车牌识别中的不分割字符的端到端(End-to-End)识别
传统的车牌识别过程是往往是这样的
车牌定位->车牌判断->车牌字符的分割->车牌字符的识别
这种方法有个好处就是,仅仅需要较少的字符样本即可用于分类器的训练。在光照,相机条件好的情况下也能取得较好的效果。现在大多数商业车牌识别软件采用的也是这种方法。
但是在某些恶劣的自然情况下,车牌字符的分割和识别变得尤其的困难,传统的方法并不能取得很好的结果。这时候我们就能考虑下是否能整体一起识别。
当然我们注意到车牌字符的数量是固定的,对于中国车牌而言,车牌一直是7个字符。我们就可以采用多标签分类的方法直接输出多个标签。

我们注意到车牌的省份一共有31个、大写字母有24个(去除O和I)、数字有10个。那么一个label就有65个类。
但是这种方法有个很大的缺点,就是需要大量的样本,样本需要涵盖所有的省份和地区。这就为样本的收集造成的极大的困难。
这里为了方便起见我使用OpenCV和车牌的字体来自动生成和渲染有污迹、噪声、畸变的车牌,用来模拟在现实场景中的车牌(当然里现实车牌样本还是有点差距,懂图形学的朋友看看是否可以用游戏引擎之类之类的创建更好的材质和光照)。
渲染出来的车牌样张










用于生成车牌的代码
index = {"京": 0, "沪": 1, "津": 2, "渝": 3, "冀": 4, "晋": 5, "蒙": 6, "辽": 7, "吉": 8, "黑": 9, "苏": 10, "浙": 11, "皖": 12,
"闽": 13, "赣": 14, "鲁": 15, "豫": 16, "鄂": 17, "湘": 18, "粤": 19, "桂": 20, "琼": 21, "川": 22, "贵": 23, "云": 24,
"藏": 25, "陕": 26, "甘": 27, "青": 28, "宁": 29, "新": 30, "0": 31, "1": 32, "2": 33, "3": 34, "4": 35, "5": 36,
"6": 37, "7": 38, "8": 39, "9": 40, "A": 41, "B": 42, "C": 43, "D": 44, "E": 45, "F": 46, "G": 47, "H": 48,
"J": 49, "K": 50, "L": 51, "M": 52, "N": 53, "P": 54, "Q": 55, "R": 56, "S": 57, "T": 58, "U": 59, "V": 60,
"W": 61, "X": 62, "Y": 63, "Z": 64};
chars = ["京", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "皖", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂",
"琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A",
"B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X",
"Y", "Z"
];
def AddSmudginess(img, Smu):
rows = r(Smu.shape[0] - 50)
cols = r(Smu.shape[1] - 50)
adder = Smu[rows:rows + 50, cols:cols + 50];
adder = cv2.resize(adder, (50, 50));
# adder = cv2.bitwise_not(adder)
img = cv2.resize(img,(50,50))
img = cv2.bitwise_not(img)
img = cv2.bitwise_and(adder, img)
img = cv2.bitwise_not(img)
return img
def rot(img,angel,shape,max_angel):
"""
添加仿射畸变
"""
size_o = [shape[1],shape[0]]
size = (shape[1]+ int(shape[0]*cos((float(max_angel )/180) * 3.14)),shape[0])
interval = abs( int( sin((float(angel) /180) * 3.14)* shape[0]));
pts1 = np.float32([[0,0] ,[0,size_o[1]],[size_o[0],0],[size_o[0],size_o[1]]])
if(angel>0):
pts2 = np.float32([[interval,0],[0,size[1] ],[size[0],0 ],[size[0]-interval,size_o[1]]])
else:
pts2 = np.float32([[0,0],[interval,size[1] ],[size[0]-interval,0 ],[size[0],size_o[1]]])
M = cv2.getPerspectiveTransform(pts1,pts2);
dst = cv2.warpPerspective(img,M,size);
return dst;
def rotRandrom(img, factor, size):
#添加透视畸变
shape = size;
pts1 = np.float32([[0, 0], [0, shape[0]], [shape[1], 0], [shape[1], shape[0]]])
pts2 = np.float32([[r(factor), r(factor)], [ r(factor), shape[0] - r(factor)], [shape[1] - r(factor), r(factor)],
[shape[1] - r(factor), shape[0] - r(factor)]])
M = cv2.getPerspectiveTransform(pts1, pts2);
dst = cv2.warpPerspective(img, M, size);
return dst;
def tfactor(img):
#增加饱和度光照的噪声
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV);
hsv[:,:,0] = hsv[:,:,0]*(0.8+ np.random.random()*0.2);
hsv[:,:,1] = hsv[:,:,1]*(0.3+ np.random.random()*0.7);
hsv[:,:,2] = hsv[:,:,2]*(0.2+ np.random.random()*0.8);
img = cv2.cvtColor(hsv,cv2.COLOR_HSV2BGR);
return img
def random_envirment(img,data_set):
#添加自然环境的噪声
index=r(len(data_set))
env = cv2.imread(data_set[index])
env = cv2.resize(env,(img.shape[1],img.shape[0]))
bak = (img==0);
bak = bak.astype(np.uint8)*255;
inv = cv2.bitwise_and(bak,env)
img = cv2.bitwise_or(inv,img)
return img
def GenCh(f,val):
#生成中文字符
img=Image.new("RGB", (45,70),(255,255,255))
draw = ImageDraw.Draw(img)
draw.text((0, 3),val,(0,0,0),font=f)
img = img.resize((23,70))
A = np.array(img)
return A
def GenCh1(f,val):
#生成英文字符
img=Image.new("RGB", (23,70),(255,255,255))
draw = ImageDraw.Draw(img)
draw.text((0, 2),val.decode('utf-8'),(0,0,0),font=f)
A = np.array(img)
return A
def AddGauss(img, level):
#添加高斯模糊
return cv2.blur(img, (level * 2 + 1, level * 2 + 1));
def r(val):
return int(np.random.random() * val)
def AddNoiseSingleChannel(single):
#添加高斯噪声
diff = 255-single.max();
noise = np.random.normal(0,1+r(6),single.shape);
noise = (noise - noise.min())/(noise.max()-noise.min())
noise= diff*noise;
noise= noise.astype(np.uint8)
dst = single + noise
return dst
def addNoise(img,sdev = 0.5,avg=10):
img[:,:,0] = AddNoiseSingleChannel(img[:,:,0]);
img[:,:,1] = AddNoiseSingleChannel(img[:,:,1]);
img[:,:,2] = AddNoiseSingleChannel(img[:,:,2]);
return img;
class GenPlate:
def __init__(self,fontCh,fontEng,NoPlates):
self.fontC = ImageFont.truetype(fontCh,43,0);
self.fontE = ImageFont.truetype(fontEng,60,0);
self.img=np.array(Image.new("RGB", (226,70),(255,255,255)))
self.bg = cv2.resize(cv2.imread("./images/template.bmp"),(226,70));
self.smu = cv2.imread("./images/smu2.jpg");
self.noplates_path = [];
for parent,parent_folder,filenames in os.walk(NoPlates):
for filename in filenames:
path = parent+"/"+filename;
self.noplates_path.append(path);
def draw(self,val):
offset= 2 ;
self.img[0:70,offset+8:offset+8+23]= GenCh(self.fontC,val[0]);
self.img[0:70,offset+8+23+6:offset+8+23+6+23]= GenCh1(self.fontE,val[1]);
for i in range(5):
base = offset+8+23+6+23+17 +i*23 + i*6 ;
self.img[0:70, base : base+23]= GenCh1(self.fontE,val[i+2]);
return self.img
def generate(self,text):
if len(text) == 9:
fg = self.draw(text.decode(encoding="utf-8"));
fg = cv2.bitwise_not(fg);
com = cv2.bitwise_or(fg,self.bg);
com = rot(com,r(60)-30,com.shape,30);
com = rotRandrom(com,10,(com.shape[1],com.shape[0]));
#com = AddSmudginess(com,self.smu)
com = tfactor(com)
com = random_envirment(com,self.noplates_path);
com = AddGauss(com, 1+r(4));
com = addNoise(com);
return com
def genPlateString(self,pos,val):
plateStr = "";
box = [0,0,0,0,0,0,0];
if(pos!=-1):
box[pos]=1;
for unit,cpos in zip(box,xrange(len(box))):
if unit == 1:
plateStr += val
else:
if cpos == 0:
plateStr += chars[r(31)]
elif cpos == 1:
plateStr += chars[41+r(24)]
else:
plateStr += chars[31 + r(34)]
return plateStr;
def genBatch(self, batchSize,pos,charRange, outputPath,size):
if (not os.path.exists(outputPath)):
os.mkdir(outputPath)
for i in xrange(batchSize):
plateStr = G.genPlateString(-1,-1)
img = G.generate(plateStr);
img = cv2.resize(img,size);
cv2.imwrite(outputPath + "/" + str(i).zfill(2) + ".jpg", img);
G = GenPlate("./font/platech.ttf",'./font/platechar.ttf',"./NoPlates")
G.genBatch(100,2,range(31,65),"./plate",(272,72))这里使用mxnet从xlvector的ocr代码修改了成了输出65类 7 个softmax。
由于我没有GPU。在MBP下 以 9 samples/s 的速度,训练了15个小时最终收敛到81%左右。

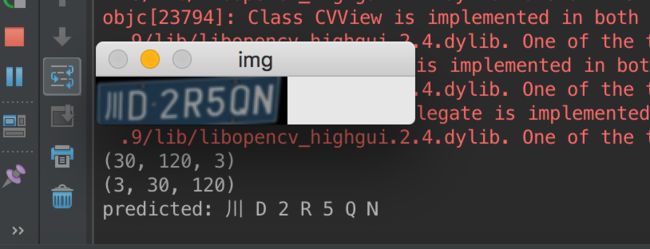

整个代码在我的github
https://github.com/szad670401/end-to-end-for-chinese-plate-recognition