-analyzers-common.jar,这里面包含了各种语言的词法分析器,用于对文件内容进行关键字切分,提取。
- Lucene-highlighter.jar,这个jar包主要用于搜索出的内容高亮显示。
- Lucene-queryparser.jar,提供了搜索相关的代码,用于各种搜索,比如模糊搜索,范围搜索,等等。
Lucene常用类
借用了这个博客的内容,因为解释的比较详细,且对于每个类需要的都说的很清楚。
- IndexWriter,索引过程的核心组件。这个类负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新索引文档的信息。可以把IndexWriter看做这样一个对象:提供针对索引文件的写入操作,但不能用于读取或搜索索引。IndexWriter需要开辟一定空间来存储索引,该功能可以由Directory完成。
- Diretory 索引存放的位置,它是一个抽象类,它的子类负责具体制定索引的存储路径。lucene提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene提供了FSDirectory和RAMDirectory两个类。
- Analyzer 分析器,主要用于分析搜索引擎遇到的各种文本,Analyzer的工作是一个复杂的过程:把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语(停用词),这里说的无效词语如英文中的“of”、“the”,中文中的“的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。分词的规则千变万化,但目的只有一个:按语义划分。这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。具体划分方法下面再详细介绍,这里只需了解分析器的概念即可。
- Document 文档 ,Document相当于一个要进行索引的单元,可以是文本文件、字符串或者数据库表的一条记录等等,一条记录经过索引之后,就是以一个Document的形式存储在索引文件,索引的文件都必须转化为Document对象才能进行索引。
Field 一个Document可以包含多个信息域,比如一篇文章可以包含“标题”、“正文”等信息域,这些信息域就是通过Field在Document中存储的。
是否分析: 是否对域的内容进行分词处理;
是否索引: 将 Field 分析后的词或整个 Field 值进行索引,只有建立索引,才能搜索到;
是否存储: 存储在文档中的 Field 才可以从 Document 中获取;
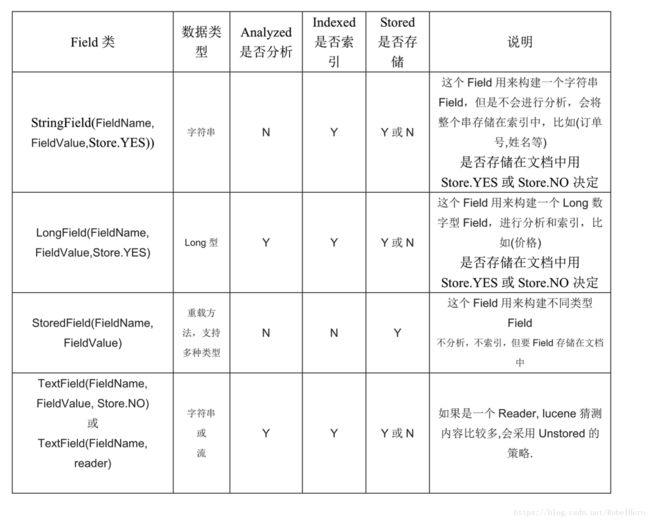
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,假设有一篇文章,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为true,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域的存储属性设置为true,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为false,当需要时再直接读取文件;我们只是希望能从搜索结果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为true,索引属性设置为false。上面的三个域涵盖了两个属性的三种组合,还有一种全为false的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。
IndexSearcher 是lucene中最基本的检索工具,所有的检索都会用到IndexSearcher工具。
- IndexReader 打开一个Directory读取索引类。
- Query 查询,抽象类,必须通过一系列子类来表述检索的具体需求,lucene中支持模糊查询,语义查询,短语查询,组合查询等,有TermQuery,BooleanQuery,RangeQuery,WildcardQuery等一些类。
- QueryParser 解析用户的查询字符串进行搜索,是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
- TopDocs 根据关键字搜索整个索引库,然后对所有结果进行排序,取指定条目的结果。
- TokenStream Token 分词器Analyzer通过对文本的分析来建立TokenStreams(分词数据流)。TokenStream是由一个个Token(分词组成的数据流)。所以说Analyzer就代表着一个从文本数据中抽取索引词(Term)的一种策略。
- AttributeSource TokenStream即是从Document的域(field)中或者查询条件中抽取一个个分词而组成的一个数据流。TokenSteam中是一个个的分词,而每个分词又是由一个个的属性(Attribute)组成。对于所有的分词来说,每个属性只有一个实例。这些属性都保存在AttributeSource中,而AttributeSource正是TokenStream的父类。
Lucene创建索引流程
一般是:
- 创建一个索引库Directory ,即是索引存放的位置。
- 创建一个分词器Analyzer ,创建IndexWriter实例时,通过IndexWriterConfig来设置其相关配置,一般构造函数的参数是分词器对象。
- 创建一个IndexWriter对象,构造函数参数是Directory 对象和IndexWriterConfig对象。
- 提取原始文档,为原始文档创建document以及对应的field,将field添加到document中。
- 将document对象添加到IndexWriter对象中。
下面给出代码,首先使用maven导入所需要的jar包。
<dependencies>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>5.3.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>5.3.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-commonartifactId>
<version>5.3.1version>
dependency>
dependencies>下面是代码:
public class IndexingTest1 {
private Directory dir; //存放索引的位置
//准备用来测试的数据
private String ids[] = {"1", "2", "3"}; //用来标识文档
private String dates[] = {"yesterday", "today", "tomorrow"};
private String descs[] = {
"It was a rainy day yesterday",
"It's cloudy today",
"Tomorrow is sunny."};
//生成索引
@Test
public void index() throws Exception{
IndexWriter writer = getWriter();
for(int i = 0; i < ids.length; i++){
Document document = new Document();
document.add(new StringField("id", ids[i], Field.Store.YES));
document.add(new StringField("date", dates[i], Field.Store.YES));
document.add(new TextField("desc", descs[i], Field.Store.YES));
writer.addDocument(document);
}
writer.close(); //close了才真正写到文档中
}
//获取IndexWriter实例
public IndexWriter getWriter() throws Exception{
dir = FSDirectory.open(Paths.get("D:\\resource"));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(dir,config);
return writer;
}
}可以看见文件夹下生成了如下索引文件:
以上是,认识Lucene以及简单创建索引的过程。
希望对你有帮助,如有疑问或见解,欢迎提出,共同进步。